

基于凌阳单片机的通用型语音控制系统
控制/MCU
描述
随着电子技术的迅速发展,家用电器及其他电子产品日趋人性化。为了实现语音处理和语音控制,这里设计了基于凌阳单片机的通用型语音控制系统。该系统主要用来完成语音识别、语音控制和语音播放等综合功能,使家用电器及其他电子产品实现语音的自动控制。目前国内还没有此类设计方案。该方案主要分为语音识别模块设计、语音播放模块设计和语音控制模块设计,只采用单片芯片就可实现语音处理和控制功能。此外,通过对一整套图形化的通用型语音集成软件进行开发,可使用户只需要输入语音素材的有关参数,即可实现代码的自动生成。下面介绍通用型语音控制系统的设计方案。
1、通用型语音控制系统设计方案
图1给出通用型语音控制系统方框图

语音识别模块的主要作用是完成语音辨识,本设计采用特定发音人识别模式。语音识别功能采用语音识别电路,并通过软件编程来实现。语音播放模块的主要作用是完成语音播放。语音播放功能采用语音播放电路,并通过软件编程来实现。语音控制模块的主要作用是使语音识别和语音播放实现自动控制。语音控制功能采用语音控制电路,并通过软件编程来实现。主控制器部分的主要作用是将语音控制系统嵌入到家电产品及其他电子产品中后,使电子产品的所有功能实现语音的自动控制。
1)凌阳单片机SPCE061A简介
SPCE061A是凌阳科技推出的一个16位结构的微控制器。CPU时钟频率为0.32~49.152 MHz,具有较高的处理速度,可使μ’nSPTM能够非常容易、快速地处理复杂的数字信号;拥有可编程音频处理;内置2 KWord的SRAM和32 KWord的FLASH;2个16位可编程定时器/计数器(可自动预置初始计数值),2个10位DAC输出通道,32位通用可编程输入/输出端口。它是数字语音识别应用领域产品中的一种比较经济的选择。
2) 通用型语音集成软件
开发了一套通用型语音集成软件,用户无需进行代码修改,只需要输入语音素材的相关参数,即可实现代码的自动生成。如图2所示,是通用型语音集成软件vO.1版的操作界面。

2、语音播放模块设计
语音处理大致可以分为A/D、编码处理、存储、解码处理以及D/A等。然而,麦克风输入所生成的WAVE文件,其占用的存储空间很大,对于单片机来说想要存储大量的信息显然是不可能的,而凌阳SPCE061A提出了解决的方法,即SACM-LIB,该库可将A/D、编码、解码、存储及D/A做成相应的模块,对应的每个模块都有其应用程序接口API,所以只需了解每个模块所要实现的功能及其参数的内容,然后调用该API函数即可实现该功能。
3、语音识别模块设计
1)语音识别原理
语音识别系统包括学习训练过程和识别过程2大部分,基本原理如图3所示。
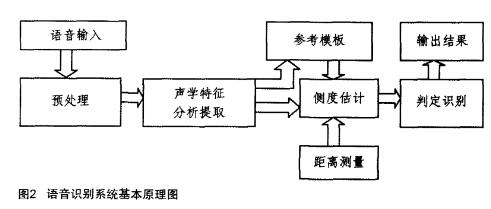
(1)预处理
包括预加重、加窗分帧、端点检测等处理过程,在预处理之前还有语音信号的数字化处理过程。其中,包括反混叠滤波、模/数转换自动增益等用以去除声门激励、口鼻辐射、高于1/2采样率的高频信号和噪声信号的影响,以实现语音信号的数字化。
(2)声学特征分析提取
经过预处理后的语音信号,要对其进行特征提取,即特征参数分析。该过程就是从原始语音信号中抽取能够反映语音本质的特征参数,以形成特征矢量序列。目前语音识别所用的特征参数主要有2种类型:线性预测倒谱系数(LPCC)和美尔频标倒谱系数(MFCC)。LPCC系数主要是模拟人的发声模型,未考虑人耳的听觉特性。MFCC系数考虑到了人的听觉特性,但要计算傅里叶变换将耗费大量宝贵的计算资源。因此,在嵌入式语音识别系统中一般都选用LPCC系数。语音特征提取是分帧提取的,每帧特征参数一般构成一个矢量。为此,有必要采用很有效的数据压缩技术方法对数据进行压缩。
(3)参考模板
参考模版时将一个或多个说话者多次重复的语音参数经过训练得到,它是声学参数模版,在系统识别使用前获得并存储起来。
(4)判定识别
模式识别是将输入的待识别语音特征参数与训练得到的参考语音模式进行逐一比较分析,获得的最佳匹配参考模式便为识别结果。目前常用的语音识别算法主要有动态时间规则、离散隐马尔可夫模型、连续隐马尔可夫模型及人工神经网。
2)语音识别系统原理和算法
在SPCE061A内置的8通道10位模/数转换器(analog to digital converter,ADC)中专门设置了一个只用于语音输入的通道MIC_IN,针对较弱信号的转换还设计了一个音频放大器(automation gain control,AGC)。对其自动增益控制放大后再进行A/D转换。实际上,可以把模/数转换器看作是一个实现模/数信号转换的编码器。ADC转换的原理是依次把设定在逐次逼近寄存器SAR中的数字送至10位DAC0中进行D/
A转换。DAC0的电压模拟量输出值与外部的电压模拟量输入值进行比较,以便尽快找出外部电压模拟量的数字量输出,其输出的模拟量VDAC0与采样后的输入电压值VIN相比较时可采用对半搜索法,即从SAR中最高有效位开始,根据比较的大小逐位确定其数码取“1”,其余位为“ 0”。语音识别算法的原理是:在训练过程中,从每个说话人发出的训练语句中提取相应的能充分描述各个说话人行为的特征矢量,这些特征矢量称为各说话人的模板。在测试阶段,从说话人发出的语音信号中按同样的处理方法提取测试模板,并与相应的参考模板相比较。由于说话人每次发音是变化的,测试模板和参考模板在时间尺度上不可能完全一致。
为了使二者能在时间等效点上加以比较,采用了动态时间规整法(DTW)。基本原理是在参考样本特征矢量序列A=[a1,a2,…,aM]与待识语音特征矢量序列B=[b1,b2,…,bN]之间用一种非线性规整技术实现匹配。从目前来看,基于动态时间规整匹配的DTW算法可能是一个最为小巧的语音识别算法,系统开销小,识别速度快,在小词汇量的语音命令控制系统中是一个非常有效的算法。
在训练阶段,用户将词汇表中的词依次说一遍,提取出每一帧采样数据的特征向量,并将特征向量作为模板存入模板库中。
在识别阶段,提取待识语音的特征向量,然后将其依次与模板库中的每一个模板进行相似度比较,并将相似度最高者作为结果输出。
4、语音控制模块设计
1)语音控制模块设计
语音控制模块硬件部分的功能采用设计的超小迷你电路板来完成。该硬件具有结构简单,成本低,体积小,易于家用电器嵌套等特点。各I/O口的分配及功能是IOB4~IOB7为识别到特定语音后向外部发出信号的常用口;IOB0~IOB1为向外发送信号的预留口;IOB2~IOB3是外部触发SPCE061的外中断触发口,当资源紧张时也可做为输出端口,如图4所示。

2)主程序流程
至此,整套系统完成了。在使用时,第一次要进行特定人语音识别,识别成功后,自动存入FLASH,以后就无需再训练,上电后自动加载进RAM中,然后进行识别,当识别到特定语音时,IOB就发出相应信号。
5、通用型语音集成软件的设计
1)集成软件的总体设计和所使用的工具
该方案的集成开发环境采用Visual Studio(VS)2005的VB.NET来设计。Visual Basic.NET是微软公司推出的全新集成开发环境VS.NET的重要成员之一,简单、易学、易用,很多新特性也正适应了新一代软件开发的需要,只要稍有点语言基础就可以很快掌握,进而精通。可视化的用户界面设计功能,把程序设计人员从繁琐复杂的界面设计中解脱出来;可视化编程环境的“所见即所得”功能,使界面设计如同积木游戏一般。
采用Visual Studio(VS)2005来编写此集成开发环境,极大地减轻了开发强度,缩短了开发周期,也使它的代码强度和可移植性大大提高。
2)通用型语音集成软件使用简介
通用型语音集成软件包括了语音识别模块设计、语音播放模块设计、语音控制模块设计的所有代码自动生成,如图2所示。开始可加入提示音,单击打开文件选项,选择想要播放的语音,后面方框打勾表示有此项功能;下面是5条语音的播放和识别,每一条功能相同,现简介如下:第一条语音提示功能同上,触发端口指辨识到该条语音后所触发的端口号,有IOB0~IOB7,电平指向外发信号是低电平还是高电平,有高电平“1”和低电平“0”两种情况可供选择,以适应不同的情况。训练成功语音提示指第一次训练时每训练成功1条指令的提示;训练失败语音提示指第一次训练时失败的提示;训练完成语音提示指第一次训练成功时的语音指令提示。
6、结语
该通用型语音控制系统结构简单,成本低,可扩充性强,开发周期短,可广泛应用于家用电器和其他各种电子产品中。如果该方案能成功应用,定会产生较好的经济效益和社会效益。
-
凌阳单片机开发实例2011-11-02 2323
-
基于凌阳16位单片机SPCE061A悬挂运动控制系统2011-03-07 3985
-
凌阳单片机语音报站系统2012-09-04 3592
-
凌阳单片机2013-03-20 5005
-
凌阳61A单片机语音识别控制2014-05-22 3467
-
基于凌阳单片机的语音信号实时采集2009-05-15 645
-
基于凌阳单片机控制的简易智能电动车设计2009-08-04 683
-
基于凌阳单片机的语音识别技术及应用2009-09-10 1017
-
凌阳通用单片机产品发布会2006-03-13 694
-
基于DSP与单片机的主从式智能轮椅语音控制系统2011-08-15 1184
-
基于凌阳单片机的语音照明开关设计2013-01-18 1705
-
基于单片机的温室控制系统2016-05-10 1171
-
凌阳单片机怎么样_凌阳单片机还有人用吗2018-04-10 15882
-
基于凌阳单片机的语音播报智能化燃气灶设计2023-10-12 492
-
基于凌阳单片机实现语音信号的实时采样与压缩2023-10-18 400
全部0条评论

快来发表一下你的评论吧 !
