

基于算力魔方的智能文档信息提取方案
电子说
描述
作者:算力魔方创始人/英特尔创新大使刘力
一,引言
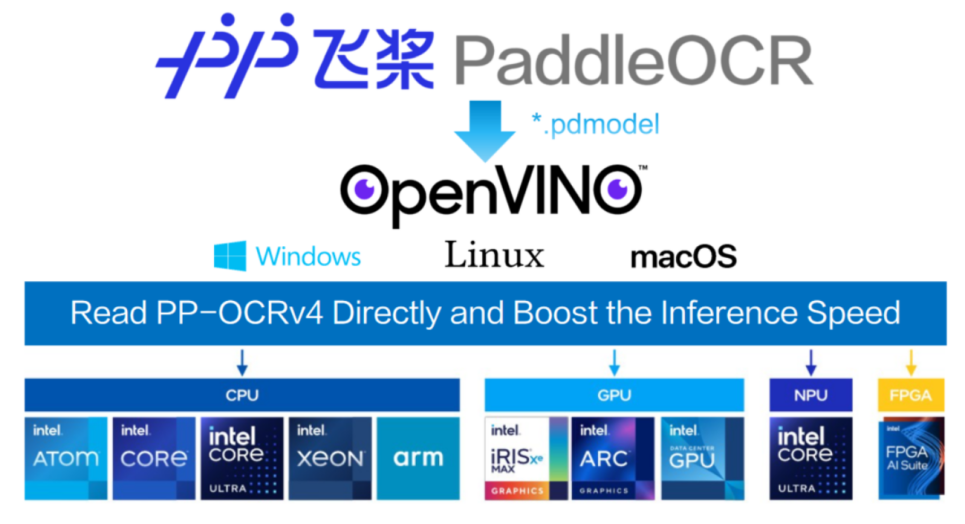
在大数据时代,文档数据量急剧增加,传统的手工方式已无法满足快速获取有效信息的需求。深度学习技术,尤其是计算机视觉领域的光学字符识别(OCR)技术的进步,使得自动化和智能化的文档信息提取成为现实。本方案结合了Intel OpenVINO平台的性能优化优势与百度飞桨(PaddlePaddle)提供的PP-OCRv4模型,旨在开发一款高性能、高精度的智能文档处理系统。
算力魔方®是一款可以DIY的迷你主机,采用了抽屉式设计,后续组装、升级、维护只需要拔插模块。通过选择不同算力的计算模块,再搭配不同的 IO 模块可以组成丰富的配置,适应不同场景。
性能不够时,可以升级计算模块提升算力;IO 接口不匹配时,可以更换 IO 模块调整功能,而无需重构整个系统。
本文以下所有步骤将在带有英特尔i5-1235U处理器的算力魔方®上完成验证。
二,实施步骤
(一)准备工作:
安装必要的软件包Anaconda(https://www.anaconda.com/download),然后用下面的命令创建并激活对应的开发环境:
conda create -n OCR python=3.11 #创建虚拟环境
(二)模型部署:
下载并加载预训练的PP-OCRv4模型,利用OpenVINO进行优化转换,以更好地适配目标硬件平台。
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar && tar -xvf ch_PP-OCRv4_det_infer.tar # 下载PP-OCRv4的检测模型
将优化后的模型保存至PP-OCRv4_OpenVINO 文件夹目录,确保路径正确无误。运行部署脚本:
(三)运行脚本
要快速开始使用 PP-OCRv4_OpenVINO 项目,请执行以下步骤:
Python main.py #运行python代码调用推理
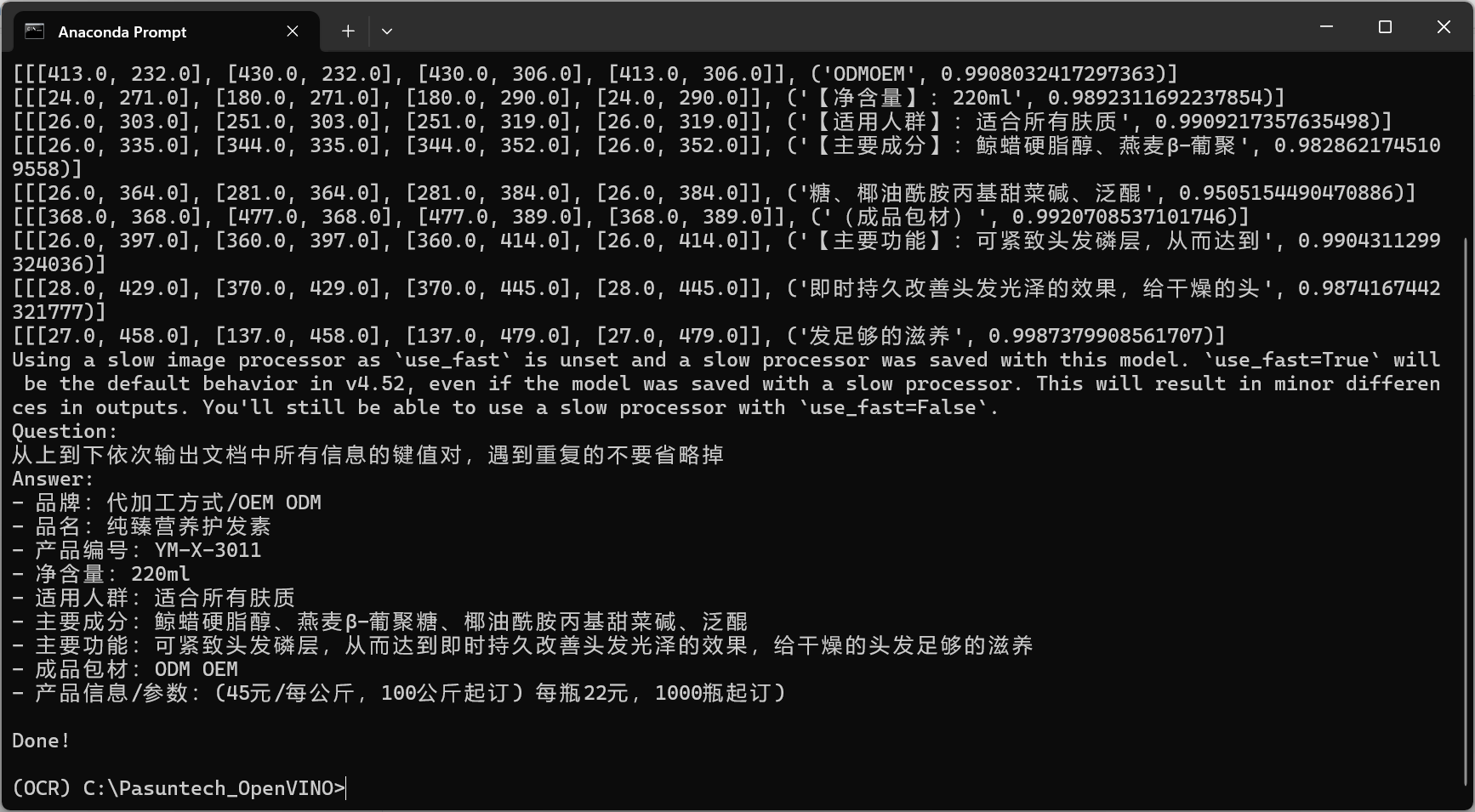
后续程序会将识别到的文本结果直接打印到控制台:
视频链接:基于算力魔方的智能文档信息提取方案 (qq.com)
三,结论
本文介绍了一种利用OpenVINO工具套件、PP-OCRv4模型和Qwen2.5-VL视觉语言模型构建的智能文档信息提取解决方案。该方案结合了尖端的视觉识别技术和经过优化的计算性能,目的是提高文档处理的效率和精确度,适用于包括财务报表分析、合同审查在内的多种场景。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取2024-08-14 1111
-
【「时间序列与机器学习」阅读体验】时间序列的信息提取2024-08-17 981
-
从堆算力到用算力,宁畅用精装算力,助力产业打造智能化摩天大楼脑极体 2025-01-22
-
信息提取2017-09-29 4041
-
关于频率变化的正弦波幅值信息提取2018-12-19 4336
-
NLPIR在文本信息提取方面的优势介绍2019-09-12 1412
-
基于HTMLParser 信息提取的网络爬虫设计Design2009-06-03 1206
-
基于VB6.0的点阵字模信息提取方法2010-07-16 948
-
短时傅立叶变换在阵列声波信息提取中的应用2016-01-15 780
-
脉冲多普勒雷达识别中的信号调制信息提取2016-12-24 861
-
基于FPGA的图像信息提取设计及仿真2017-11-17 2785
-
一种自适应网页结构化信息提取方法2021-05-08 1060
-
算力魔方IO扩展模块介绍 网络篇12025-04-09 1698
-
基于算力魔方与PP-OCRv5的OpenVINO智能文档识别方案2025-06-12 2052
全部0条评论

快来发表一下你的评论吧 !
