

一种实时多线程VSLAM框架vS-Graphs介绍
描述
针对现有VSLAM系统语义表达不足、地图可解释性差的问题,本文提出vS-Graphs,一种实时多线程VSLAM框架。该方案显著提升了重建地图的语义丰富度、可解释性及定位精度。实验表明,vSGraphs优于当前最先进的VSLAM方法,在真实数据上平均降低3.38%的轨迹误差,最大降幅达9.58%。同时,所提出的框架还具有良好的可扩展性,能够处理大规模场景。此外,仅通过视觉特征,本框架实现的语义实体检测精度即可媲美基于激光雷达的精密框架,表现出优秀的环境驱动型语义感知能力。
• 文章:
vS-Graphs: Integrating Visual SLAM and Situational Graphs through Multi-level Scene Understanding
• 作者:
Ali Tourani, Saad Ejaz, Hriday Bavle, David Morilla-Cabello, Jose Luis Sanchez-Lopez, Holger Voos
• 论文链接:
https://arxiv.org/abs/2503.01783
• 编译:
INDEMIND
01 本文核心内容
在SLAM的研究背景下,强大的环境理解作为机器人情境感知的核心基础,高度依赖传感器数据的质量和类型。虽然在SLAM中已采用了各种传感模式(例如激光雷达和相机),但视觉传感器提供了一种经济高效的解决方案,以确保丰富的地图重建,形成了VSLAM专门类别。在视觉传感器中,RGB-D相机提供了视觉和深度信息的丰富融合。这类传感器解决了单目相机和激光雷达的局限性,生成密集的点云,以提供详细的环境元素的空间信息、精确检测、定位和建图。为了增强VSLAM的能力,计算机视觉技术被整合进来,从语义场景理解算法到引入像ArUco标记这样的人工地标。
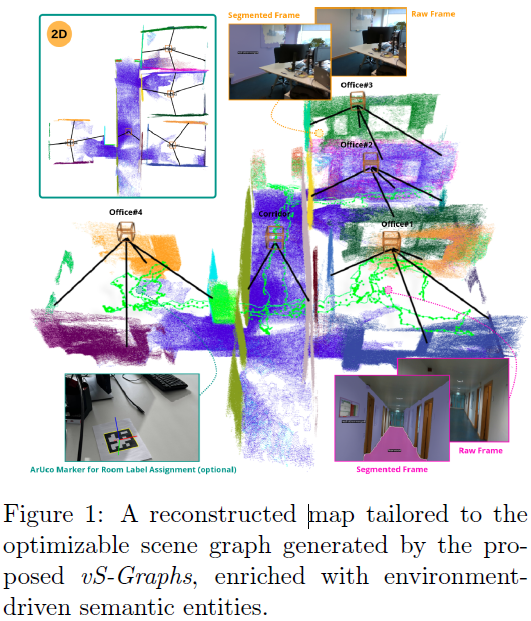
除了利用视觉和深度数据丰富地图之外,还可以采用各种方法将数据组织成易于理解的结构。其中,场景图是结构化的表示形式,用于描述场景中的对象及其关系。通过将场景图与VSLAM相结合,可以实现对环境的更高级理解,包括对象识别、关系推理和场景分类。这种结合不仅提高了地图的质量,还增强了机器人在复杂环境中的导航和交互能力。扫描环境记录了“物体”的存在、其属性以及相互关系。它们为场景理解提供了更高层次的抽象,生成分层(即基于图的)环境表示,概述了观察到的物体之间的空间关联。虽然有的方法侧重于为可靠的环境解释量身定制几何和语义信息,但像S-Graphs这样的其他工作则通过将场景图直接纳入SLAM来突破界限。S-Graphs在统一的优化系统中使用激光雷达里程计和平面表面提取,而Hydra则从给定的传感器数据(即相机姿态和点云)实时构建3D场景图。
受S-Graphs的启发,本文提出了一种实时VSLAM框架,名为视觉S-Graphs(vS-Graphs),它将场景图生成直接集成到SLAM过程中。vS-Graphs是一个实时系统,利用视觉和深度数据来增强地图重建和相机姿态估计。它可靠地整合了“建筑组件”(即墙壁和地面表面)、“结构元素”(即门、窗和柱子)以及“物体”(即家具和装饰品)的信息,从而实现更精确的场景理解和地图构建。vS-Graphs将检测到的房间和走廊及其关联关系整合到重建的地图中,以获得更精确和结构化的环境表示。因此,它利用检测到的建筑组件作为较低层级的、由环境驱动的语义实体来识别潜在的结构元素,从而通过施加额外的语义约束来提高VSLAM系统的精度。最终,vS-Graphs生成具有分层优化能力的可理解的3D场景图,将底层SLAM的机器人姿态与检测到的实体相匹配,如图1所示。它还可以利用(如果存在的话)基准标记,将元数据添加到检测到的结构元素中。
本文的贡献可概括为:
• 一种实时多线程的VSLAM框架,在重建地图的同时生成分层可优化的3D场景图。
• 一种基于视觉的识别和绘制建筑组件(即墙壁和地面表面)的方法,丰富了地图内容并减少了轨迹误差。
• 一种从局部建筑组件中提取高级结构元素(例如房间和走廊)的解决方案,以提高场景理解能力。
02 方法架构
在ORB-SLAM3的基础上,vS-Graphs对其核心模块进行了重大修改,并添加了新的线程以实现稳健的场景分析和重建。如图2所示的系统架构详细说明了各个线程、组件及其相互连接。当前版本支持RGB-D输入,利用深度数据实现稳健的场景理解。其核心贡献在于无缝集成两个新颖的线程:“建筑组件识别”和“结构元素识别”。这两个线程在vS-Graphs中紧密集成,由其他线程触发,以丰富重建的地图并实现最佳性能。
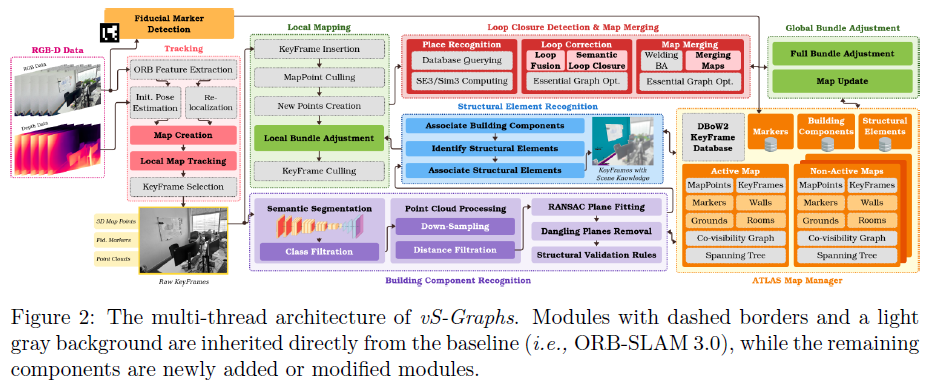
在核心部分,RGB-D数据实时处理,提供视觉和深度信息。同时,“基准标记检测”(本研究中使用ArUco库)独立运行于输入帧上,检测潜在的标记,并将其唯一标识符和姿态存储在地图管理器Atlas中。在“跟踪”线程中,从连续帧中提取并跟踪视觉特征。在此线程中,姿态信息要么被初始化,要么被优化。根据地图重建阶段,创建包含跨帧跟踪特征的3D地图。最后,关键帧选择这一关键步骤在特征提取之后通过分析视觉数据来执行。这些关键帧包含3D地图点、点云以及可能检测到的基准标记,为后续处理奠定基础。关键帧随后被发送到“局部映射”线程进行地图整合和优化,剔除定位不准确的关键帧以提高精度。同时,“建筑组件识别”线程通过处理关键帧级别的点云来识别和定位墙壁和地面表面。“结构元素识别”线程则以固定的时间间隔运行,从活动地图中提取更高层次的实体,包括房间和走廊。最终,由于“闭环检测”,如果当前位置已被重新访问,系统会校正或合并地图,并在检测到闭环时触发“全局束调整”以优化地图。
03 实验结果
1. 评估标准
评估是在配备英特尔i9-11950H处理器(2.60GHz)、4GBNVIDIAT600移动GPU和32GB内存的系统上进行。vS-Graphs通过标准基准测试(真实和逼真)以及内部专有数据集进行了评估。内部数据是使用一种名为AutoSense的定制手持/机器人可安装设备收集的,该设备可同时记录RGB-D视频和激光雷达点云。收集的AutoSense数据集包含各种真实世界室内环境的序列,其建筑布局各不相同,如图4所示。在一些房间中战略性地放置了ArUco标准标记,以增强语义信息(即房间标签)。此外,数据集中的地面实况数据是通过S-Graphs生成的可靠激光雷达姿态和点云获得的。由于篇幅限制,完整的评估结果和图表可在https://snt-arg.github.io/vsgraphs-results/查看。

2. 轨迹估计与建图性能
为了展示vS-Graphs的轨迹估计精度,将其与ORBSLAM3(基准)、ElasticFusion以及BADSLAM进行了比较,因为它们在视觉同步定位与建图(VSLAM)领域具有较强的鲁棒性和广泛的应用。由于标记依赖型和神经场SLAM方法使用外部姿态约束并需要特征标记来整合语义实体,这限制了它们在无标记数据实例中的适用性,因此未将其纳入评估。此外,神经RGB-D方法依赖于其学习到的场景先验知识和隐式表示,与所提出的映射策略不同。表1展示了评估结果,每个系统在数据集实例上进行了八次运行评估,性能通过绝对轨迹误差(ATE)以米为单位进行衡量。表1中的破折号表示由于跟踪失败而无法获取的数据。
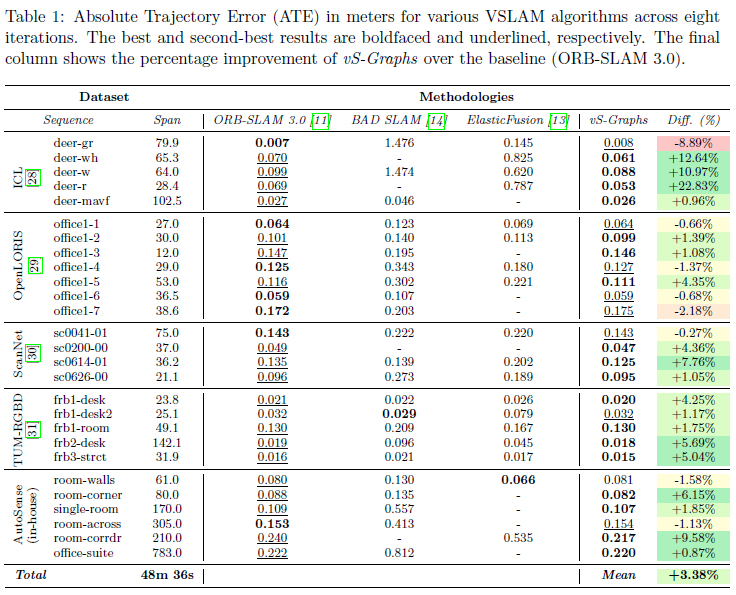
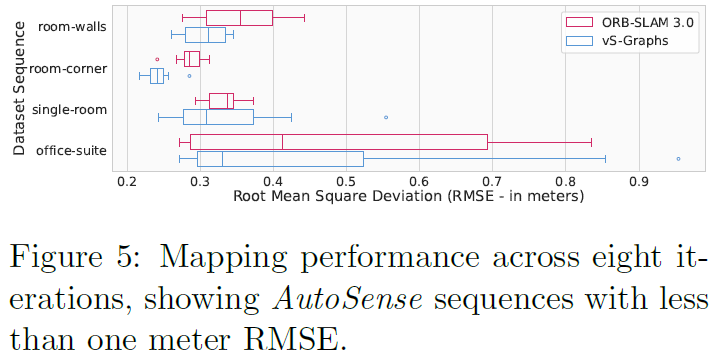
根据评估结果,vS-Graphs一直保持着最先进的性能,在几乎所有情况下都取得了最佳或次佳的结果。这种卓越的性能在较长的轨迹中尤为明显,真实世界的序列源自于整合从精确定位的建筑组件和结构元素中得出的约束条件。虽然纳入这些实体能够增强轨迹估计,但对其不准确的映射和定位可能会对结果产生负面影响。这种情况主要与快速的相机运动(序列deer-gr)和有噪声的点云数据(序列office1-7)有关。平均而言,vS-Graphs在所有序列中比基准方法提高了3.38%。此外,通过将重建地图的精度与AutoSense的真实数据进行对比分析发现,vS-Graphs在均方根误差(RMSE)方面比ORB-SLAM3表现得更为稳健。如图5所示,vS-Graphs的中位RMSE始终更低,表明其整体映射精度更高。尽管vS-Graphs生成的地图平均点数比基准方法少约10.15%,但它仍实现了更优的映射精度,这得益于其环境驱动的约束条件,使得重建更加连贯。
3. 场景理解性能
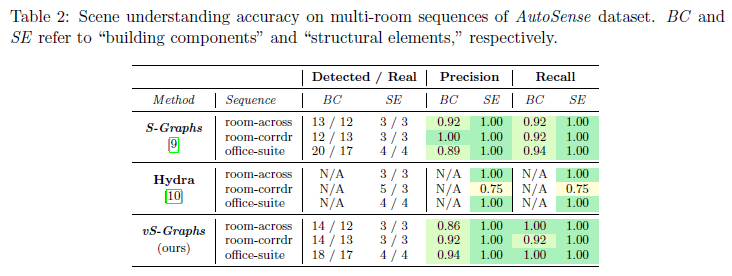
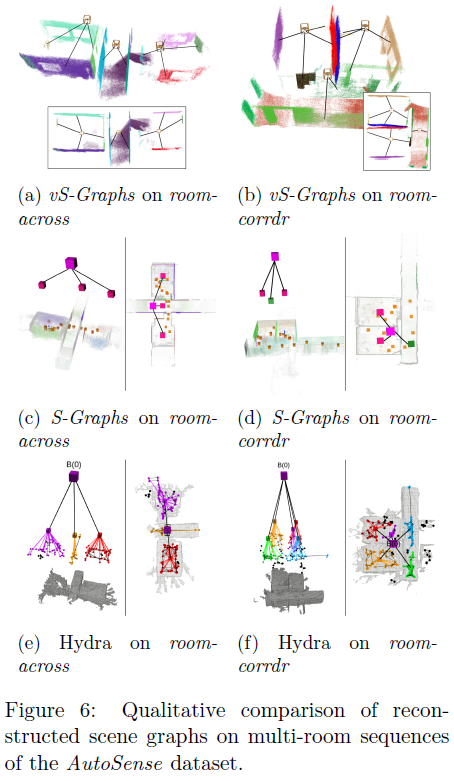
本节评估了vSGraphs在语义场景理解方面的性能,能够准确检测出解读环境布局所必需的关键实体。为了对这一能力进行基准测试,使用了AutoSense数据集中包含多个房间的序列,因为它们提供了基于LiDAR数据的真实标注。表2对vS-Graphs与两种最先进的方法进行了定量比较:Hydra和S-Graphs。尽管S-Graphs受益于LiDAR点云的几何精度,但Hydra被配置为使用视觉点云,以确保与我们纯视觉的方法进行公平比较。实验结果表明,尽管vSGraphs仅依赖视觉输入,但在检测建筑构件和结构元素方面,其准确率与基于LiDAR的方法相当。这突显了其视觉特征处理和场景图生成在高精度理解环境方面的有效性。需要注意的是,Hydra并未直接提供“墙”实体,因此Hydra的性能其评估基于正确“房间”元素的计数和识别。此外,当前vS-Graphs的实现不包含“楼层”实体,因此在分析中予以舍弃。图6对vS-Graphs、S-Graphs和Hydra在两个数据集实例中生成的重建场景图进行了定性比较。
4. 运行时分析
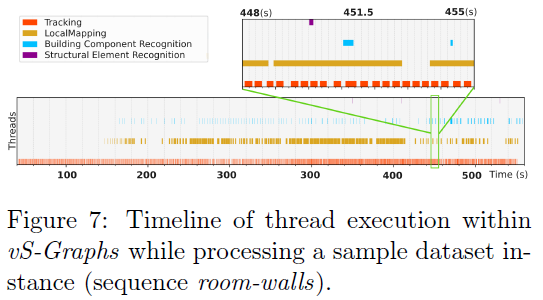
vS-Graphs实现了实时性能,平均处理速率为每秒22±3帧(FPS),超过了实时操作所需的20FPS阈值。这是通过多线程架构实现的,如图7所示。“跟踪”线程在帧级别处理视觉特征,而“局部建图”线程则同时对物体进行建图并优化其位置。“构建组件识别”线程在关键帧级别并行运行,从在线全景分割中识别潜在的墙壁和地面表面。“结构元素识别”线程运行频率较低且周期固定(每两秒一次),用于推断地图中的房间和走廊。与在相同硬件和数据集上ORB-SLAM3的29±3FPS相比,vS-Graphs略微降低的帧率是其丰富语义场景理解能力的合理权衡。
04 总结
本文介绍了vS-Graphs,这是一种实时的VSLAM框架,它利用可优化的分层3D场景图来重建机器人操作环境。为实现这一目标,该框架检测建筑组件(如墙壁和地面),从中推断出结构元素(如房间和走廊),并将它们全部整合到分层表示中。因此,除了通过整合这些有意义的实体来增强地图重建外,vS-Graphs还提供了高级环境驱动语义对象之间空间关系的结构化和灵活表示。使用标准和内部的室内数据集进行的实验结果表明,与基线和最先进的VSLAM方法相比,所提出的框架在真实世界收集的数据集实例中,将轨迹误差降低了高达9.58%,从而实现了更优的轨迹估计和建图性能。其他评估表明,vS-Graphs处理的视觉特征能够有效地识别描述环境布局的语义实体,其准确性可与精确的激光雷达方法相媲美。未来的工作包括整合更多的建筑组件(例如天花板、窗户和门道)以及结构元素(例如地板),以丰富重建的地图,同时扩展对不规则房间布局(例如非矩形空间)和非线性墙壁(例如曲面)的检测支持。
-
mfc多线程编程实例2023-12-01 2925
-
多线程如何保证数据的同步2023-11-17 2789
-
Java多线程的用法2023-09-30 2365
-
RT-Thread嵌入式实时多线程操作系统介绍2022-02-17 1265
-
Linux下的多线程编程2019-04-02 961
-
mfc多线程编程实例及代码,mfc多线程间通信介绍2017-12-08 18636
-
多线程细节问题学习笔记2017-11-28 1535
-
一种支持同时多线程的VLIW DSP架构2011-02-28 973
-
基于多线程的雷达数据实时处理系统2010-12-01 845
-
多线程技术在电能质量实时监控系统中的应用2009-09-04 614
-
多线程在VC++串口通信程序中的应用2009-09-03 788
-
QNX环境下多线程编程2009-08-12 1225
-
NP多线程防火墙的设计与实现2009-08-06 909
-
基于USB和多线程的实时数据采集系统2009-04-16 922
全部0条评论

快来发表一下你的评论吧 !
