

几B都有!BM1684X一键适配全系列Qwen3
描述
Qwen3发布,大小尺寸通吃
Qwen3一发布,登顶开源大模型排行榜!235B、32B、8B、4B、1.7B云边端全尺寸模型,BF16和FP8两种精度,一次性发布,无论云端大卡还是边缘AI设备,都可体验最新的大模型能力。
来看下Qwen3各个模型的benchmark得分:
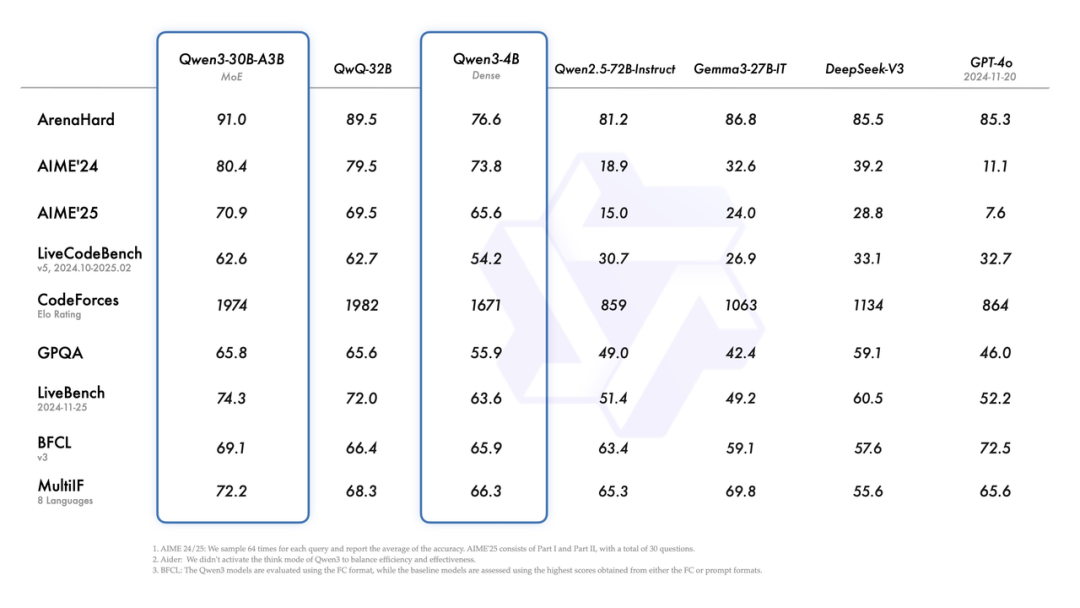
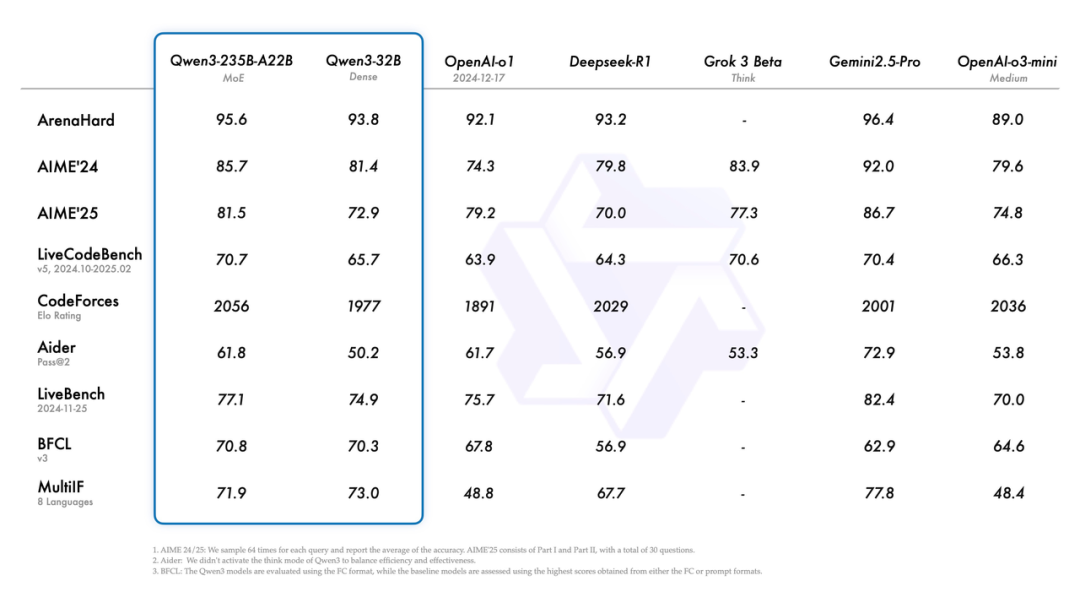
这些年看多了大模型的迭代,各家都在玩参数竞赛和架构魔术,但阿里这次Qwen3的设计有点意思——它搞了个"混合模式"的机制,让模型能自己决定什么时候该"慢慢想",什么时候该"快速答"。这玩意儿本质上是在延迟和精度之间做动态权衡,技术上不算新鲜(OpenAI的o3就玩过这套),但阿里的实现方式更像个老会计——给你个"思考预算"的开关,让用户自己把控成本。
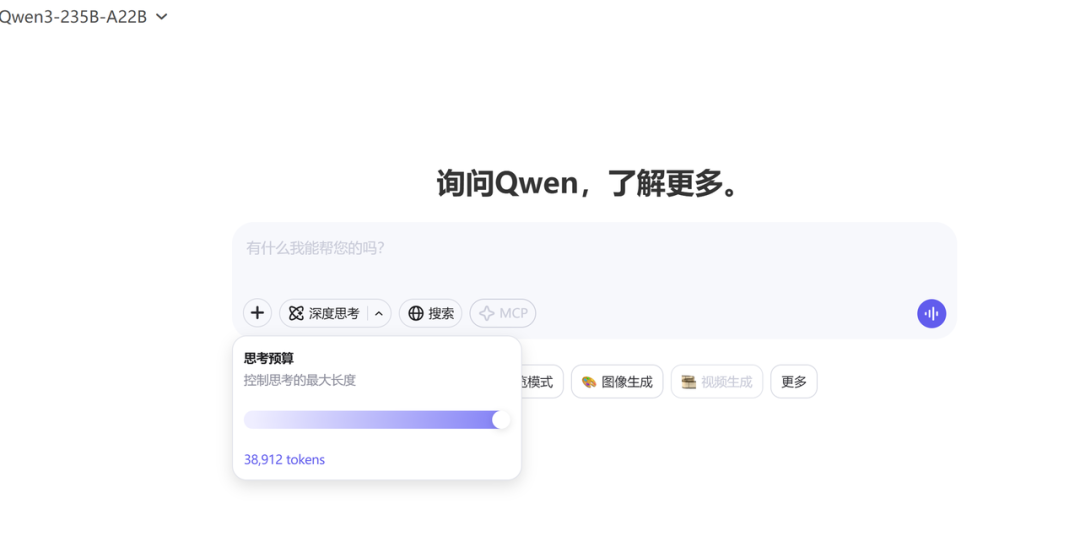
BM1684X,Qwen3部署性价比之王
这种设计背后是典型的工程思维:既然大模型的推理成本居高不下,不如把选择权交给用户。就像当年CPU的动态调频技术,与其无脑跑满频,不如让系统根据负载灵活调节,但这种模式切换要在硬件层面做好流水线调度,否则切换时的上下文保存就能吃掉那点省下来的算力。
现在的大模型就像过度教育的孩子,解得了奥数题但算不清买菜账。Qwen3给"孩子"装了个手动挡,让用户自己决定什么时候该挂高档位冲刺,什么时候该低档省油,这种策略下每瓦特的性价比自然就上去了,而边缘和端侧的设备对成本更是敏感,那作为边缘大模型部署的性价比之王,BM1684X表现如何?
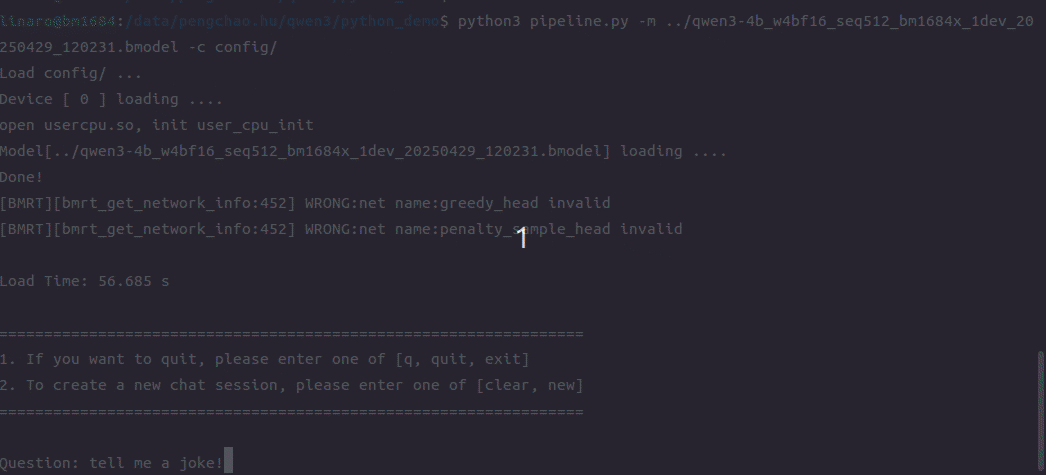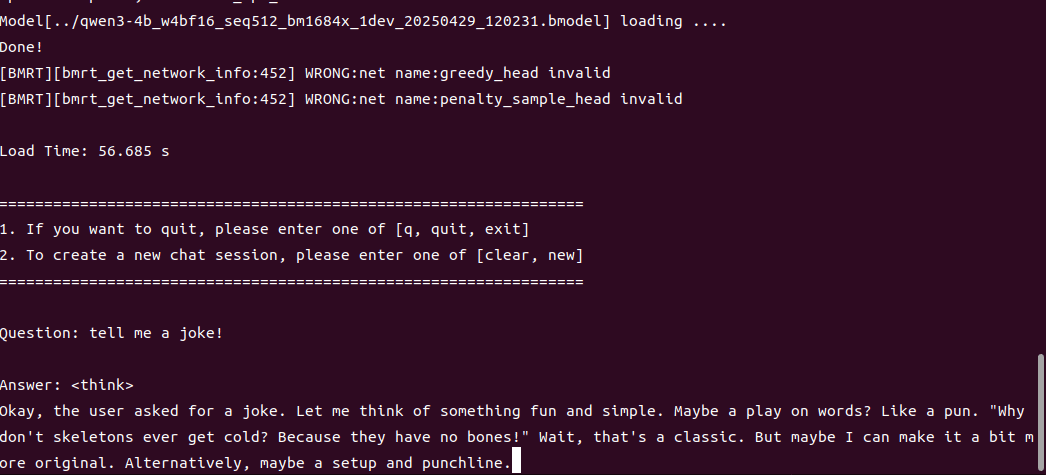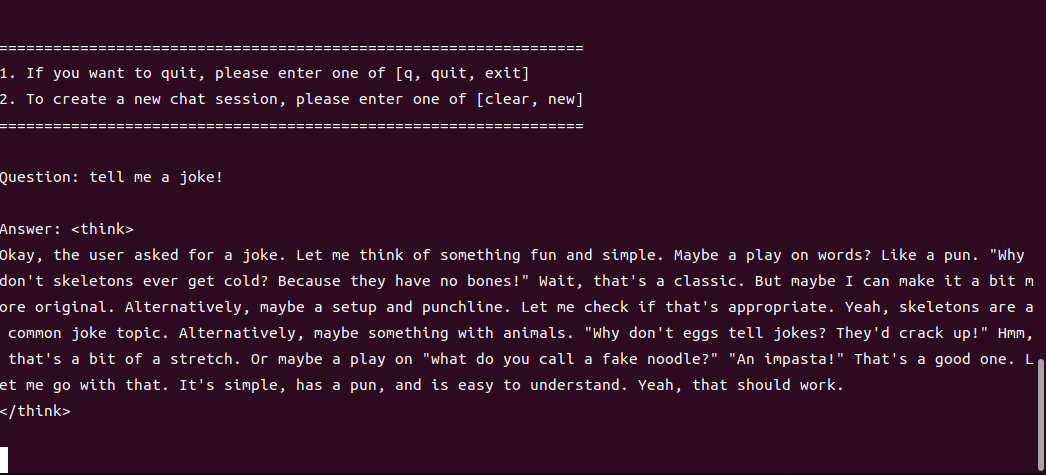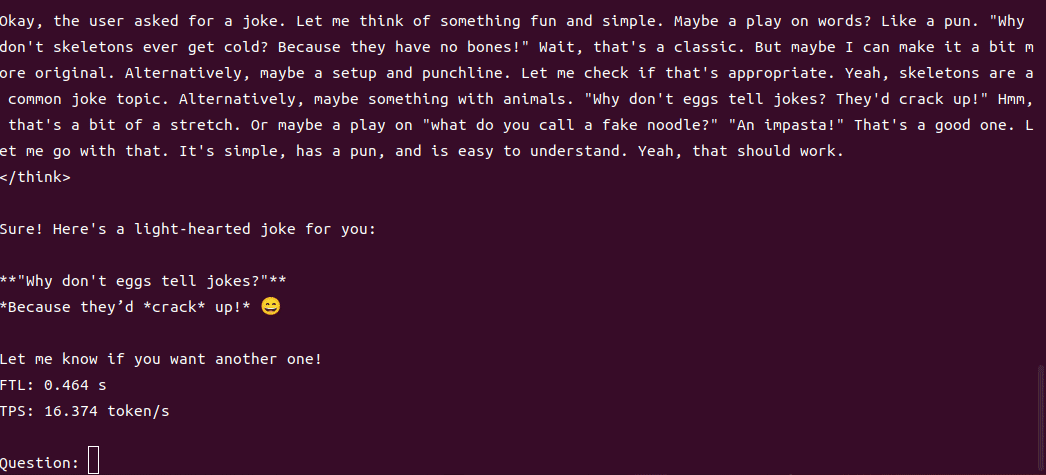
4B运行demo(SOC模式950Mhz 16.4tokens/s)
1.7B运行demo(SOC模式950Mhz 30.3 tokens/s)
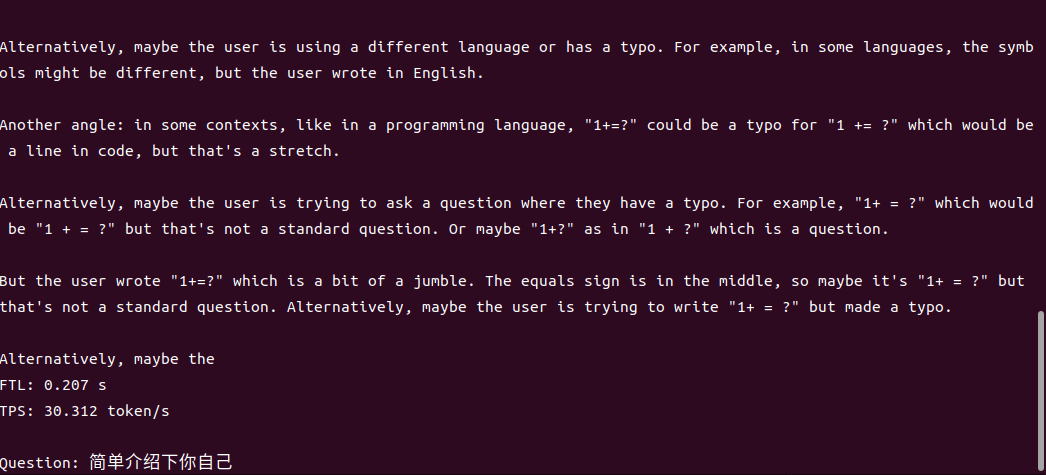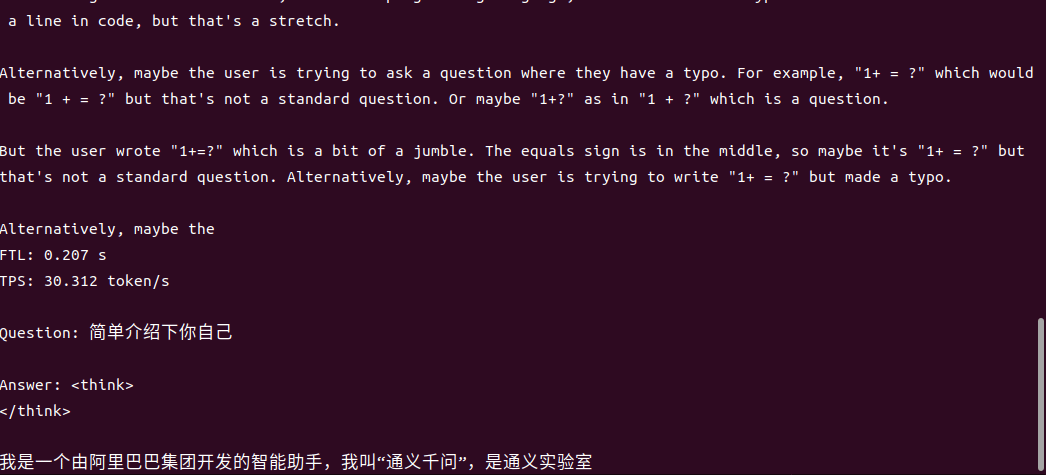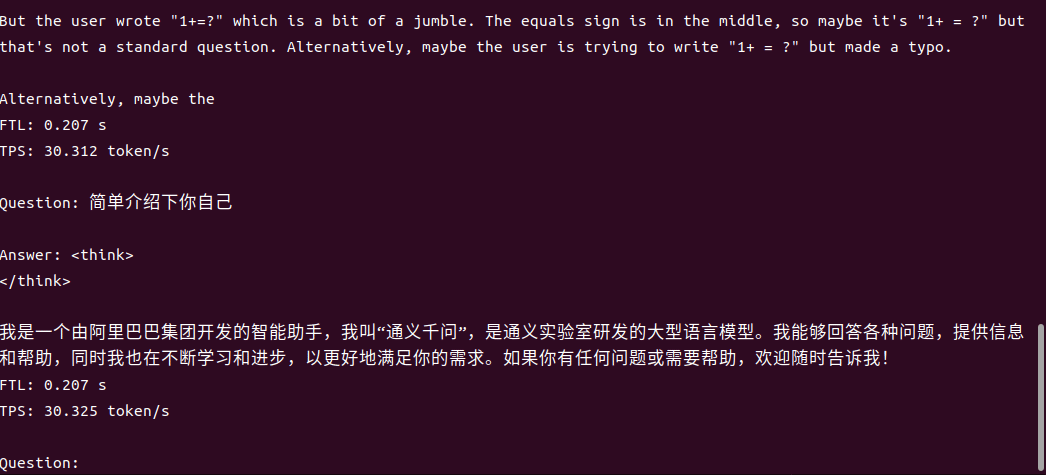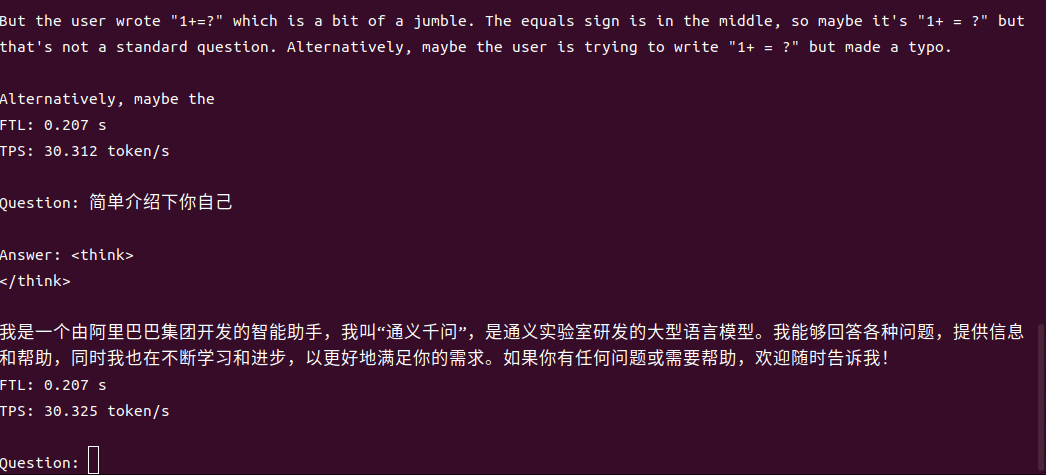
一行代码适配,解锁全系模型
BM1684X 单芯配置16GB内存,20B以下的都可以在一颗芯片跑,32B用2颗就可以(32B dense模型性能约5 tokens/s)。
更详细的适配流程参考:https://github.com/sophgo/LLM-TPU/tree/main/models/Qwen3,拉取最新的tpu-mlir代码后,只需要一行代码即可转出bmodel,不用再通过onnx中介。

bmodel转好之后,可以用python或者cpp来跑:
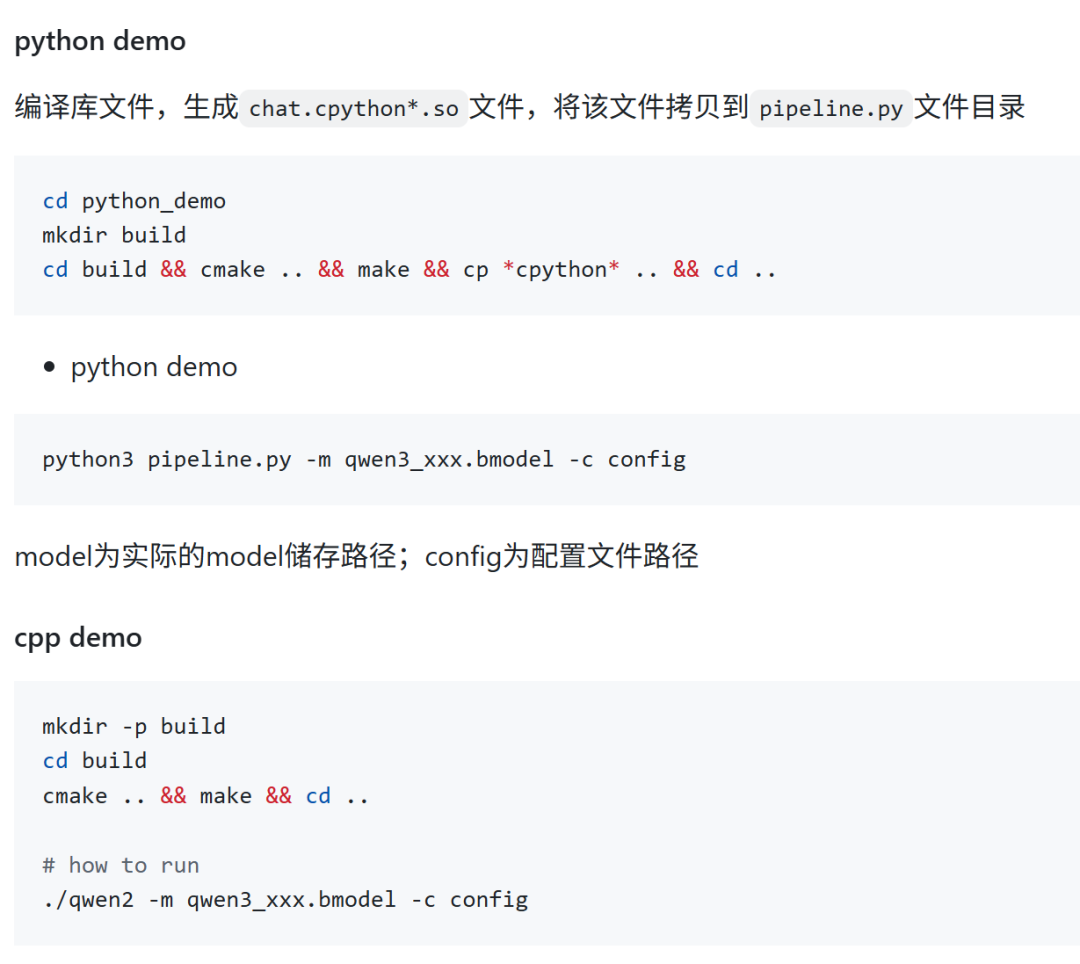
限制我们适配新模型速度的不是工具链,而是模型下载速度,欢迎关注算能产品,解锁更多大模型部署方案,手中有BM1684X的同学可以玩起来了!
-
拒绝手写代码!Openclaw+Skill一键部署Qwen3.5到算能边缘盒子2026-04-18 949
-
从模型到产品:Qwen2.5-VL在BM1684X边缘计算部署全攻略2026-01-13 5267
-
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南2026-01-12 655
-
Qwen3-VL 4B/8B全面适配,BM1684X成边缘最佳部署平台!2025-10-16 3513
-
壁仞科技完成Qwen3旗舰模型适配2025-05-16 1295
-
Arm CPU适配通义千问Qwen3系列模型2025-05-12 1716
-
Intel OpenVINO™ Day0 实现阿里通义 Qwen3 快速部署2025-05-11 2037
-
NVIDIA使用Qwen3系列模型的最佳实践2025-05-08 3391
-
在openEuler上基于vLLM Ascend部署Qwen32025-05-07 2234
-
壁仞科技完成阿里巴巴通义千问Qwen3全系列模型支持2025-04-30 1821
-
bm1684运行demo报错怎么解决?2024-05-20 793
-
32Tops算力!BM1684行业主机系列2023-03-15 8547
全部0条评论

快来发表一下你的评论吧 !
