

基于深度学习自动化的前端开发解析
电子说
描述
作者:Ashwin Kumar编译:weakish
编者按:Ashwin Kumar之前是Sway Finance的联合创始人,Sway Finance是Y Combinator孵化的一家初创企业,使用机器学习技术自动化会计。后来去了Insight,在Insight开发了一个模型,允许用户从手绘的示意图创建可以工作的HTML网站。现任Mythic深度学习科学家。
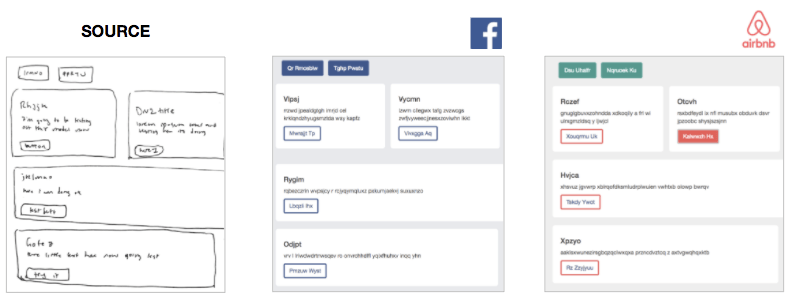
对所有规模的公司而言,创建直观、沉浸式的用户体验都是一个关键的目标。创建用户体验是一个以原型、设计、测试为周期的快速过程。Facebook这样的巨头有充足的资源,可以在设计过程中投入整个团队,设计过程可能长达数周,涉及多个相关者;小企业没有这样的资源,因此它们的用户界面做出来可能会不太好。
我在Insight的目标是使用现代深度学习算法显著地流水线化设计工作流程,赋能任何企业快速创建和测试网页。
今天的设计工作流程
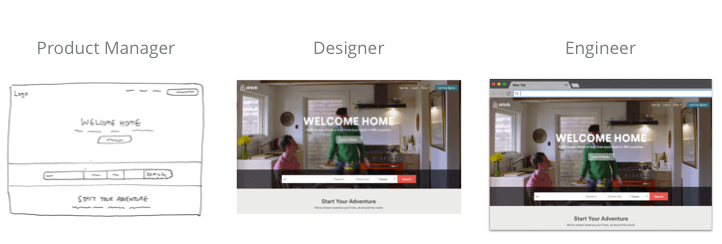
经过多个相关者的设计工作流程
一个典型的设计工作流程可能是这样的:
产业经理进行用户研究,得出一些规格要求
设计师接收需求,探索低保真原型,并逐渐创建高保真模型
工程师将设计实现为代码并最终交付产品至用户
研发周期的长度可能很快成为瓶颈,Airbnb这样的公司开始使用机器学习使这一过程更高效。
尽管看起来这是一个很有前途的机器辅助设计的样例,我们并不清楚这一模型多大程度上是完全基于端到端训练的,多大程度上依赖手工提取的特征。我们无法知道确切的答案,因为这是一个闭源的专有实现。我希望开发一个绘图到代码技术的开源版本,面向更广泛的开发者和设计师。
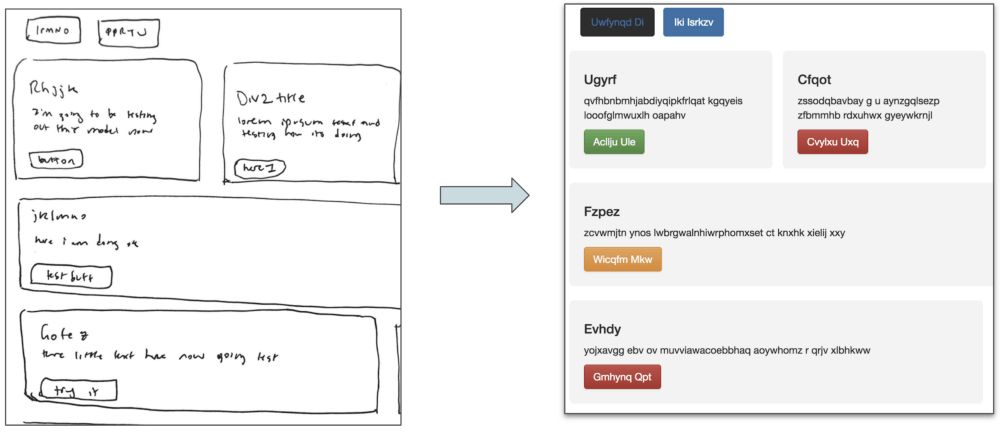
理想情况下,我的模型将可以接受一个简单的手绘网站设计原型,并立刻基于图像生成可以工作的HTML网站:
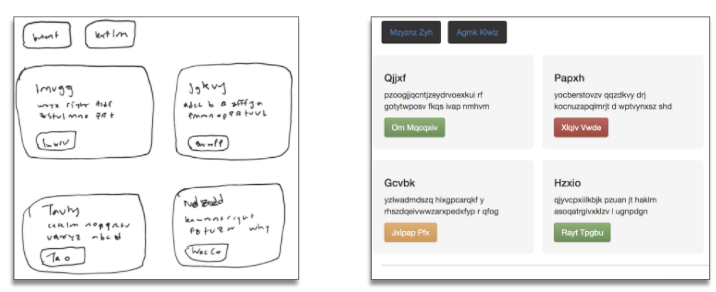
SketchCode模型接受手绘示意图,生成HTML代码
事实上,上图是我的模型在测试图像集上生成的真实网站!相关代码发布在我的GitHub上:ashnkumar/sketch-code
从图像标注汲取灵感
我打算解决的问题属于程序生成任务,自动生成可以工作的源代码。不过,程序生成大多涉及从自然语言规格声明或执行追踪(execution trace)生成代码,而我的案例将基于图像(手绘示意图)生成代码。
在机器学习中,图像标注是一个研究很充分的领域,图像标注寻找能够将图像和文本相联系的学习模型,特别是基于源图像内容生成描述。
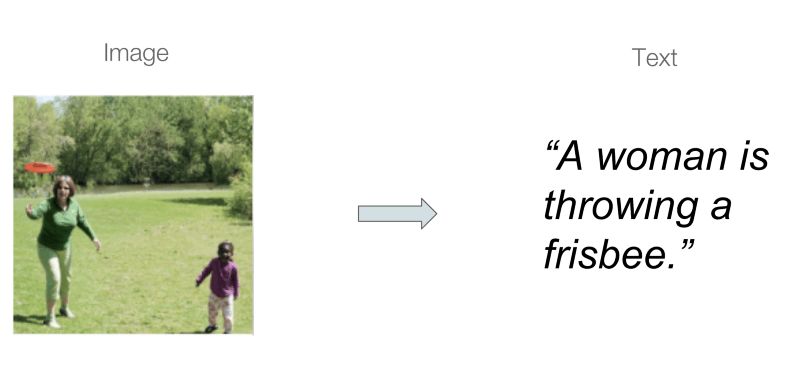
文本:一个扔飞盘的妇女
受最近的pix2code论文和Emil Wallner的相关项目的启发,我决定重塑我的任务为图像标注任务,以手绘网站示意图为输入图像,相应的HTML代码为输出文本。
获取合适的数据集
从图像标注的角度来说,理想的数据集将是数以千计的成对的手绘草图和相应的HTML代码。毫不意外,我没法找到这样的数据集,我需要为这一任务创建自己的数据集。
我从pix2code论文的开源数据库开始,其中包含1750张合成的网站截屏以及相关的源代码。
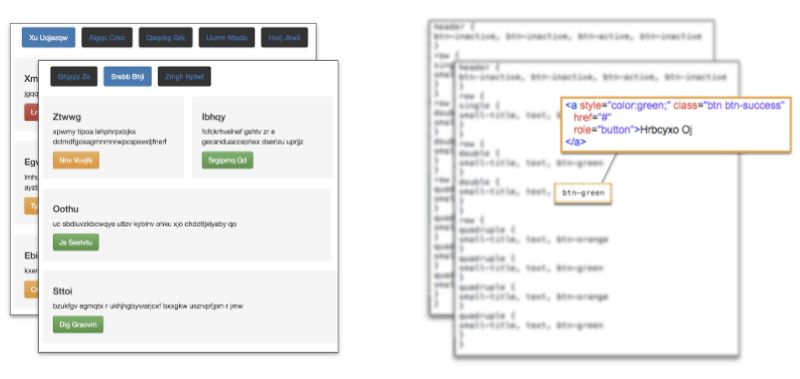
pix2code数据集
这是一个很好的数据库,可以作为我自己的数据集的基础:
数据集中生成的网站包含一些简单的Bootstrap元素的组合,例如按钮、文本框和div。尽管这意味着我的模型的“词汇表”将限于少数元素——可供选择的生成网站的元素——这一方法可以简单地推广至更大的元素词汇表。
每个样本的源代码包含一个领域特定语言(DSL)的token,该DSL是论文作者专门创建的。每个token对应一段HTML和CSS,有一个编译器将DSL编译成可以工作的HTML代码。
让图像看起来像是手绘的
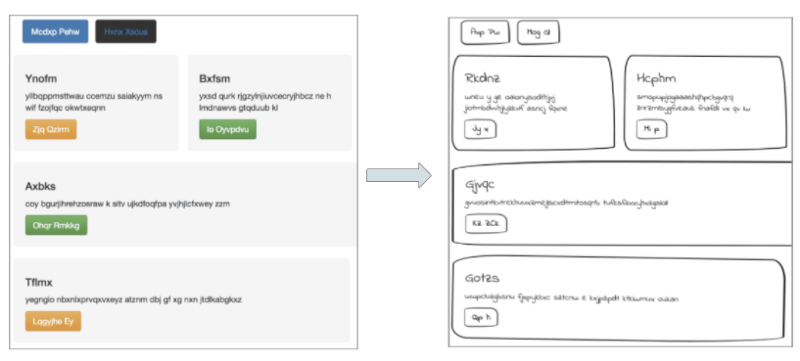
转换彩色网站图像至手绘版本
为了修改数据集以适应我自己的任务,我需要让这些网站图像看起来像是手绘的。我尝试使用python中的OpenCV和PIL库修改每张图像,例如转换为灰度图像,等高线检测。
最终,我决定直接修改原网站的CSS样式表,进行以下操作:
修改网页元素的圆角边框以曲线化按钮和div的边角。
调整边框的厚度,以模拟手绘草图,并添加下降阴影。
修改字体为手绘风格字体。
最后,我通过添加倾斜、移动、旋转以增强这些图像,以模拟实际手绘草图的变化性。
使用图像标注模型架构
现在我已经有数据了,终于可以把数据传给模型了!
我使用了一个图像标注的模型架构,主要包含三部分:
使用卷积神经网络(CNN)从源图像提取图像特征的计算机视觉模型
基于门控循环单元(GRU)的编码源代码token序列的语言模型
接受前两步的输出作为输入,预测序列中的下一个token的解码器模型(也是GRU)
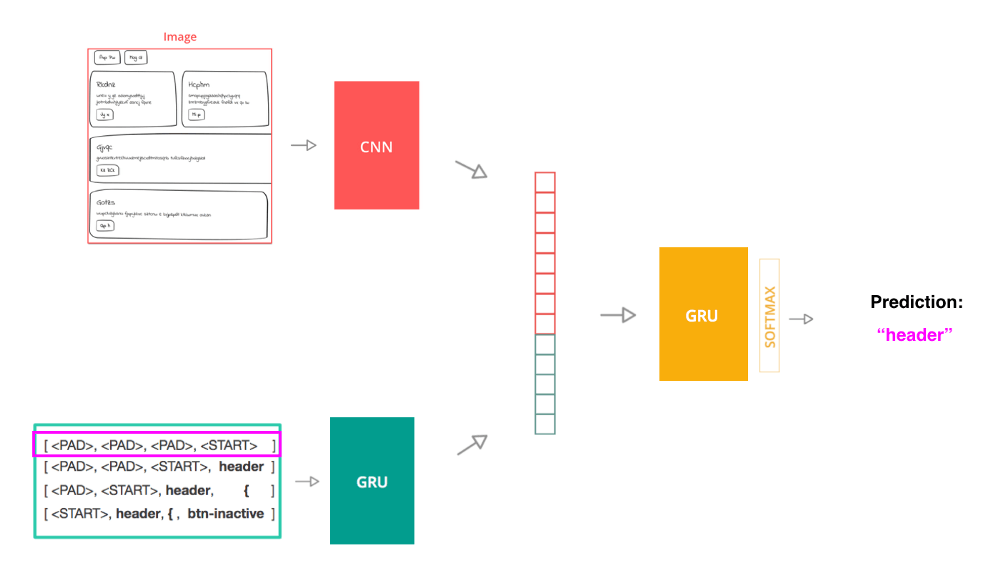
训练使用token序列作为输入的模型
为了训练这一模型,我将源代码拆分成token序列。模型的单个输入是一个序列和源代码图像,标签为文档中的下一个token。模型使用交叉熵作为损失函数,比较模型的下一个token预测和实际的下一个token。
在推理阶段,当模型用来从头生成代码的时候,过程略有不同。图像仍然由CNN处理,但文本过程仅仅使用一个开始序列作为种子。在每一步中,模型将预测的下一token序列附加到当前输入序列,并传给模型作为新输入序列。不断重复这一过程,直至模型预测一个
一旦模型生成了预测token的集合,编译器转换DSL token至可由任何浏览器渲染的HTML。
使用BLEU分数评估模型
我决定使用BLEU分数评估模型。BLEU分数是机器翻译任务中一个常用的指标,这一指标衡量机器生成文本在多大程度上接近由人类基于相同输入生成的文本。
基本上,BLEU比较生成文本和参考文本的n元序列,以创建准确率变体。用BLEU评估这一项目很合适,因为它基于实际生成的HTML元素,以及元素之间的关系。
最棒的是,我可以通过查看生成网站实际看到BLEU分数!
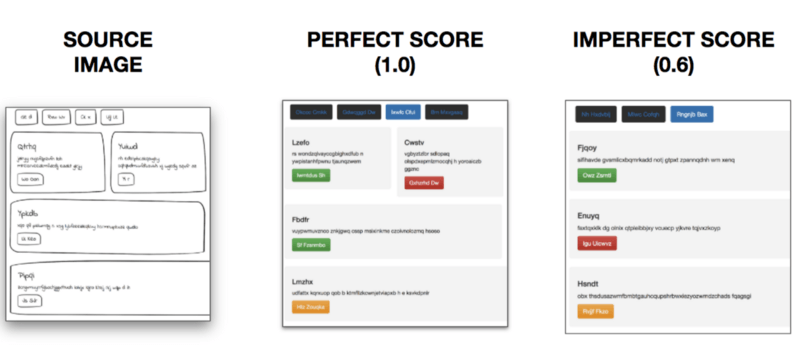
可视化BLEU分数
给定源图像,完美的BLEU分数(1.0)意味着正确的元素位于正确的位置,而较低的分数预测错误的元素,或者元素位于错误的位置。最终模型能够在评估数据集上取得0.76的BLEU分数。
额外奖励——定制风格
我意识到模型提供了一个额外奖励,由于模型仅仅生成网页的骨架,我可以在编译过程中加入定制的CSS层,然后立刻获得所得网站的不同风格。
同一草图对应不同风格
样式解耦模型生成过程带来了很大的优势:
想要在自家公司使用SketchCode模型的前端工程师可以如原样使用模型,仅仅修改一个CSS文件,使网站适配公司的风格指南
内置可伸缩性——基于单一源图像,模型的输出可以立刻编译至5、10、50种不同的预定义分割,因此用户可以可视化多个版本的网站,并在浏览器中浏览查看。
总结和未来方向
利用图像标注方面的研究,SketchCode能够接受手绘网站示意图,并在数秒之内将它们转换为可以工作的HTML网站。
这一模型具有一些限制,这也意味着未来可以做的改进:
由于训练模型的词汇表仅包括16个元素,它无法预测在数据中未见的token。下一步可能使用更多元素生成额外的网站样本,例如图像、下拉菜单、表单——Bootstrap组件是一个很好的开始。
生产环境中的实际网站有很多变化。创建更能反映这些变化的训练数据集的一个很好的方法是抓取实际网站的HTML/CSS代码和网站内容截屏。
手绘同样有很多通过修改CSS无法完全捕捉的变化。在手绘草图数据中生成更多变化的一个很好的方法是使用对抗生成网络创建逼真的手绘网站图像。
如前所述,你可以在GitHub上找到此项目的代码:ashnkumar/sketch-code
原文地址:https://blog.insightdatascience.com/automated-front-end-development-using-deep-learning-3169dd086e82
-
行业首创:基于深度学习视觉平台的AI驱动轮胎检测自动化2025-03-19 1305
-
AI自动化生产:深度学习在质量控制中的应用2025-01-17 1583
-
自动化创建UI并解析数据2024-11-29 9653
-
探索Playwright:前端自动化测试的新纪元2024-10-22 1495
-
860-930MHz射频前端芯片GC1109在工业自动化中的应用2024-05-09 1728
-
2.4GHz ISM的射频前端芯片GC1103用于工业自动化设备2024-04-09 1638
-
Zebra Aurora深度学习OCR算法荣获CAIMRS颁发的自动化创新奖2024-03-20 1048
-
自动化编程要学多久 自动化编程的就业方向2023-04-19 6273
-
智能工厂如何实现深度学习自动化?2022-12-28 1635
-
800G自动化类、嵌入式类以及前端学习资料2021-11-15 621
-
关于800G自动化类、嵌入式类以及前端学习资料分享不看肯定后悔2021-09-23 2434
-
2021年化工自动化控制仪表试题及解析2021-09-02 1414
-
工博会:自动化机器人的交流盛会2018-09-21 1491
-
自动化立体仓库监控系统的研究和开发2016-05-04 680
全部0条评论

快来发表一下你的评论吧 !
