

AI同传,首次登上国际级会议的舞台
电子说
描述
首次正式亮相国际级会议的AI同传,腾讯翻译君不仅仅代表了自己,还代表了整个AI智能翻译业界。近几天AI同传遭遇社会嘲笑,对此,腾讯翻译君负责人李学朝,讯飞胡郁有话说。
这几天又有一个AI火了。
没错,我们说的是在2018年博鳌论坛担任同声传译的腾讯同传。
这个事件让人想起了2017年“3·15晚会”打假人脸识别,让人脸识别技术一夜走红,也让众多人脸识别公司躺枪。一年后的今天,公众对人脸识别的接受度已经明显提升,技术在不断发展,人脸识别的商业化应用在不断产生。
当时,人脸识别公司云从科技用了题为“大势所趋,岂会因噎废食”的评论文章来表态,315晚会上的讨论,从一定程度上折射出公众对以人脸识别为代表的新兴人工智能技术的担忧。不过,任何新技术在刚刚萌芽时,都难免存在不完善的地方。而这,也将是AI同传技术将会延续的历程。
AI同传,首次登上国际级会议的舞台
2018年4月9日,博鳌亚洲论坛开幕,腾讯CEO马化腾静静地发了一条朋友圈。

“新尝试,多包涵。”
2018是博鳌论坛举办的第17年,这届会议在技术上最大的不同,就是正式启用AI作为同传。承担这个任务的,就是腾讯同传,它代表了所有的AI同传产品,首次站在了国际级会议的舞台上供世人检验。
这次腾讯翻译君将联合微信智聆(“腾讯同传”),为博鳌论坛的开幕式及部分核心论坛提供同声传译支持,包括同传双语内容会议现场投屏、同传内容手机小程序查看、翻译结果语音收听、同传记录回放等,服务的论坛主题涵盖亚洲经济预测、未来的生产,全球化的“下半场”、新一轮技术革命等领域。
这次任务重要性高(首次在开幕式及部分主论坛现场使用机器同传,一般都是人工和机器都有,以免在这些重要的场合机器出问题没办法救场)、难度高(首次公开支持讨论型会议,事先拿不到讲稿,全靠临场应对),开放程度也很高(支持多渠道查看和回放,包括小程序)。如果这显示不了腾讯的技术实力,那么至少,充分展示了腾讯的技术自信。
“这次AI同传的会议难度与可能出现坏的翻译例子,我们在会前都有预期。腾讯同传这套方案在博鳌之前已经历公司内外部近百场实战,技术持续升级,而且我们为博鳌也做了充分的准备,并用往届博鳌的视频进行回放测试验证,才拿出来呈现。“腾讯翻译君负责人李学朝告诉新智元:“博鳌创新选择AI同传并筛选决定用我们,给了我们很大鼓励,也体现出博鳌对创新的接受度。”
坏的翻译例子确实出现了,而公众和技术圈的反应,可能比腾讯自己预期的,稍稍猛烈一点。
掉链子和摆乌龙
根据公众号AI前线报道,本届博鳌亚洲论坛首次启用AI为现场嘉宾提供同传服务,仅仅一天,腾讯翻译君“掉链子”的消息就在网上散播开来。

“一带一路”被翻译成“一条公路和一条腰带”等不恰当表述。但是,关于这个翻译问题,腾讯官方给出了回应,这里暂且不表,看看你能不能看出什么端倪。
反应最大的,当然是受AI同传冲击最大的翻译界,有人庆幸,也不乏自嘲,“饭碗终于暂时保住了”。

从事翻译的知乎用户“翻一姐”道出了一部分翻译人士的心声。来源:AI前线
此外,还有消息传出,腾讯翻译团队不得不现场请求人类译员来救场。
对此,腾讯翻译君团队回应称这是一个“乌龙”:一直忙不迭的精心备考,哪有时间去请外援。
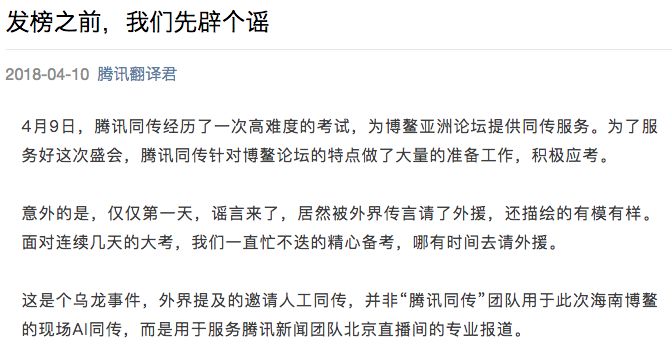
腾讯翻译君团队官方回应,外界提及的邀请人工同传是乌龙事件
腾讯官方回应:确实出现了错误,答错了几道题
腾讯翻译君官方也就本次一些翻译案例的技术问题进行了解读,表示“面对博鳌亚洲论坛复杂的语言环境和高大上的专业内容”,腾讯同传“确实出现了错误”,“答错了几道题”。
首先是以下流传最广的小程序截图,腾讯方面将其称之为“大面积单词无意义重复、大小写及字符混乱”现象。

出现这个问题,主要是中英双语切换频率的问题。当声源在两种语言之间不断转换时,后台中、英文识别引擎就会同时开始工作,这会导致两种识别引擎互相“掐架”,而翻译结果却只能选择一种语言进行输出,再加上对嘉宾每个语气词也做了精准的啊啊啊翻译,导致引发错误。
另一个需要承认的错误是下图中出现的“for for for × n”现象。

出现这种情况,主要是包括神经网络机器翻译在内的深度学习算法,在原理上或多或少都有一定不确定性,在特定的情况下有一定的概率引发翻译偏差。
嘉宾演讲内容中出现了口语中常见的重复内容,比如“for for for for”、 “that’s that’s that” ,相当于中文的“嗯嗯嗯嗯”“那个那个那个”,而翻译引擎恰好放大了这个重复,导致了翻译结果出现错误。
最后,对于上文提到的“一带一路”翻译,腾讯翻译君的错误也情有可原。腾讯方面表示,从直播截屏可以看出,发言者说的是“the road and belt”,而“一带一路”的正确说法应该是“the belt and road”,顺序不同,这才导致机器翻译按照字面意思进行解释了。
“对固定的词组,AI同传可以准确翻译发言者正确的表达,但是如果发言者的表达有偏差,机器翻译的准确度就要大打折扣。”腾讯翻译君团队告诉新智元。
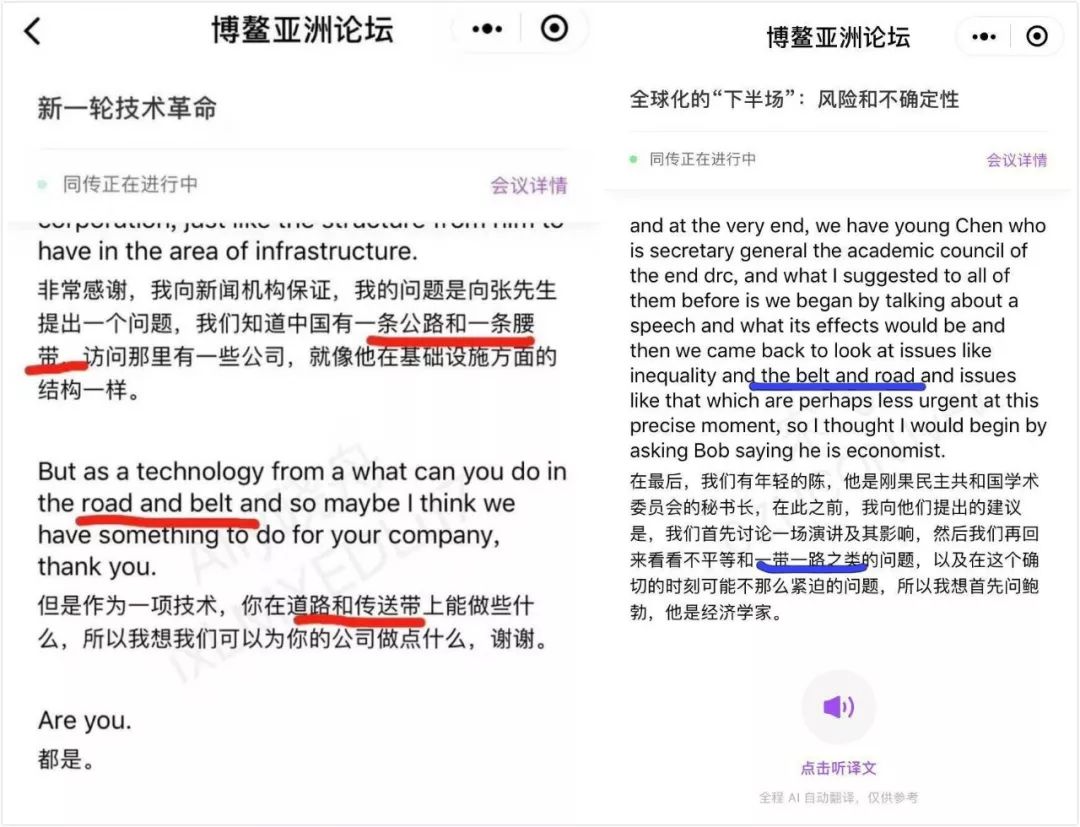
后期重新验证,当提供正确表述时,腾讯翻译君给出了正确的翻译(右图)
AI同传:人工智能的圣杯
同声传译被誉为人工智能的圣杯,因为这项任务需要极高的认知能力,就连人类也需要大量的训练和学习,付出艰苦卓绝的努力才能掌握。
在口译释意派学者塞莱斯科维奇和勒代雷写的书《释意翻译》中,他们将口译描述一个涉及意义理解、诠释和言语转化的三角过程。在口译过程当中,口译员需要理解源语言的意思,找到目标语言中具有相同含义的解释,并将其重新表达出来。而源语言的“意思”,是由说话者的声音所产生的语言涵义(linguistic meaning)和口译员自己对这一涵义进行的认知补充构成。
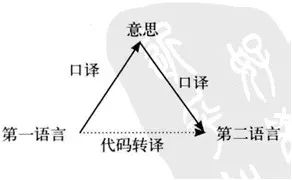
口译三角模型。来源:译聚网
塞莱斯科维奇提出了“口译三角模型”的假设:口译是一个三元过程:首先对源语言进行聆听,然后感知理解话语的意义,之后是对目标语言中所获意义进行重新表达,这也是口译中最重要的阶段。显然,口译的过程不是直截了当的,而是先“理解”后“重新表达”,是一个有不同阶段的连续过程。
一般而言,人类口译员是两人一组工作,一个人口译时,另一个人负责支援,比如查询文件和专业术语,跟踪前文提到的内容。口译要求高度的专注力,极其耗费脑力,因此每30分钟就会换人。良好的工作也取决于配合。
此次腾讯AI同传解决方案由两部分组成:腾讯翻译君+微信智聆。
其中,微信智聆团队成立于2011年,致力于开发语音人工智能技术,包括语音识别,语音合成,声纹认证,语音唤醒,远场阵列拾音等领域。目前公布的语音识别正确率可达到97%。
腾讯翻译君在2016年成立,是由腾讯MIG内部孵化的一个项目。腾讯翻译君与微信智聆结合成为腾讯同传是在2017年。
李学朝介绍说,博鳌亚洲论坛上实际的同传实现原理是,微信智聆把人声识别为文字,腾讯翻译君再把文本翻译成目标语言,再通过语音合成进行播报。
语音识别、机器翻译,单独拆开看,都已经出现了超越人类的结果。
2016年9月14日,微软语音团队在产业标准 Switchboard 语音识别基准测试中,实现了对话语音识别词错率(word error rate, 简称WER)低至6.3%的突破 ,创造当时该领域内错误率最低纪录。一个月后的10月18日,他们进一步将词错率降低至 5.9%,首次达成与专业速记员持平而优于绝大多数人的表现。这被认为是人工智能领域 2016年最大的突破性进展之一。
2017年,IBM和微软团队再次先后将语音识别的词错率降低至5.1%。如今,以智能音箱为代表,语音识别的商业化应用也迎来了一个爆发期。
机器翻译的拐点则发生在2016年底。谷歌宣布推出商用的谷歌神经网络机器翻译系统(GNMT),采用神经网络机器翻译(NMT)技术,大幅提升机器翻译的水平,最高将翻译准确率提高到 87%。这件事情的意义在于“商业部署”,意味着神经机器翻译技术投入大规模实用。
在刚刚过去的2018年3月,微软在机器翻译领域取得突破。他们研发的机器翻译系统在通用新闻报道的中译英测试集上,达到了人类专业译者水平。这是首个在新闻报道的翻译质量和准确率上媲美人类专业译者的翻译系统。微软的这个系统也采用了神经机器翻译技术。
至于语音合成,举一个比较有代表性的例子。2016年,谷歌DeepMind提出了一个叫做WaveNet的模型,采用深度学习方法,能够产生十分逼真的声音语音,听起来感觉与真人几乎无异。在训练过程中,神经网络会提取语音的基本结构,输入给定文本后,训练好的WaveNet模型会生成相应的语音波形,一次一个样本,从而实现比其他方法更高的精度。
2017年底,这项技术的改进版,被应用到了谷歌的智能助理Google Assistant(英语和日语)中。2018年3月,谷歌云平台推出云端 TTS(Cloud Text-to-Speech)功能,用户在文字转语音过程中,可以选择由 DeepMind 的 WaveNet 生成的高保真音频。

WaveNet深度生成模型,从头开始创建单个波形,每次生成一个样本,每秒生成16000个样本,各个声音之间无缝转换。
2018年3月,微软语音语言团队负责人、微软全球技术院士黄学东在接受新智元采访时表示,微软最新机器翻译系统“既是技术上的突破,也是工程上的突破,是技术和工程的完美结合,只有把过程中的每一件事情都做好,才能得到这样的结果。”
“接下来我们要做的,就是把语音识别和机器翻译结合到一起,在同声传译上取得突破。”
讯飞胡郁有话说
2016年,在乌镇举行的第三届世界互联网大会上,搜狗公司的CEO王小川就搜索引擎的未来发表了演讲。在演讲过程中,他演示了显示在屏幕上的实时机器翻译(如图所示),包括中文语音转录和英文翻译。
王小川说:“未来,同声传译员可能失业!”
然而讽刺的是,如上图所示,根据中文转录翻译成的英文似乎没有意义,看起来像机械地逐字翻译产生的乱码。
王小川给出了一个在安静的环境中搜狗语音识别技术可以达到的效果,也谈到了目前的“短板”:安静环境下可以实现 95%的准确度,甚至97%,但一旦出现噪音,例如当两个人同时说话时,准确度会大大下降。
机器似乎不知道如何识别噪音,今天的学术界也还没有找到解决办法。毕竟,对于理解语气的细微差别、讽刺、暗示、情感等等,人类的智能是不可或缺的,所有这些都超出了依赖大数据喂的、基于规则的算法。
科大讯飞执行总裁胡郁表示,这次腾讯AI同传的翻译结果,再次说明现在机器翻译离最终的理想情况,从核心技术上来说确实是有一定距离的。
“这些差距,是要通过好的产品设计来规避的。”胡郁说:“同时,这也证明了语音翻译绝对不是简简单单把语音识别文本、翻译、语音合成这几步简单组合在一起,就能得出一个很好的方案。”
要从问题的本质出发,真正理解翻译所面临的情况,设计真正将语音识别、文本翻译和语音合成融合在一起的、新的问题定义方式,才有可能解决这些对人类看来比较容易,是对机器来说很难的问题。
“其实我觉得这不仅仅是腾讯的问题,也是现在所有做翻译,包括科大讯飞在内,面临的最大的挑战。”胡郁说。
他还表示,从另外一个观点来看,当我们将很多技术应用在实际场景中时,不能再简单的利用互联网思维,用那些免费服务,用一开始效果比较差的产品来再逐步改进的方式来进行,因为很多时候在一开始,直接使用效果不好的人工智能,会导致大家对人工智能的怀疑,我们整个行业经不起这种错误的伤害。
“要把翻译服务的体验做好主要就是两个方面的因素,一个方面的就是整体的算法和数据,也就是我说的源头核心技术系统创新要是最好的。另外一个呢,就是在这样的情况下,要用很多的产品创新、微创新和应用创新来解决。”
“但是,我觉得最重要的,是要重新定义人工智能翻译的过程,绝对不能简简单单理解成,语音识别加文本翻译加语音合成这样功能的直接的叠加。”胡郁说:“我们正在尝试重新定义这个问题,希望从根本上解决这样的潜在的风险。只有加强机器对它所在,进行事情的理解能力,才有可能把这些问题彻底解决掉。”
“比如说机器要知道,那些口头的,各种嗯嗯啊啊的东西,不是需要翻译的内容,这样自然而然就不会产生这样的错误。”
小米旗下生态链企业香蕉出行的于亮表示,现场环境复杂,实验室环境永远无法模拟真正的现场环境。像口语、拾音、噪声、回声等问题,是实验室很难真实模拟的。“这些问题和挑战不是腾讯同传的问题,而是整个行业要面临和解决的问题,暴露出的问题越多,反而是好事。开拓、迭代、共享、包容也是互联网的精神。”
任重道远,继续前行
2017年中旬,牛津大学面向机器学习研究人员做了一次大规模调查,调查的内容是他们对 AI 进展的看法。这些研究人员预测,未来10年,AI 将在许多活动中超过人类,具体预测见下表:
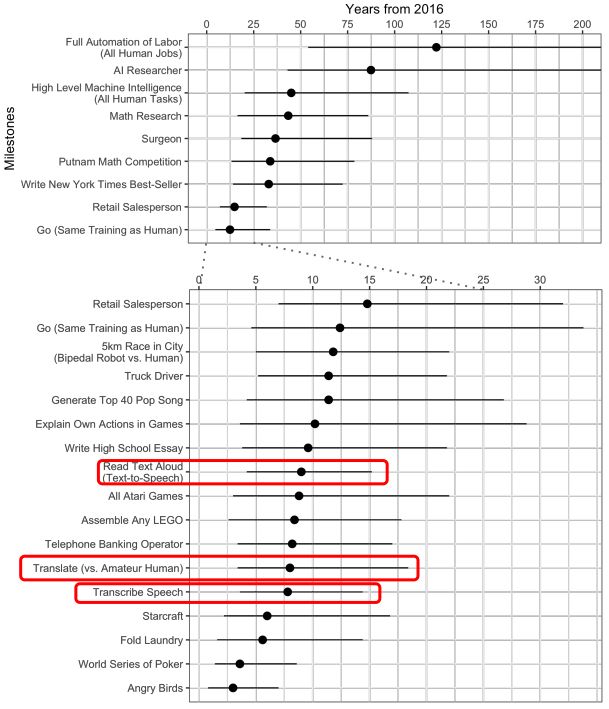
其中,红框标出了在复杂环境中进行AI同传的几项。机器学习研究人员的预测,相关技术超越人类还有7年的时间(预测是2017年中旬进行的)。
李学朝表示,有许多网友拿腾讯同传跟人工同传比较,这是不准确的,将腾讯同传与其他AI同传方案相比才有可比性。
也有媒体发出AI同传替代人工同传的观点,之前也看到同行有“同声传译终结者”的理念,“我们并不认为AI同传要消灭人工,而是认为两者是共同存在的,适用不同场景。”李学朝说。
“我更赞同AI同传与人工同传可以更好的人机协同,发挥各自所长帮助参会者更好理解多语会议内容。”
技术不断发展,AI同传与人类口译员并肩的那一天,终会到来。
-
2013澳门国际节庆用品与烟火文化博览会2013-05-30 0
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 0
-
近期人工智能大事件汇总:IBM押注AI AI同传在博鳌论坛上岗2018-04-14 8311
-
讯飞AI同传被指造假:同传译员亲自揭发,讯飞用人类翻译冒充AI2018-09-21 5917
-
科大讯飞的AI同传造假行为遭曝光!2018-09-25 4551
-
AI同传造假?科大讯飞市值蒸发500亿?2018-10-09 6669
-
讯飞上演真同传,假AI2019-03-12 1057
-
2019计算机视觉领域顶级会议的论文《非视距物体识别技术》被收录2019-03-22 2028
-
真人和AI竞技 人工智能会取代同传吗?2019-07-04 349
-
涂鸦荣获IoT云平台第一股 物联网平台终于要登上更大的舞台2021-03-08 1546
-
机器人登上舞台,引起不少话题2021-03-08 2102
-
OpenHarmony即将首次亮相国际顶级学术会议2024-04-13 266
全部0条评论

快来发表一下你的评论吧 !
