

CPU和GPU的简介和差别
描述
NVIDIA 近日宣布,NVIDIA® Tesla® AI 超级计算机平台将为最新一期的全球最节能高性能计算 (HPC) 系统 Green500 榜单中排名前 13 的系统提供动力支持。所有这 13 台计算机均使用 NVIDIA Tesla P100 数据中心 GPU 加速器,其中便包括基于 NVIDIA DGX-1™ AI 超级计算机的四个系统。
NVIDIA还公布一些性能数据,这些数据表明,相比两年前发布的 Kepler 架构,NVIDIA Tesla GPU 已将 HPC 应用程序的性能提升 3 倍之多。这大大超越摩尔定律对于性能提升的预测,甚至在其近些年开始减速之前便已如此。
很多人有这样的疑问,现在像挖矿、破解密码甚至超级计算等领域,越来越多地需要用的是 GPU 而不是 CPU,是不是CPU被GPU取代的一天就要到来了?
CPU和GPU简介
什么是CPU
中央处理器(英文Central Processing Unit,CPU)是一台计算机的运算核心和控制核心。CPU、内部存储器和输入/输出设备是电子计算机三大核心部件。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU由运算器、控制器和寄存器及实现它们之间联系的数据、控制及状态的总线构成。差不多所有的CPU的运作原理可分为四个阶段:提取(Fetch)、解码(Decode)、执行(Execute)和写回(Writeback)。 CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码,并执行指令。所谓的计算机的可编程性主要是指对CPU的编程。
CPU的功能
计算机求解问题是通过执行程序来实现的。程序是由指令构成的序列,执行程序就是按指令序列逐条执行指令。一旦把程序装入主存储器(简称主存)中,就可以由CPU自动完成从主存取指令和执行指令的任务。
CPU具有以下4个方面的基本功能:
1、指令顺序控制
这是指控制程序中指令的执行顺序。程序中的各指令之间是有严格顺序的,必须严格按
程序规定的顺序执行,才能保证计算机工作的正确性。
2、操作控制
一条指令的功能往往是由计算机中的部件执行一序列的操作来实现的。CPU要根据指令的功能,产生相应的操作控制信号,发给相应的部件,从而控制这些部件按指令的要求进行动作。
3、时间控制
时间控制就是对各种操作实施时间上的定时。在一条指令的执行过程中,在什么时间做什么操作均应受到严格的控制。只有这样,计算机才能有条不紊地自动工作。
4、数据加工
即对数据进行算术运算和逻辑运算,或进行其他的信息处理。CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码。它把指令分解成一系列的微操作,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行。指令是计算机规定执行操作的类型和操作数的基本命令。指令是由一个字节或者多个字节组成,其中包括操作码字段、一个或多个有关操作数地址的字段以及一些表征机器状态的状态字以及特征码。有的指令中也直接包含操作数本身。
什么是GPU
(Graphic Processing Unit)图形处理芯片。是显示卡的“心脏”,也就相当于CPU在电脑中的作用,它决定了该显卡的档次和大部分性能,同时也是2D显示卡和3D显示卡的区别依据。2D显示芯片在处理3D图像和特效时主要依赖CPU的处理能力,称为“软加速”。3D显示芯片是将三维图像和特效处理功能集中在显示芯片内,也即所谓的“硬件加速”功能。显示芯片通常是显示卡上最大的芯片(也是引脚最多的)。现在市场上的显卡大多采用nVIDIA和ATI两家公司的图形处理芯片。
今天,GPU已经不再局限于3D图形处理了,GPU通用计算技术发展已经引起业界不少的关注,事实也证明在浮点运算、并行计算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能,如此强悍的“新星”难免会让CPU厂商老大英特尔为未来而紧张, NVIDIA和英特尔也经常为CPU和GPU谁更重要而展开口水战。
GPU通用计算方面的标准目前有 OPEN CL、CUDA、ATI STREAM。其中,OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景,AMD-ATI、NVIDIA现在的产品都支持OPEN CL。
1985年 8月20日 ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年 4月 ATi发布了 Mach32 图形卡集成了图形加速功能,1998年 4月 ATi被IDC评选为图形芯片工业的市场领导者,但那时候这种芯片还没有GPU的称号,很长的一段时间ATI都是把图形处理器称为VPU,直到AMD收购ATI之后其图形芯片才正式采用GPU的名字。NVIDIA公司在1999年发布GeForce 256图形处理芯片时首先提出GPU的概念。从此NV显卡的芯就用这个新名字GPU来称呼。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时。GPU所采用的核心技术有硬体T&L、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬体T&L技术可以说是GPU的标志。
CPU与GPU的区别
CPU和GPU大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
于是CPU和GPU就呈现出非常不同的架构(示意图):
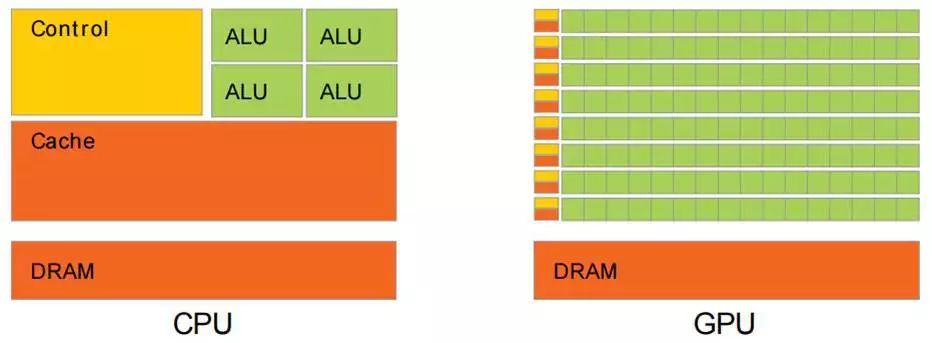
图片来自nVidia CUDA文档。其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分
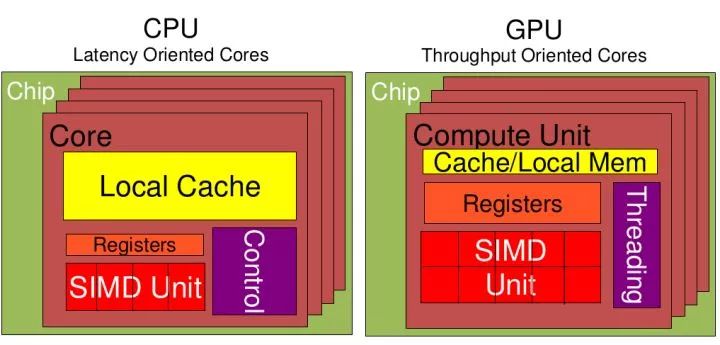
从上图可以看出:Registers: GPU > CPU 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。
SIMD Unit(单指令多数据流,以同步方式,在同一时间内执行同一条指令): GPU > CPU。
CPU 基于低延时的设计:
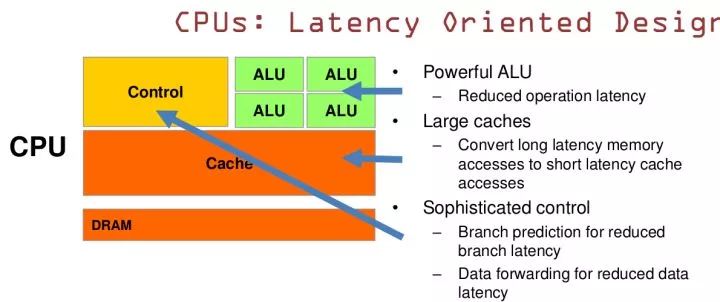
CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方)。大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
复杂的逻辑控制单元。当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
GPU是基于大的吞吐量设计:
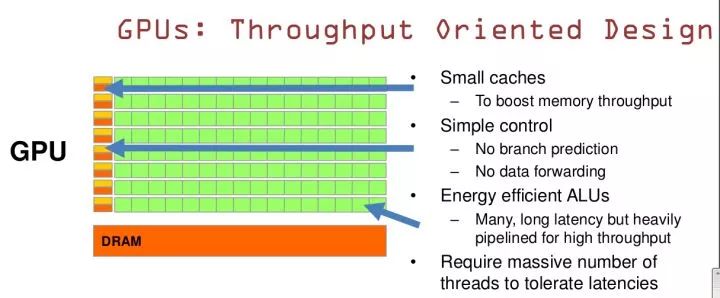
GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为啦平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。
所以与CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。但还有一些任务涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。
总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
就目前的计算机架构,GPU只能称作是小众
GPU作为后来者,出现的太晚了,计算机架构已经定型,不太可能撼动 Intel 的霸主地位,而且Intel 一定会借着先天优势打压其他竞争对手。
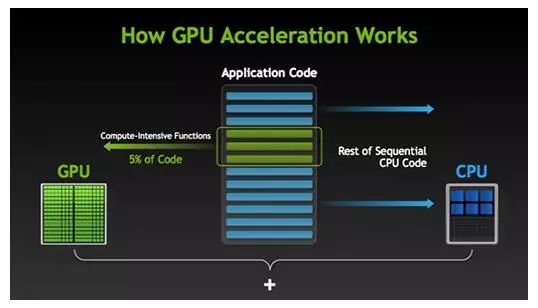
为什么GPU只能算作是小众。在计算机上运行的程序从性能的角度来说大致可分为三类:1、 I/O intensive;2、 Memory intensive 以及3、Compute-intensive。
1、I/O intensive的程序其性能瓶颈是I/O,也就是说程序运行的大部分时间花在了硬盘读写/网络通信上,而I/O处在计算机体系结构金字塔的最底层,速度非常慢。最近炒的很火的big data 讨论的就是这一类应用程序。几百TB 甚至到PB级别的数据往哪搁,只能放在硬盘上。一台机器容量太小CPU太少怎么办,搞几百台甚至上千台机器用网线连起来分布处理。所以这块全是I/O, 现在大的互联网公司不多搞几个上千节点的集群肯定撑不住。
2、Memory intensive的程序其性能瓶颈在内存访问,程序中有大量的随机访问内存的操作,但是基本没有I/O, 这类程序已经比第一类程序快一个数量级了,但是和寄存器的速度还是没法比。目前大部分应用程序都属于这类。个人电脑里装的的各种软件基本就是这类,如果有点I/O, 立刻就会非常得卡。
以上提到的这两类程序的应用最广泛,涵盖了大部分有用的计算机软件,但遗憾的是GPU在这两块毫无用处, GPU只有在计算密集型的程序有些作用。I/O是瓶颈的程序,花在计算的时间可以忽略不计,再怎么用GPU加速也没用。 含有大量内存随机访问的程序也不适合在GPU上执行,大量的随机访问甚至可以使GPU的行为由并行变为串行。
什么类型的程序适合在GPU上运行
1、计算密集型的程序
所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
2、易于并行的程序
GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
GPU和 CPU 谁也替代不了谁
如果形象点理解,GPU就像一群蚂蚁,这些蚂蚁都做着同样的事,而CPU就像一只猴子,这只猴子做着各种不同的事。
CPU和GPU它们的目的不同,且有不同侧重点,也有着不同的性能特性,在某些工作中CPU执行得更快,另一工作中或许GPU能更好。
当你需要对大量数据做同样的事情时,GPU更合适,当你需要对同一数据做很多事情时,CPU正好。
可以预见在未来,随着CPU进一步强化处理数据块的能力,我们将看到CPU和GPU架构之间的融合,而且随着制造技术的进步和芯片的缩小,GPU也可以承担更复杂的指令。CPU与GPU间的分工虽然还是大有不同,但彼此间的交集无疑会更多。
-
gpu是什么和cpu的区别2024-02-20 21614
-
为什么GPU比CPU更快?2024-01-26 3523
-
CPU、GPU和内存知识科普2023-11-13 2862
-
cpu gpu npu的区别 NPU与GPU哪个好?gpu是什么意思?2023-08-27 13013
-
gpu和cpu哪个更重要?2023-08-09 9260
-
CPU和GPU频率的查看及设置2022-09-21 11591
-
CPU和GPU的区别有哪些2022-01-06 33237
-
GPU和CPU的区别是什么2021-01-05 2802
-
CPU-GPU同步暂停2020-05-31 2225
-
GPU与CPU间的比较2019-08-26 5783
-
FPGA比CPU和GPU快的原理是什么2018-05-31 17320
-
CPU内存或GPU内存进行分组方式实战2018-05-03 7815
-
GPU优势大于CPU?CPU将消失?2018-04-08 2206
全部0条评论

快来发表一下你的评论吧 !
