

SSD多盒目标检测技术的直观解释
电子说
描述
编者按:Towards Data Science博主Eddie Forson直观地解释了SSD多盒目标检测技术。
端到端目标检测(来源:Microsoft)
本文的目的是构建一个SSD多盒目标检测技术的直观解释。我尝试尽可能少地使用数学,相反,缓慢地引导你了解整个架构的原则,包括解释多盒算法的作用。阅读本文之后,我希望你更好地理解了SSD,并可以自行尝试使用这一模型。
自从AlexNet在2012年ILSVRC上暴风般地占领学术界之后,深度学习便成为图像识别任务的首选方法,远超文献中更传统的计算机视觉技术。在计算机视觉领域中,卷积神经网络在图像分类(classification)方面表现出色。图像分类任务中,给定待分类的图片和一个分类(class)的集合(例如,猫、狗),然后让网络决定图像的最强(strongest)分类。
猫狗图(来源:kaggle)
当前,深度学习网络在图像分类方面的表现已经超过人类,这表明这一技术是多么强大。然而,我们人类观察世界和与世界交互时所做的远不止分类图片。我们同时定位(localize)和分类(classify)视野内的每个元素。这些复杂得多的任务,机器仍在艰辛地努力达到和人类相当的表现。事实上,我主张,表现良好的目标检测将使机器更接近真实场景理解。
图像显示了猫、狗,还是两者皆有?(来源:kaggle)
基于区域的卷积神经网络(R-CNN)
几年前,研究人员提出了R-CNN,以应对目标检测、定位、分类任务。大体上说,R-CNN是一种特殊的CNN,可以定位和检测图像中的目标:输出基本上是一组匹配检测到的目标的包围盒,以及对应的分类。下图显示了一个典型的R-CNN输出的结果:

这一领域的论文很多,对有兴趣深入的读者,我推荐从下面的“三部曲”开始:
R-CNN
Fast-R-CNN
Faster-R-CNN
正如你可能猜到的那样,Fast-R-CNN是对R-CNN的改进,而Faster-R-CNN又是对Fast-R-CNN的改进,以研发针对实时目标检测的更快的网络。上面的“三部曲”达到的成就真的很惊人,不过没有一个架构成功构建了一个实时目标检测器。这些网络存在以下问题(省略细节部分):
难以训练,并且训练时间过长
需要进行多阶段训练(例如,训练候选区域和分类器)
网络在推理阶段太慢(即处理非训练数据)
幸运的是,最近提出了新的架构,以解决R-CNN的瓶颈。其继任者足以进行实时目标检测。其中最有名的是YOLO(You Only Look Once,你只看一次)和SSD多盒(SSD是Single Shot Detector单次检测器的缩写)。本文将讨论SSD,因为相比YOLO,目前网上介绍SSD架构的文章不多。另外,一旦你理解了SSD,你会更容易理解YOLO.
单次多盒检测器
C. Szegedy等人在2016年11月底发表的论文SSD: Single Shot MultiBox Detector在目标检测任务中创造了新纪录,在PascalVOC和COCO这样的标准数据集上取得了74% mAP(mean Average Precision),59帧每秒的成绩。为了更好地理解SSD,让我们先从解释这一架构命名的由来开始:
Single Shot(单次) 这意味着目标定位和分类任务通过网络的单次前向传播完成。
MultiBox(多盒) 这是由Szegedy等开发的包围盒回归技术。
Detector(侦测器) 该网络是一个目标侦测器,分类检测到的目标。
架构
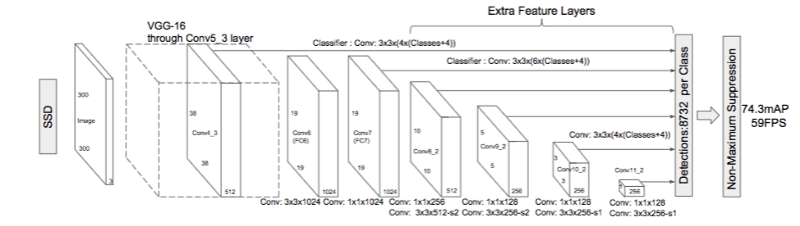
单次多盒侦测器架构(输入 300x300x3)
如上图所示,SSD的架构基于可敬的VGG-16架构,但抛弃了全连接层。使用VGG-16作为基础网络(base network)的原因是其在高画质图像分类任务上的强力表现和在迁移学习有助于改善结果的任务上的流行性。架构没有使用原VGG的全连接层,转而加入了一组辅助卷积层(自conv6开始),从而在不同尺度上提取特征,并逐层递减输入的尺寸。
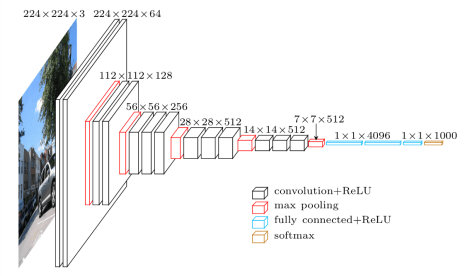
VGG架构(输入 224x224x3)
多盒
SSD的包围盒回归技术受到了Szegedy在多盒方面的工作的启发。多盒是一种快速分类不可知(class-agnostic)包围盒坐标提议的方法。有趣的是,多盒使用的是Inception风格的卷积神经网络。下图中的1x1卷积有助于降维,因为维度将下降(但“宽度”和“高度”将保持不变)。
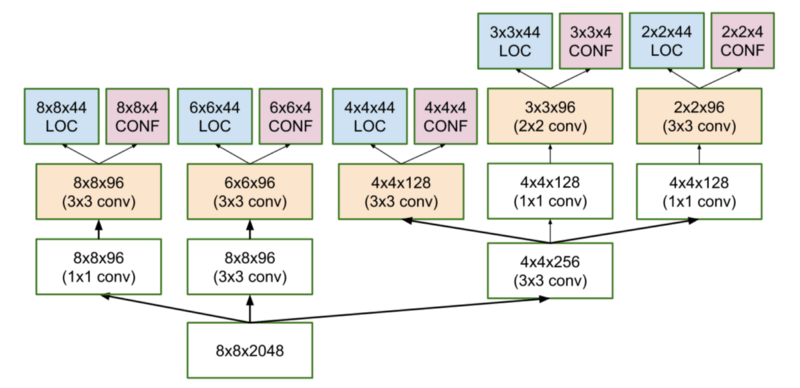
多盒架构
多盒的损失函数同样组合了两个关键的组件,这也为SSD所吸收:
置信度损失(Confidence Loss) 衡量网络对计算出的包围盒的objectness的置信度。使用类别交叉熵计算这一损失。
定位损失(Location Loss) 衡量网络预测的包围盒和训练集的标准答案相差多远。这里使用了L2正则化。
不过多深究数学的话,(如果你很好奇并想了解更严谨的概念,请阅读论文)损失的表达式如下:
multibox_loss = confidence_loss + alpha * location_loss
其中,alpha项帮助我们平衡定位损失的贡献。
多盒先验和IoU
涉及包围盒生成的逻辑实际上比我之前陈述的要复杂。不过别怕:它仍在能力范围之内。
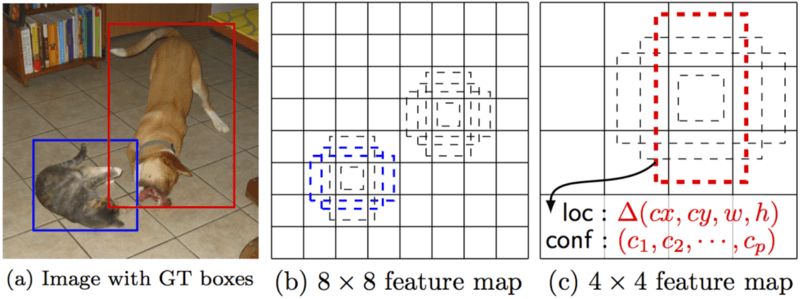
多盒中的先验(prior)(Faster-R-CNN术语中的锚(anchor))是提前计算的固定尺寸包围盒,匹配原标准答案包围盒的分布。事实上,这些先验的选取方式使得它们和标准答案包围盒的交并比(IoU,有时称为Jaccard指数)大于0.5. 从下图可以推测,0.5的交并比仍然不够好,但是它确实为包围盒回归算法提供了一个强力的开始——这是一个比随机坐标要好得多的策略!因此,多盒从将先验作为预测开始,试图回归逼近标准答案包围盒。
IoU示意部分取自维基百科
最终所得的架构(参考前文提及的多盒架构示意图),每个特征映射细胞(8x8、6x6、4x4、3x3、2x2)包含11个先验,而1x1特征映射仅包含一个先验,即每张图像共有1420个先验,从而在输入图像上达到不同比例的稳健覆盖,以检测不同尺寸的目标。
最后,多盒仅仅保留最好的K个预测,这些预测同时最小化定位(LOC)损失和置信度(CONF)损失。
SSD的改进
回到SSD,SSD加入了一些调整,提升了该网络定位和分类目标的能力。
固定先验 和多盒不同,每个特征映射细胞关联一组尺寸和长宽比不同的默认包围盒。这些先验是手工(精心)选择的,而在多盒中,先验是基于与相应的标准答案包围盒的交并比超过0.5选择的。在理论上这使得SSD可以概括任何种类的输入,无需生成先验的预训练阶段。例如,假定我们为每个特征映射细胞的每个默认包围盒b配置了两个对角点(x1, y1)和(x2, y2),然后需要基于c个分类进行分类,而给定的特征映射尺寸为f = m * n,那么,SSD将为该特征映射计算f * b * (4 + c)值。
定位损失 SSD使用平滑L1正则化(smooth L1-Norm)计算定位损失。尽管不如L2正则化那样精确,这仍然非常有效,也给了SSD更多取巧的空间,因为SSD的包围盒预测并不追求“像素完美”(对许多人而言,一些像素的差异很难察觉)。
分类 多盒并不执行目标分类,而SSD进行分类。因此,SSD为每个预测的包围盒、数据集中的每个可能的分类计算c分类预测的集合。
训练并运行SSD
数据集
我们将训练和测试带有标准答案包围盒及相应的分类标签(每个包围盒有一个分类标签)的数据集。Pascal VOC和COCO数据集是一个很好的开始。
Pascal VOC数据集图像
默认包围盒
建议配置一组多样化的包围盒,包括不同的比例和长宽比,确保可以捕捉到大多数目标。在SSD论文中,每个特征映射单元有6个包围盒。
特征映射
特征映射(即卷积块的结果)是不同尺度上图像的主导特征的表示,因此在不同特征映射上运行多盒增加了逐渐检测、定位、分类任何目标(大目标和小目标)的概率。下图显示了网络是如何在特征映射上“看到”给定图像的:
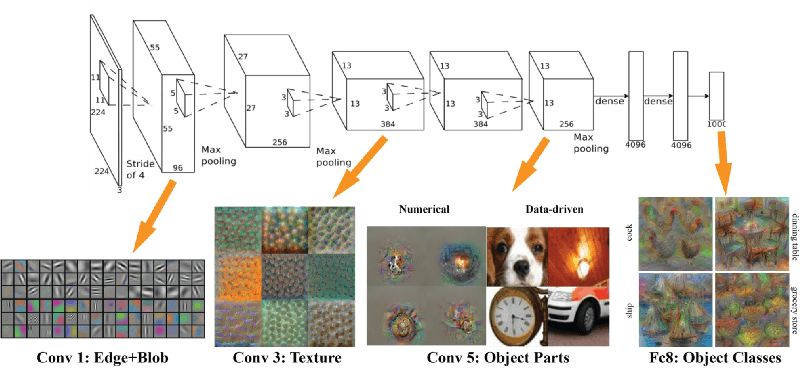
VGG特征映射可视化(图片来源 Brown Uni)
Hard Negative Mining
在训练中,由于大多数包围盒的IoU较低,会被视作负面训练样本,我们最终的训练集可能会有不成比例的负面样本。因此,建议不要使用所有的负面预测,将负面样本和正面样本的比例保持在3:1. 我们需要保留负面样本的原因是网络同样需要学习什么构成了错误检测。
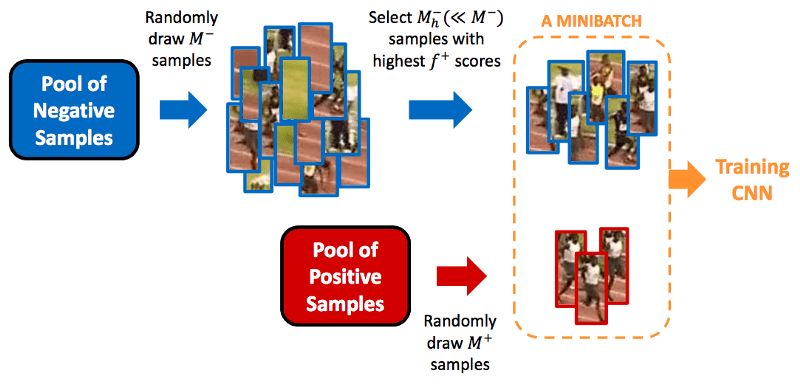
图片来源 Jamie Kang
数据增强
SSD的作者说,和许多深度学习应用一样,数据增强是非常重要的部分,使网络能够学习更稳健地应对输入中的不同目标尺寸。为了达到这一目标,他们生成了额外的训练样本,包括不同IoU的补丁(例如,0.1、0.3、0.5等),以及随机补丁。此外,每张图像基于0.5的概率随机水平翻转,从而确保潜在目标出现在左侧和右侧的概率相同。
水平翻转的图像,来源:Behavioural Cloning
非极大值抑制(NMS)
在推理阶段,SSD的前向传播中生成了数量巨大的包围盒,因此应用非极大值抑制(non-maximum suppression)技术修剪大多数包围盒很有必要:置信度损失低于阈值ct(例如,0.01),IoU低于阈值lt(例如,0.45)的包围盒被抛弃了,仅保留最高的N个预测。这确保只有最可能的预测被网络保留,而移除了大多数噪声。
NMS的例子(来源:DeepHub)
SSD的补充说明
SSD提出了以下观察:
更多的默认包围盒导致更精确的检测,不过这会影响速度。
在多层上使用多盒同样能带来更好的检测效果,这是因为检测器在不同尺度的特征上运行。
80%的时间花在基础VGG-16网络上:这意味着使用一个速度更快的同样精确的网络,SSD的性能会更好。
相似类别的目标会迷惑SSD(例如,动物)。这大概是因为不同分类的位置相同。
SSD-500(使用512x512输入图像的SSD最高分辨率变体)在Pascal VOC2007上达到了最佳mAP(76.8%),不过相应的代价是速度,帧率降至22 fps. 因此,SSD-300是一个更好的折衷(74.3% mAP、59 fps)。
SSD在较小的目标上表现较差,因为较小的目标可能不在所有特征映射上出现。增加输入图像分辨率缓解了这一问题,但并没有完全解决它。
尝试SSD
网上有一些SSD实现,包括论文作者的Caffe代码。我选用的是Paul Balança的TensorFlow实现。代码和论文都值得一读,以便更好地理解所有东西是如何结合在一起的。
我最近决定基于SSD重新实现一个基于传统计算机视觉技术的车辆检测项目。下面的gif表明SSD的效果非常好:
-
未检测到目标2019-05-27 0
-
ssd模型对小目标检测的效果不好分析2019-09-06 0
-
迅为3399开发板新增目标检测技术-RKSSD-编译程序2021-02-01 0
-
基于EMD和盒维数的固定微弱目标检测2011-05-19 595
-
基于通道注意力机制的SSD目标检测算法2021-03-25 933
-
基于多尺度融合SSD的小目标检测算法综述2021-05-27 929
-
基于SSD和深层神经网络的目标检测方法2021-05-28 696
-
多尺度卷积特征融合的SSD目标检测2021-06-11 758
-
基于Grad-CAM与KL损失的SSD目标检测算法2022-01-21 1013
-
基于改进SSD的车辆小目标检测方法2022-02-08 1456
-
基于并行附加特征提取网络的SSD地面小目标检测模型2022-02-17 1512
-
基于SSD算法的小目标检测方法研究2022-04-02 4184
-
目标检测与识别技术的关系是什么2024-07-17 812
-
目标检测与识别技术有哪些2024-07-17 784
-
ICY DOCK M.2转U.2 SSD转接盒如何重新定义M.2 NVMe SSD2024-10-21 347
全部0条评论

快来发表一下你的评论吧 !
