

机器学习成为材料科学中复杂数据分析和信息挖掘的有力武器
电子说
描述
导语
探索相变和构建相图对于凝聚态物理和材料科学至关重要,是理论和实验领域广泛研究的焦点。相变研究通常需要运用散射、热力学、模拟等综合手段描述相变时序参量的变化,对于序参量未知的体系,传统方法十分局限。最近西安交通大学杨耀东课题组的李玲龙与橡树岭国家实验室Kalinin小组合作,在新发表的Science Advances文章中创新性地提出运用机器学习算法,对扫描探针尖端探测体积下压电弛豫的动力学响应进行数据挖掘,在序参量未知的情况下,确定了纳米尺度的结构相变。这一研究成果实现了序参量缺失情况下的相变表征,为材料科学中高维复杂数据的信息挖掘、分析提供了新颖独特的解决方案。
对于使用机器学习算法构筑相图的设想,研究人员首先在二维Ising模型中,构建了该系统在撤去激励磁场后随时间弛豫的多维度数据集,并采用K-means算法处理得到分类簇,发现其以顺磁-铁磁相界分为三个簇,如图一所示。由此,其可行性在模拟数据集中得以证实。
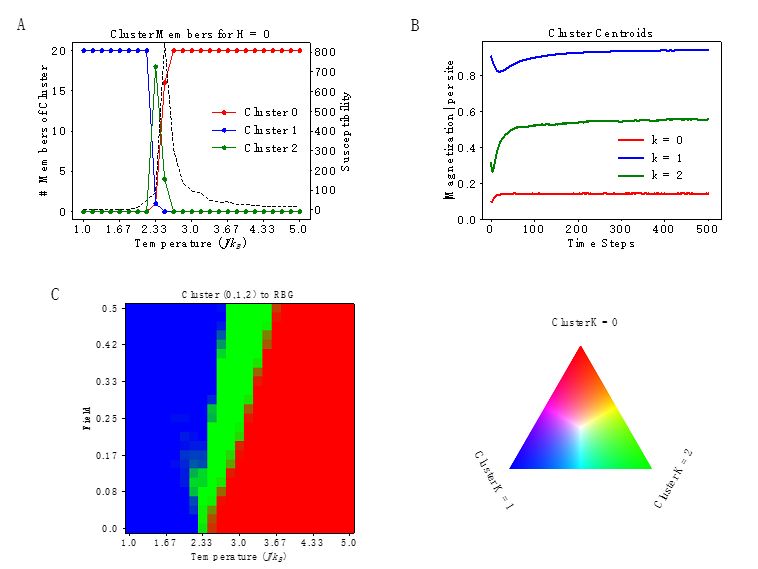
图一K-means聚类算法处理Ising模型数据集。
A:三个簇k=0,1,2中数据向量的数量随温度的变化。B:簇中心的向量。C:簇中数据向量数构建的铁磁-顺磁转变相图。
随后在实验研究中,研究人员通过扫描探针加载脉冲电压,以激励弛豫铁电体PMN-PT中微区压电响应的弛豫信号(激励电压波形如图二A所示),并根据不同脉冲偏压和温度,使用频带激励信号增强技术获得多维度的压电弛豫信号数据集。主成分分析(PCA)作为一种无监督学习算法,能有效针对高维数据进行降维处理。研究人员使用PCA算法,分别获得了数据集的特征值和特征向量。在特征值的突变界面(图二C的黑色虚线),明确指出了相变发生的信号。
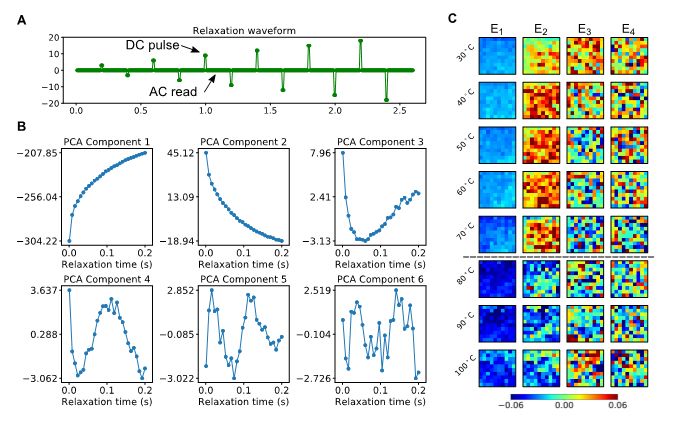
图二 频带激励压电力显微镜获得多维度的压电响应弛豫数据集,以及其主成分分析结果。
A:用于压电弛豫测量的波形。B:PCA得到的特征向量。C:PCA得到的特征值。
进一步使用K-means算法处理偏压-温度多维度数据,根据每一条数据在簇分类中的落点以及簇中包含数据向量的数量,得到偏压-温度维度的相图,如图三B所示。在临界温度70℃左右,落在簇k=0和簇k=1的数据向量的数量发生明显改变,直接对应着材料的两种单斜相MB-MC相变。
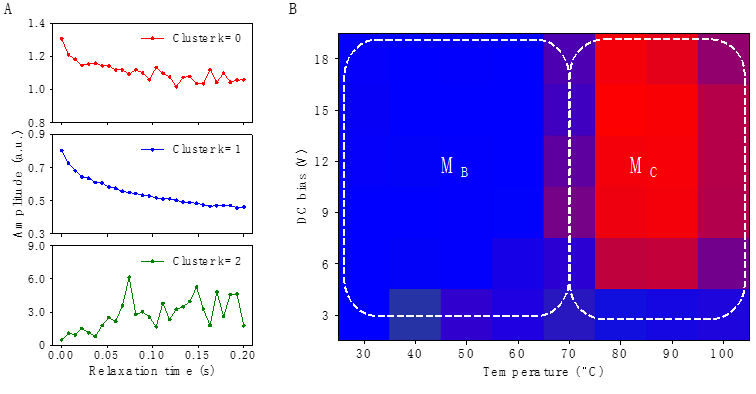
图三 K-Means聚类结果。A:簇中心向量。B:根据簇中数据落点量构建的偏压-温度相图。
研究工作创新性地采用无监督机器学习算法分析电压-热激励下压电弛豫的高维数据集,自动识别材料的相变过程,构建了弛豫铁电晶体的电压-温度相图。尤其在面向序参量缺失(或不可知)的体系时,相较传统的曲线拟合方法,为微观(电场)-宏观(温度)的实验数据集的分析提供了更普适的、全局的方法。更重要的是,这一研究方法不受限于数据维度和测量手段,使得机器学习成为材料科学中复杂数据分析和信息挖掘的有力武器。
-
EBSD在材料科学中的优势分析2024-12-26 1121
-
电子背散射衍射技术(EBSD)在材料科学中的应用与解读2024-12-16 1921
-
DSC:材料科学的洞察之眼2024-09-09 2163
-
科研进阶!EPR在材料科学中的应用交流会即将开幕2023-11-21 1308
-
机器学习与数据挖掘的区别 机器学习与数据挖掘的关系2023-08-17 3334
-
热像仪助力材料科学与工程研究(四)2022-08-18 1507
-
热像仪助力材料科学与工程研究(三)2022-08-16 2266
-
热像仪助力材料科学与工程研究(二)2022-08-02 1765
-
热像仪助力材料科学与工程研究(一)2022-07-22 1787
-
成为Python数据分析师,需要掌握哪些技能2021-06-23 6986
-
材料科学在医疗器械研发中的应用2020-04-14 6892
-
计算机在材料科学中的应用详细中文资料概述(免费下载)2018-06-05 1571
-
材料科学基础ppt2008-09-23 921
全部0条评论

快来发表一下你的评论吧 !
