

基于双向块浮点量化的大语言模型高效加速器设计
描述
本文提出双向块浮点(BBFP)量化格式及基于其的LLMs加速器BBAL,通过双向移位与重叠位设计显著降低量化误差,提升非线性计算效率,实现精度、吞吐量和能效的显著优化,相关成果被国际顶级会议 DAC 2025 接收。
序言
在自然语言处理、文本生成和机器翻译等诸多任务领域,大型语言模型(Large Language Models, LLMs)已然取得了令人瞩目的显著进展,其强大的建模能力与泛化能力展露无遗。然而,随着模型参数规模的持续攀升,LLMs在计算与存储资源消耗方面呈现出急剧上升的态势,这严重制约了LLMs在移动设备、嵌入式系统等资源受限环境中的应用拓展。因此,如何在确保模型推理质量不受损的前提下,有效降低计算和存储开销,已然成为当前LLMs研究领域亟待攻克的难题之一。
量化技术(Quantization)因其在减少模型大小和计算复杂度方面的有效性,被广泛用于LLM的高效推理优化。传统的浮点量化方法(如FP16或FP8)虽然能够保持较高的精度,但由于其计算复杂度较高,难以在硬件层面高效执行。相比之下,整型量化(如INT8或更低的INT4)能够大幅降低计算资源需求,提高推理速度。然而,LLMs中的权重和激活值通常具有较大的数值范围,并且存在显著的离群值(outliers),这使得简单的整型量化容易造成信息丢失,从而导致严重的精度下降。为了解决这一问题,研究人员提出了更具适应性的量化方法,如Block Floating Point(BFP),该方法允许一组数值共享相同的指数部分,从而在保持相对较高精度的同时降低计算复杂度。
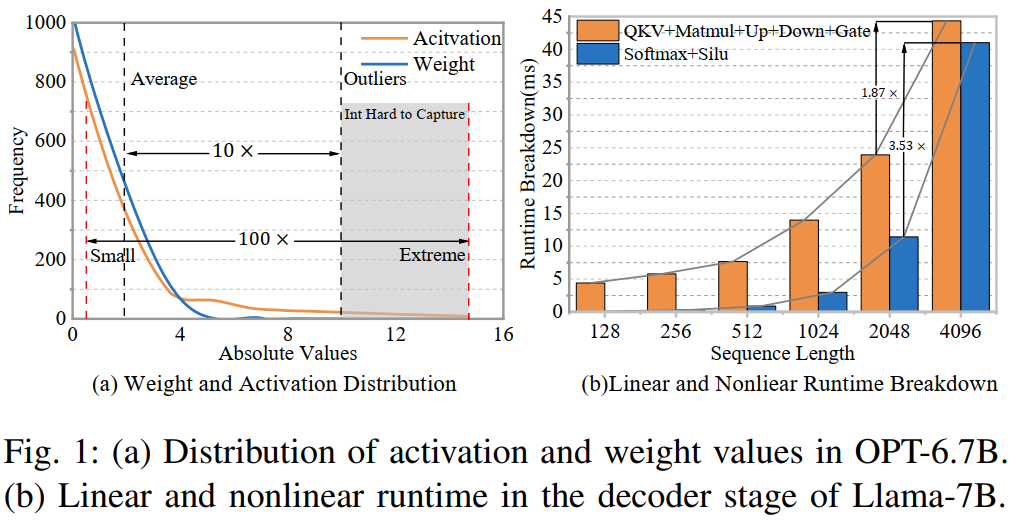
尽管BFP在理论上具备良好的计算效率,但其在实际应用中仍然面临诸多挑战。首先,BFP通常通过将所有数值对齐到该块内的最大指数,以确保数值范围的统一性。然而,这种策略会导致较小数值的信息丢失,进而引入额外的量化误差。其次,现代Transformer架构中包含大量非线性运算,如Softmax和SiLU等函数,这些运算通常依赖高精度的浮点计算。由于BFP的舍入误差较大,直接应用于非线性层可能会导致模型性能的显著下降。此外,现有的BFP加速器大多专注于线性层的优化,而忽略了非线性层的计算需求,这使得其在整体推理效率上的提升受到限制。
在此背景下,本文提出了一种名为双向块浮点(Bidirectional Block Floating Point, BBFP)的新型数据格式,旨在解决BFP在小值和中等值表示上的不足。BBFP通过引入标志位(Flag Bit)和重叠位(Overlap Bits),实现了双向移位机制,从而增强了对异常值的保护能力并显著降低了量化误差。此外,基于BBFP的特性,本文设计了一个高效的非线性计算单元,并最终构建了一个专为LLMs优化的加速器,命名为BBAL(Bidirectional Block Floating Point-based Accelerator for LLMs)。BBAL通过集成优化的处理单元(PE)阵列和非线性计算单元,实现了高效的LLMs推理,为边缘设备上的模型部署提供了新的思路和技术支持。
本文的主要贡献可以总结为以下三点:
BBFP数据格式:提出了一种新型量化格式BBFP,通过双向移位和重叠位设计,增强了对小值、中等值及异常值的表示能力,相较于传统BFP显著降低了量化误差。
非线性计算单元:基于BBFP的共享指数特性,设计了一个高效的非线性计算单元,采用分段查找表(Segmented Lookup Table)方法,降低了资源消耗和延迟,同时保持高精度。
LLMs加速器:构建了BBAL加速器,集成了基于BBFP优化的PE阵列和非线性计算单元,在精度、吞吐量和能效等方面实现了显著提升。
相关工作
2.1 量化技术
随着深度学习模型的参数规模不断扩大,计算和存储效率成为影响模型部署的关键因素。在众多优化策略中,量化技术因其在降低模型计算复杂度和存储需求方面的有效性,被广泛应用于大规模神经网络的优化。量化的基本思想是将高精度的浮点数(如FP32或FP16)转换为低比特的数值表示形式(如INT8、INT4甚至更低的BIT-NET),从而减少计算过程中的位宽需求,提高计算吞吐量,并降低内存带宽占用。对于大型语言模型(LLMs)而言,量化技术尤为重要,因为LLMs通常包含数十亿甚至上百亿个参数,直接使用高精度浮点运算会带来巨大的计算开销。
近年来,针对LLMs的量化技术取得了重要进展。例如,SmoothQuant通过平滑异常值分布来提高量化精度,而GPTQ则利用混合精度方法在低位宽下实现高效量化。尽管这些方法在一定程度上缓解了精度损失问题,但在极低位宽(如4位或更低)下,仍然难以完全满足LLMs的高精度需求。此外,量化方法通常分为训练后量化(Post-Training Quantization, PTQ)和量化感知训练(Quantization-Aware Training, QAT)。QAT通过在训练过程中引入量化约束,能够在低位宽下保持较高精度,但其训练成本对于参数量巨大的LLMs而言往往过高。因此,PTQ因其简洁性和高效性成为更实用的选择。本文采用PTQ方法,并提出BBFP以实现无需校准的权重-激活量化。
2.2 块浮点(BFP)
块浮点(BFP)是一种介于浮点数和定点数之间的量化格式,旨在结合两者的优势。在IEEE-754标准中,单精度浮点数由1位符号位(Sign Bit)、8位指数(Exponent)和23位尾数(Mantissa)组成,其值表示为(v = (-1)s × 1.m × 2e-ebias)。BFP通过让一组数据共享一个最大指数,将浮点运算简化为定点运算。例如,对于一个向量,其BFP表示可以写为:
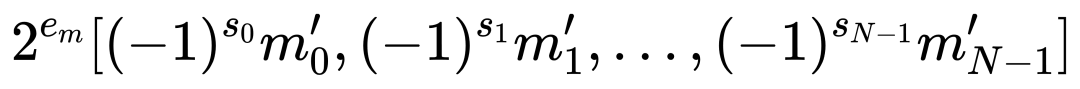
其中,( em ) 为块内最大指数,( m'i ) 为对齐后的尾数。这种设计显著提高了计算效率和内存密度,因为浮点数的点积运算可以简化为:
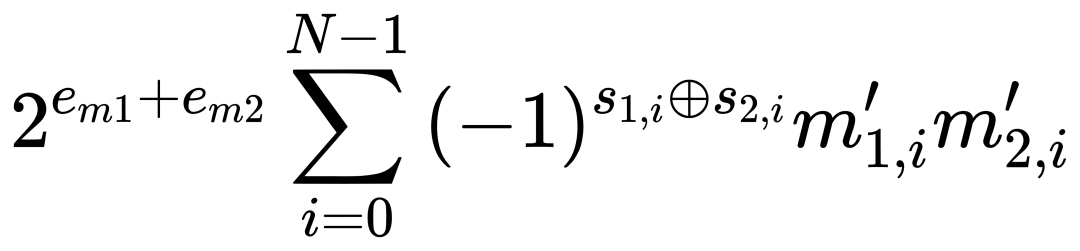
BFP的优势在于其能够在保持较高精度的同时降低计算开销。由于BFP在同一块内的所有数值共享指数,因此可以将浮点计算转化为定点计算,从而减少乘法和加法的计算复杂度。此外,BFP的动态范围比INT更大,使其在处理具有离群值的LLMs时更具优势。然而,标准BFP仍然存在一定的局限性。例如,在BFP中,所有数值都会被对齐到该块的最大指数,这意味着较小的数值会被右移,从而可能导致精度丢失。这种现象在LLMs的线性层中尤为明显,因为它会影响模型的整体推理精度。此外,BFP在非线性层(如Softmax、GELU等)中的应用也面临挑战,因为这些层通常涉及超越函数的计算,而BFP的舍入误差可能放大这些计算的不确定性,导致模型性能下降。因此,如何在保留BFP优势的同时降低其量化误差,成为当前研究的重点。
本文方法
3.1 双向块浮点(BBFP)数据格式
为了降低传统块浮点(BFP)量化过程中由于强制对齐所有数据到最大指数而引起的量化误差,本文提出了一种改进的量化数据格式——双向块浮点(Bidirectional Block Floating Point, BBFP)。BBFP的核心思想是通过引入一个1位标志位(flag bit)来区分高尾数(high mantissa)和低尾数(low mantissa),从而避免所有数值都必须对齐到最大指数。此外,BBFP还采用重叠位(overlap bits)机制,以减少因左移或右移操作带来的精度损失。
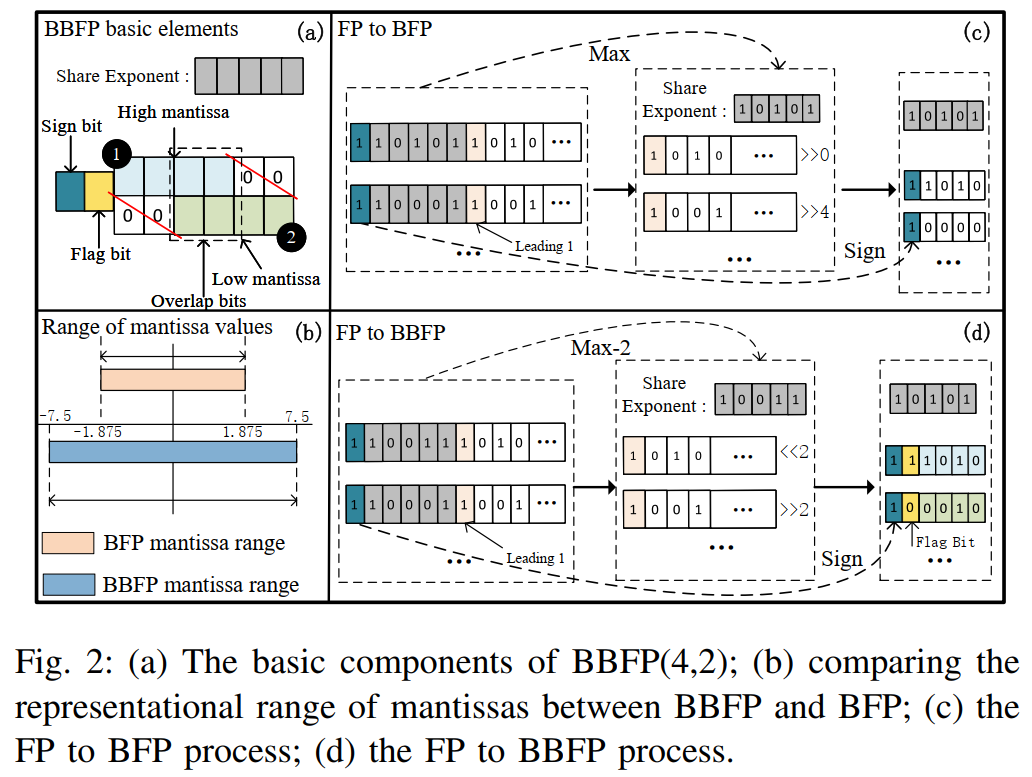
BBFP的结构如图2(a)所示,它由以下几个部分组成:
符号位(Sign Bit):1位,表示数值的正负。
标志位(Flag Bit):1位,用于指示尾数是否经过左移(高尾数)或右移(低尾数)。
共享指数(Shared Exponent):固定位数(本文实验中为5位),用于表示该块内所有数值的共享指数。
尾数(Mantissa):m位,表示数值的有效数字部分。
重叠位(Overlap Bits):o位,用于减少移位操作带来的精度损失。
BBFP的不同配置可以表示为BBFP(m,o),其中m表示尾数的位宽,o表示重叠位的位宽。例如,BBFP(4,2)表示尾数为4位,重叠位为2位。与传统的BFP相比,BBFP的尾数表示范围更广(如图2(b)所示),因为它允许一部分尾数向左偏移,而不是全部向右对齐到最大指数。
在FP16到BBFP(4,2)的转换过程中,原始FP16值首先被截断,然后根据共享指数与原始指数的关系决定是否左移或右移。具体而言,转换公式如下:
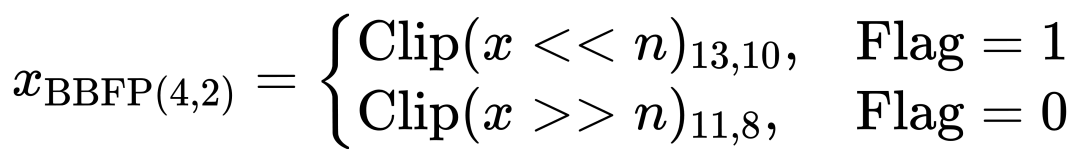
其中,Clip(⋅)a,b 表示从位a到b的截断操作,n 表示移位次数,Flag 是1位标志位,用于区分高尾数和低尾数。重叠位的引入使得左移时能够保留更多高位信息,从而减少截断误差。
BBFP的转换过程如图2(d)所示:首先确定共享指数(如Max - 2),然后根据原始指数与共享指数的大小关系调整尾数,并通过标志位记录移位方向,最后将尾数截断至指定位宽。BBFP的值表示为:
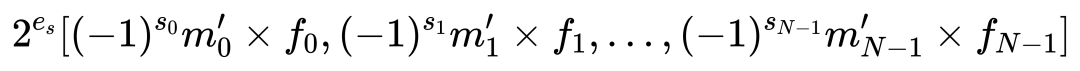
其中,移位因子 fi 定义为:
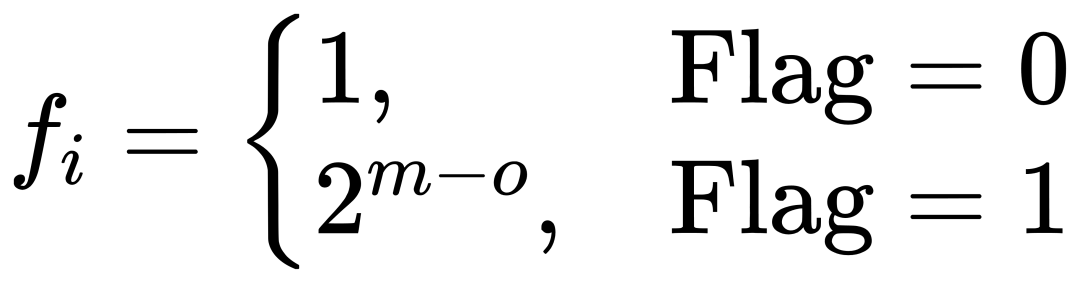
相比BFP,BBFP在相同尾数位宽下显著提升了表示范围(如图2(b)所示),从而更好地保护了小值和异常值。
3.1.1 BBFP的点积计算
BBFP保留了BFP将浮点运算转换为定点运算的特性,其点积计算公式为:
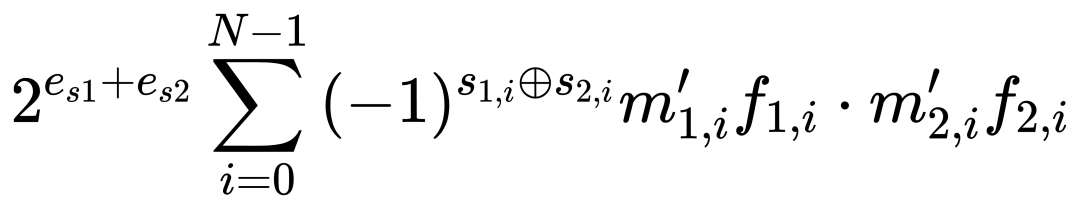
其中,f1,i 和 f2,i 根据标志位确定移位量。通过引入多路选择器和移位模块,BBFP将尾数表示范围扩展了4倍,同时保持了高效的定点计算特性。
3.1.2 量化误差分析
为了评估BBFP相较于传统BFP在量化误差方面的改进,本文对两种方法的量化误差进行了理论分析。假设使用最近舍入(round to nearest)策略,BFP的量化误差服从零均值分布,其方差 σ2 可以表示为:
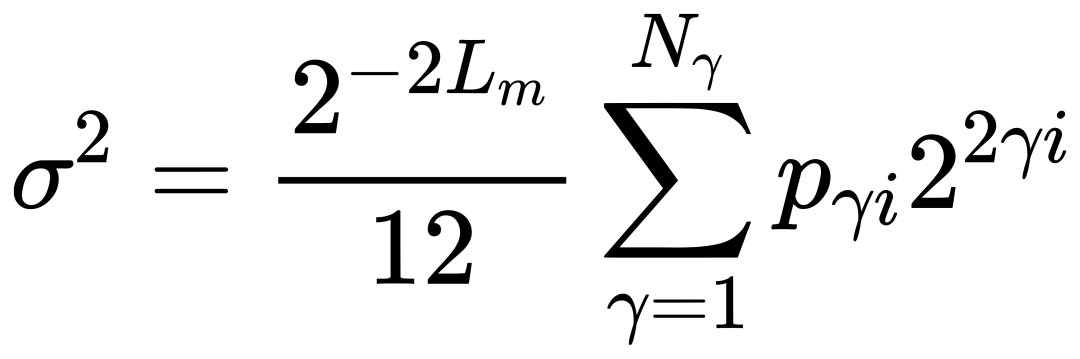
其中 Lm 表示尾数的长度,pγi 表示块指数的概率质量函数,Nγ=2LE 表示可用的块指数级别数量。当BFP和BBFP使用相同的尾数位宽时,唯一的区别在于 pγi 的分布情况。由于BBFP减少了对最大指数的依赖,其量化误差方差也会相应降低。
为了验证这一理论,本文进行了实验分析。图3展示了BBFP(4,2)与BFP4在不同共享指数策略下的量化误差对比。实验结果显示,当使用Max−3(即 Eshared = Max(E) - 3)作为共享指数时,由于左移操作可能导致最高位溢出,量化误差显著增加。相反,当使用Max−1(即 Eshared = Max(E) - 1)时,量化误差较低,但仍高于BBFP自适应选择共享指数的方式。
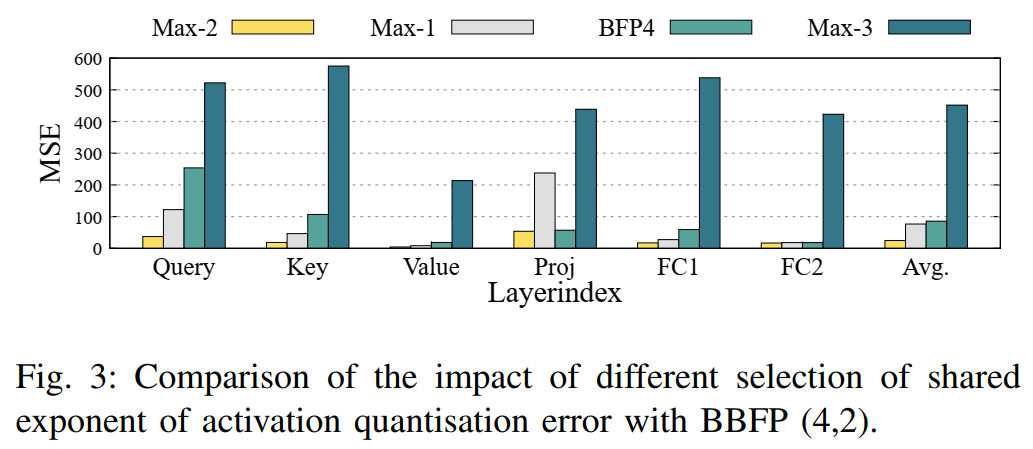
3.1.3 共享指数选择策略
BBFP的共享指数选择策略对量化误差有直接影响。本文提出了一种基于尾数位宽和重叠位数量的共享指数选择方法,即:
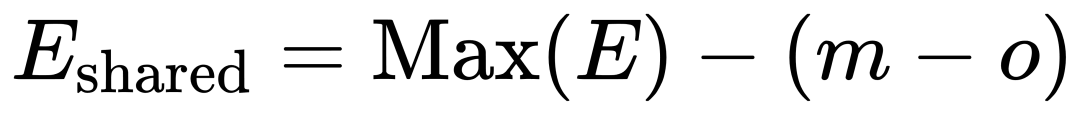
其中,Max(E) 表示该块内的最大指数,m 表示尾数位宽,o 表示重叠位数量。该公式的核心思想是,通过减少对最大指数的依赖,使部分数值的尾数向左偏移,而不是全部右移对齐。这样可以有效减少中小数值的精度损失。
3.1.4 重叠位宽度选择
重叠位的引入有助于减少移位操作带来的精度损失,但同时也增加了硬件开销。为了在量化误差和硬件成本之间取得最佳平衡,本文提出了一种基于模型特性和量化误差的重叠位选择方法。具体而言,该方法通过调整算法1中的开销权重,可以在准确率优先或硬件成本优先之间进行权衡。

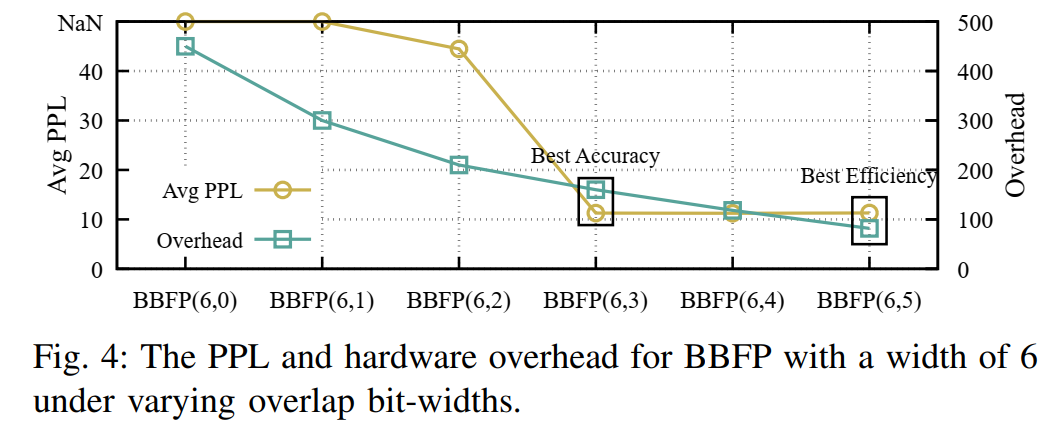
图4展示了在BBFP(6,0)到BBFP(6,5)不同重叠位配置下的模型困惑度(PPL)和硬件开销。实验结果表明,适当增加重叠位的数量可以显著降低量化误差,提高模型精度。然而,过高的重叠位数量会增加硬件资源消耗,因此需要根据实际应用场景进行优化。
3.2 数据格式驱动的硬件设计
基于BBFP的特性,本文设计了一种高效的硬件架构,包括优化的乘法累加(Multiply and Accumulate, MAC)模块和非线性计算单元。
3.2.1 线性计算单元
1. 块内乘法
BBFP的块内矩阵乘法分为共享指数加法和尾数乘法。尾数乘法公式为:
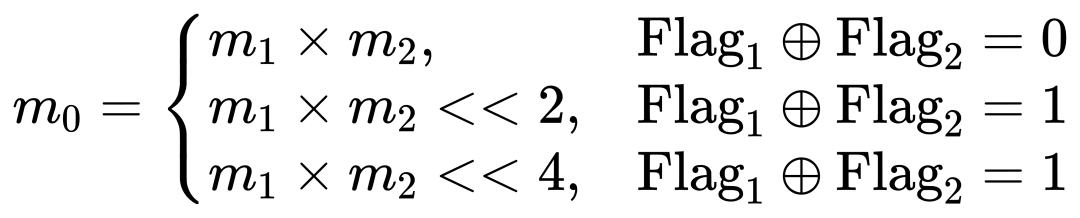
对于BBFP(4,2),两个4位尾数的乘法通过4位乘法器实现,随后进行移位操作得到12位结果(图5(a))。为提高内存密度,移位后的零位被移除,并用2位标志表示零元素位置,最终输出为包含2位标志、1位符号和8位尾数的BBFP格式。
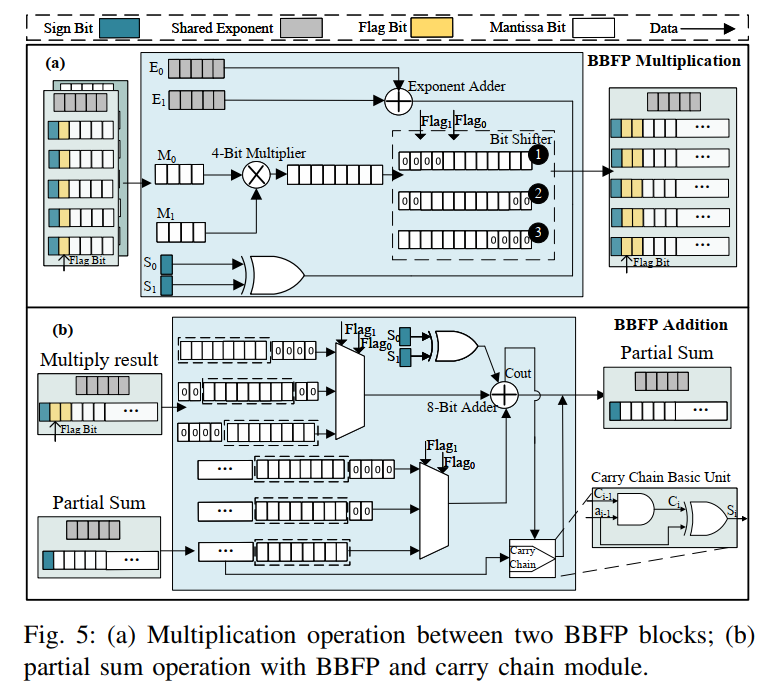
2. 部分和加法
块内乘法后需进行部分和加法。BBFP的计算结果具有规则的位级稀疏性,本文利用稀疏加法器减少加法器位宽(图5(b))。例如,用8位加法器和n位进位链替代 ( 12+n ) 位加法器,其全加器表达式为:
![]()
在稀疏模式下,加法器可简化为:
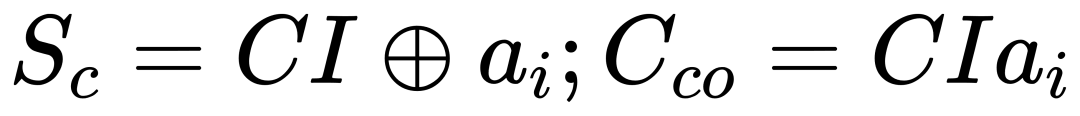
通过这种优化,例如用8位加法器和4位进位链替代12位加法器,可减少15%的资源消耗。表I展示了不同数据格式下MAC单元的面积和内存效率,BBFP(6,3) 在面积更小的情况下提供了比BFP8更高的表示能力。
3.2.2 非线性计算单元
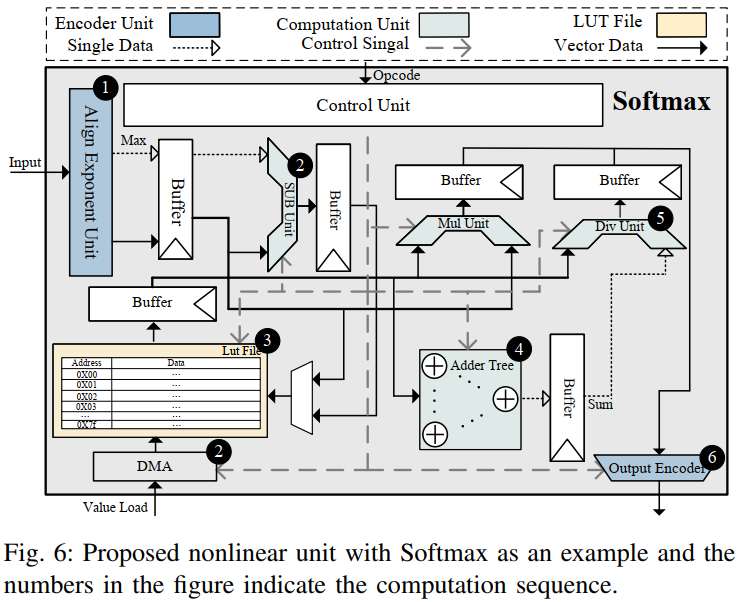
1. 分段查找表
BBFP利用共享指数特性,将函数值按指数分段存储于外部内存。例如,5位指数可生成 ( 25× 2 ) 个子表。在对齐阶段计算共享指数后,加载对应子表,并直接以尾数作为查找地址,避免了浮点LUT的额外映射开销。
2. 流水线设计
为提高吞吐量并掩盖LUT加载延迟,非线性计算单元采用流水线架构,各模块配备缓冲区。单元支持多种超越函数(如Sigmoid、Softmax),通过可调计算顺序和冗余单元实现灵活性。
3. INT计算
数据通过对齐模块转换为BBFP后,LUT中的条目也预转换为BBFP格式,确保计算一致性。图6展示了以Softmax为例的非线性单元流程。
3.2.3 LLMs加速器
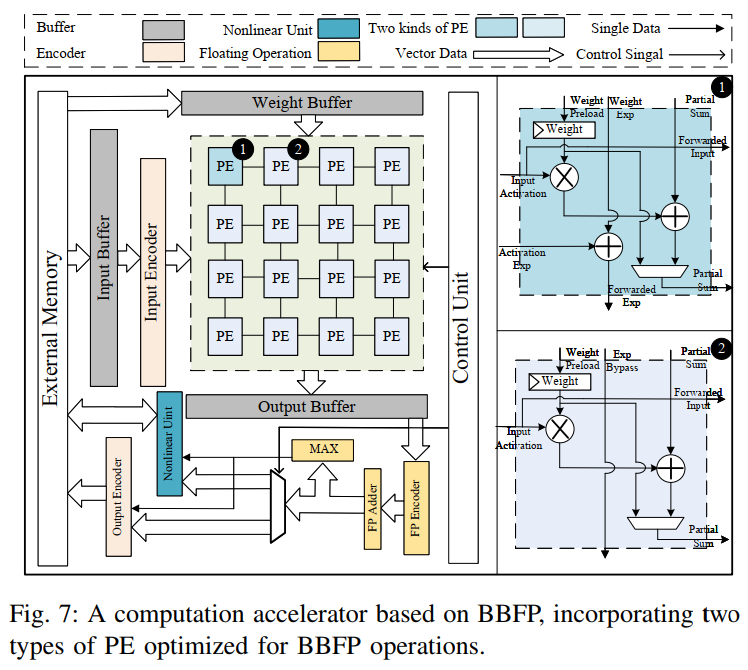
基于上述模块,本文构建了BBAL加速器(图7),其核心包括:
PE阵列:基于BBFP优化的处理单元阵列,支持高效线性计算,包含共享指数加法器和旁路单元两种版本。
非线性计算单元:集成上述设计,实现低成本非线性操作。
其他模块:输入编码器、缓冲区、输出编码器等,支持完整推理流程。
3.3 实验评估
3.3.1 非线性单元的精度与效率分析
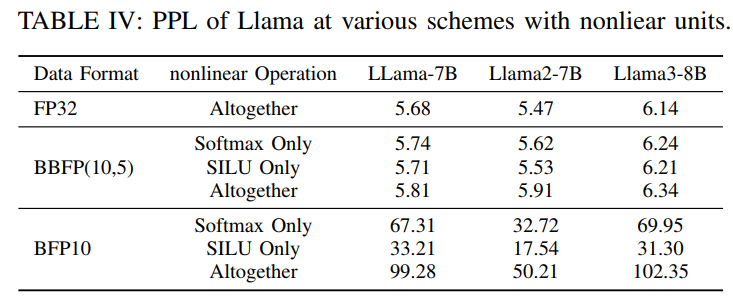
为了验证BBFP在非线性层中的有效性,本文在Llama-7B、Llama2-7B和Llama3-8B模型上进行了实验,比较了基于BBFP(10,5)和BFP10的非线性计算单元在困惑度(Perplexity, PPL)方面的表现。实验结果如表IV所示,可以看出,采用BBFP(10,5)量化策略的模型在使用Softmax和SiLU非线性函数时,PPL的增长幅度远低于BFP10方案。例如,在Llama-7B模型上,使用BFP10进行Softmax计算会导致PPL增加至67.31,而BBFP(10,5)仅使PPL增加至5.74,接近FP32基线水平。同样,在Llama2-7B和Llama3-8B模型上,BBFP(10,5)的PPL增长幅度也明显小于BFP10,表明BBFP在非线性层计算中能够有效减少量化误差,保持较高的模型精度。
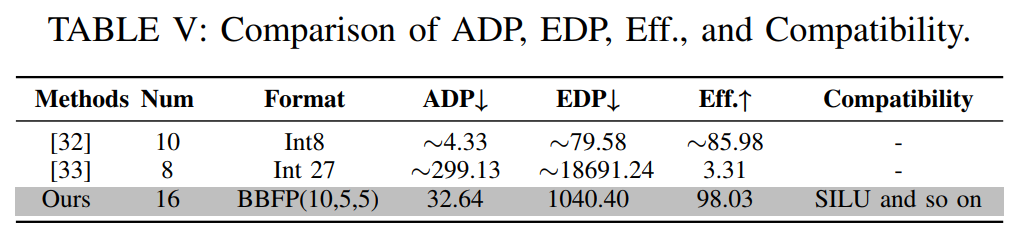
除了精度分析,本文还评估了所提出的非线性计算单元的能效比。表V展示了不同方法在面积延迟乘积(Area Delay Product, ADP)、能量延迟乘积(Energy Delay Product, EDP)以及计算效率(Throughput/(Area×Power))等方面的对比。实验结果表明,尽管BBFP(10,5)的ADP和EDP略高于低精度近似算法,但其计算效率显著优于现有方法。这是因为BBFP(10,5)采用了分段指数动态查找策略,减少了昂贵的片上存储需求,同时保持了较高的计算兼容性。此外,由于BBFP的尾数表示范围更广,其在非线性计算中的精度损失较小,从而减少了对额外校正电路的需求,进一步降低了硬件开销。
3.3.2 线性单元的面积与精度对比
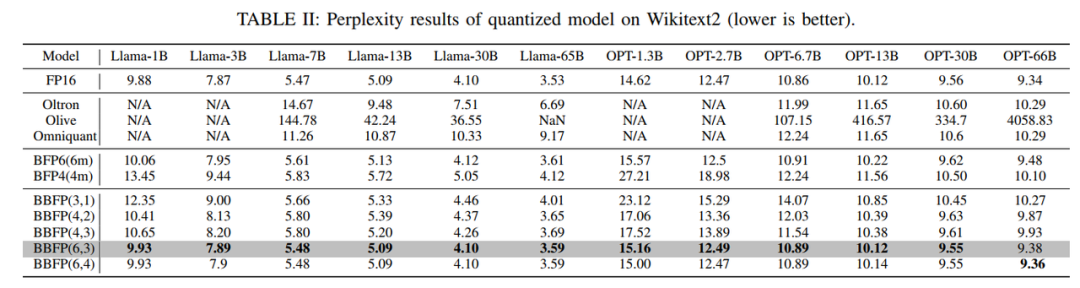
为了评估BBFP在线性层中的性能,本文在WikiText2数据集上测试了不同量化策略对Llama和OPT系列模型的影响。表II展示了FP16基线模型、BFP4、BFP6以及不同BBFP配置的PPL结果。实验结果显示,BBFP在保持较低PPL的同时,能够有效减少量化误差。例如,BBFP(4,2)在Llama-7B上的PPL为5.80,而BFP6的PPL为5.61,两者差距较小,但BBFP(4,2)的计算效率更高。此外,BBFP(6,3)在Llama-7B上的PPL仅为5.48,与FP16基线(5.47)几乎持平,显示出其在高精度场景下的优越性。
为了进一步分析BBFP的硬件成本,表III列出了不同量化策略下处理单元(Processing Element, PE)的面积消耗。实验结果表明,BBFP的PE面积略高于BFP4,但相较于BFP6仍然具有优势。例如,BBFP(3,1)的PE面积仅为77.69 µm²,而BFP4的PE面积为215.23 µm²。这是因为在BBFP中,尾数的高位和低位分别对应不同的移位方向,使得乘法和加法运算的位宽需求有所降低。此外,BBFP的1位标志位虽然增加了少量存储开销,但由于其在精度上的提升,使得整体硬件成本得到了优化。

3.3.3 吞吐量与准确率的平衡
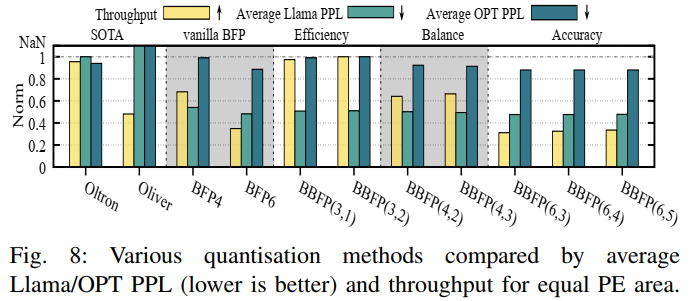
为了评估不同量化策略在吞吐量和准确率之间的平衡,本文在相同PE面积条件下进行了比较分析。图8展示了不同量化方法在Llama和OPT系列模型上的平均PPL和吞吐量表现。可以看出,BBFP(3,1)和BBFP(3,2)在保持较高吞吐量的同时,其PPL远低于Oltron和Olive等基于离群值感知的量化方法。此外,BBFP(3,1)和BBFP(3,2)的吞吐量与Oltron相当,但准确率更高,这证明了BBFP在吞吐量和准确率之间取得了较好的平衡。
3.3.4 能源效率分析
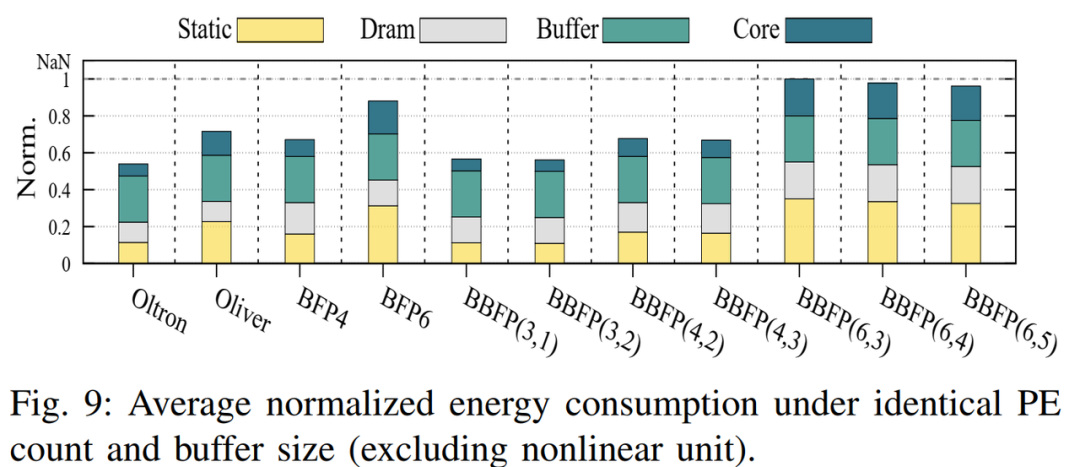
除了吞吐量和准确率,能源效率也是衡量加速器性能的重要指标。图9展示了相同PE数量和缓冲区大小下的能耗。BBFP(3,1)相较BFP4降低13%的能耗,主要得益于静态和核心能量的减少。BBFP与相同位宽BFP的能耗增幅在5%以内,额外标志位对DRAM功耗影响较小。
结论
本文提出了一种改进的块浮点量化方法——双向块浮点(Bidirectional Block Floating Point, BBFP),并基于该方法设计了一款高效的大型语言模型(LLMs)加速器BBAL。BBFP通过引入1位标志位和重叠位机制,有效降低了传统块浮点(BFP)量化过程中因强制对齐所有数据到最大指数所带来的量化误差。此外,BBFP还优化了共享指数选择策略,使部分数值的尾数向左偏移,避免了中小数值的精度损失。基于BBFP的特性,本文进一步设计了一种高效的非线性计算单元,该单元结合了基于查找表(Look-Up Table, LUT)的计算方法,能够在保持较高精度的同时降低计算开销。最终,本文构建了一个完整的LLM加速器架构BBAL,其中包含了优化的处理单元(Processing Element, PE)阵列和非线性计算单元。实验结果表明,BBAL在保持与现有加速器相当的计算效率的同时,其模型精度提升了22%;而在保持相近精度的情况下,其计算效率提高了40%。
-
从版本控制到全流程支持:揭秘Helix Core如何成为您的创意加速器龙智DevSecOps 2024-11-26
-
回旋加速器原理 回旋加速器的影响因素2024-01-30 9049
-
粒子加速器的加速原理是啥呢?2023-12-18 5138
-
基于FPGA的Wide&Deep模型加速器解决方案2023-09-13 577
-
FPGA加速器支撑ChatGPT类大语言模型创新2023-09-04 1461
-
英特尔媒体加速器参考软件Linux版用户指南2023-08-04 733
-
#硬声创作季 电子制作:磁性加速器Mr_haohao 2022-10-19
-
一个模型带你了解#回旋加速器原理jf_49445761 2022-08-28
-
基于Fast Model的加速器软件开发2022-07-29 3550
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6235
-
采用控制律加速器的Piccolo MCU2019-07-26 2590
-
工具包和Eval板帮助加速加速器应用2017-09-14 1102
全部0条评论

快来发表一下你的评论吧 !
