

Apple Keynote推出iPhone X和FaceID
描述
最近大家谈论最多的关于新款iPhone X的功能之一就是新的解锁技术,即TouchID的后续技术:FaceID。
创建了无边框手机后,苹果不得不找出新方法简单快捷地解锁手机。虽然一些竞争对手继续使用放在不同位置的指纹传感器,但苹果决定对解锁手机的方式进行创新和变革:只需看一眼,FaceID就能安全地解锁iPhone X。借助一款先进(而且非常小巧)的前置深度相机,iPhone X可以建立用户脸部的3D模型。此外,iPhone X通过红外摄像头识别人脸,可以避免环境光和颜色对人脸识别的影响。通过深度学习,手机可以捕捉到用户脸部的很多细节,因此在用户拿着手机的时候,手机可以识别出它的主人。比较令人惊讶的是,苹果表示这种方法比TouchID更安全,出错率为百万分之一。
我对苹果的FaceID的实现技术非常感兴趣,特别是它完全运行在设备上,而且只需利用用户的面部进行一点点训练,就可以在每次拿起手机的时候顺利地进行识别。我研究了如何使用深度学习来实现此过程,以及如何优化每个步骤。在这篇文章中,我将展示如何使用Keras实现一个类似FaceID的算法。我会介绍采用的各种架构,并展示一些在Kinect(一种非常流行的RGB-D相机,拥有与iPhone X前置摄像头非常相似的输出,但设备本身更大)上的最终实验。倒杯咖啡,让我们开始逆向工程苹果的新技术。
对FaceID的初步了解
“……赋予FaceID力量的神经网络不是简单的分类。”
FaceID注册的过程
第一步我们来仔细分析FaceID在iPhone X上的工作原理。我们可以通过苹果的白皮书理解FaceID的基本机制。使用TouchID的时候,用户必须多次按传感器来注册自己的指纹。大约需要15-20次不同的触摸,iPhone才能完成注册,并准备好TouchID。同样地,FaceID也需要用户进行脸部注册。过程非常简单:用户只需像往常一样看着手机,然后慢慢地转动头部一圈,从不同的角度注册脸部。如此,注册过程就完成了,手机已经准备好解锁了。这个超快的注册过程可以告诉我们很多关于底层学习算法的信息。比如,FaceID背后的神经网络并不是简单的分类。我会在后面进行详细的解释。
Apple Keynote推出iPhone X和FaceID
对于神经网络来说,分类的意思是学习如何预测看到的脸是不是用户的脸。所以,它需要一些训练数据来预测“是”或“否”,但与很多其他深度学习的应用场景不同,所以这种方式在这里并不适用。首先,神经网络需要使用从用户脸上捕捉到的数据重新进行训练。而这需要消耗大量的时间和电量,还需要大量的不同面孔作为训练数据以获得负面的样本,这也是不现实的。即使是试图迁移并微调已经训练好的神经网络,这些条件也几乎不会变化。而且,苹果也不可能在实验室等地方“线下”训练复杂的神经网络,然后再将训练好的神经网络搭载在手机中。相反,我认为FaceID是由孪生卷积神经网络实现的(siamese-like convolutional neural network),该网络由苹果公司进行“线下”培训,将脸部映射到一个低维潜在空间(latent space),并通过对比损失函数(contrastive loss)最大化不同人脸之间的距离。通过本文,你可以了解Keynote中提到的体系结构。我知道,很多读者对上述名词很陌生,但是没关系,我会逐步的进行详细的解释。
FaceID看起来会是TouchID之后的新标准。苹果是否会把它带到所有的新设备上?
从人脸到神经网络的数字


Hadsell,Chopra和LeCun发表的论文“Dimensionality Reduction by Learning an Invariant Mapping”。请注意此架构是如何学习数字之间的相似性,并自动将它们分组在二维中。类似的技术也可以应用于面部识别。

FaceID可以适应外观的变化
接下来,让我们看看如何利用Python和Keras实现。
使用Keras实现FaceID
就像所有的机器学习项目一样,我们首先需要的是数据。创建自己的数据集需要花费大量时间和许多人的配合,这项工作本身可能非常具有挑战性。因此,我搜索了网络上RGB-D的人脸数据集,找到了一个非常合适的数据集(http://www.vap.aau.dk/rgb-d-face-database/)。这个数据集是根据人脸面向不同的方向以及不同的表情制作出的RGB-D图像集,正好类似于iPhone X的情况。
最终的实现可以参考我的GitHub代码库(https://github.com/normandipalo/faceID_beta),里面有个Jupyter Notebook。我还进一步尝试了使用Colab Notebook,你也可以试试看。
我创建了一个基于SqueezeNet架构的卷积网络。这个神经网络以两组RGBD的面部图像(即4通道图像)作为输入,并输出两组数据之间的距离。该网络用对比损失函数(constrastive loss)训练,可以最大程度地减少同一人的照片之间的距离,同时最大程度地提高不同人的照片之间的距离。
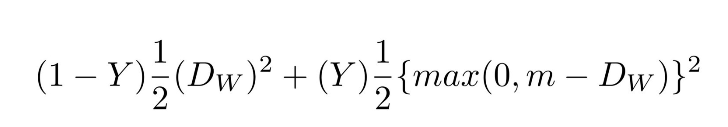
对比损失函数

使用t-SNE创建嵌入空间中的人脸的簇,每种颜色代表不同的面孔(但颜色被重复使用)
使用PCA创建嵌入空间中的人脸的簇,每种颜色都是不同的面孔(但颜色被重复使用)
实验!
现在我们可以试试个模型,模拟一个常见的FaceID的流程:首先,注册用户的面部;然后在解锁阶段,需要验证两个方面——主人可以解锁,而其他人不可以。 如前所述,区别在于神经网络会计算解锁手机时和注册时的脸部的距离,然后判断是否在某个阈值以下。
下面我们来注册:我从数据集中采集了同一人的一系列照片,并模拟了注册阶段。现在该设备将计算每个姿势的嵌入,并保存在本地。
新用户注册阶段,模仿FaceID的过程
在深度相机中观察到的注册阶段
嵌入空间中同一个用户的面部距离
嵌入空间中不同用户的面部距离
因此,我们可以将阈值设置为大约0.4,就可以阻止陌生人解锁设备了。
结论
在这篇文章中,我展示了如何利用面部嵌入和孪生卷积神经网络,实现FaceID解锁机制的原型。希望对你能有所帮助。如果你有任何问题都可以和我联系。你可以从以下链接找到所有相关的Python代码:
-
Apple Watch“又丑又无趣”???2014-09-10 2962
-
IPHONE X/IPHONE 8支持无线充电了2017-09-19 5499
-
苹果:iPhone XR每天销售都胜Xs和Xs Max2018-11-29 4746
-
iPhone XS/XS Max拆解有什么区别?2019-08-07 9948
-
【微信精选】小米员工457人瓜分3亿港元;特斯拉撞上消防车;苹果发布会还可能推出Apple TV...2019-09-16 3268
-
开启Apple Watch充电提示功能2021-09-14 5499
-
KeyNote系统实现分布式环境下的授权2009-06-20 617
-
iPhone X最热门功能之一就是新的解锁方法:FaceID2018-03-20 7430
-
三星生物识别摄像头专利过审,与苹果FaceID极度相似2018-07-10 4884
-
新iPhone如何命名,iPhone9彻底没了?2018-08-06 2174
-
新iPhone不支持Apple Pencil,全系搭配刘海屏与人脸识别2018-09-03 5863
-
Apple在明年下半年可能推出5G版iPhone2019-04-09 748
-
Apple Keynote会带来什么期望2020-09-17 1766
-
苹果新专利:Apple Glass或自动解锁iPhone2021-01-14 2348
-
iPhone17Pro系列才有屏下FaceID2023-03-10 31589
全部0条评论

快来发表一下你的评论吧 !
