

强化学习究竟是什么?它与机器学习技术有什么联系?
电子说
描述
强化学习在当今世界可谓是日渐流行,让我们来看一看关于强化学习你不得不知道的5件事。
强化学习是当今社会最热门的研究课题之一,而且其热度正与日俱增。让我们一起来学习下关于强化学习的5个有用知识点。
▌1.强化学习究竟是什么?它与机器学习技术有什么联系?
强化学习(Reinforcement Learning)是机器学习的一个分支,它的原理是:在交互环境中,智能体利用自身的经验和反馈,通过试验和错误经验来进行学习。
有监督学习和强化学习都会明确指出输入和输出之间的映射关系,但不同点在于,有监督学习给智能体的反馈是执行正确任务的行为集合,而强化学习反馈的则将奖励和惩罚转为积极和消极行为的信号进行反馈。
对于无监督学习,强化学习的目标显得更加难以实现。无监督学习的目标仅仅是找到数据之间的相似和不同,而强化学习的目标却是找到一个能最大化智能体总累计奖励的模型。
强化学习模型中涉及的基本思想和元素见下图:
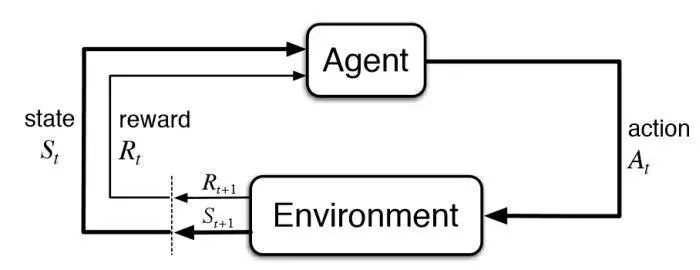
▌2.如何确定一个基本的强化学习问题?
描述强化学习问题的几个关键元素是:
环境:智能体所处的物理世界;
状态:智能体目前的状态;
奖励:从环境中得到的反馈;
方案:将智能体状态映射到行动的方法;
价值:智能体在特定状态下执行某项行动获取未来的奖励。
一些游戏可以帮助我们很好的理解强化学习问题。以PacMan游戏为例:在这个游戏中,智能体(PacMan)的目标就是在避免与鬼相遇的情况下,尽量在网格中吃到更多的豆子。网格世界就是智能体的交互环境,如果PacMan吃到了豆子就接受奖励,如果被鬼杀死了(游戏结束)就接受惩罚。在该游戏中,“状态”就是PacMan在网格中的各个位置,而总累计奖励就是赢得比赛的胜利。
为了得到最优的方案,智能体既需要探索新的状态,又要同时尽量取得最多的奖励。这就是所谓的“探测与开采的权衡”问题。
马尔可夫决策过程(MDP)是所有强化学习环境的数学框架,几乎所有强化学习问题都可以使用MDP来搭建模型。一个MDP过程包含一个环境集合(S),每个状态中包含一个可能的行动集合(A),还包含一个实值奖励函数R(s)和一个转移矩阵P(s',s | a)。不过,现实世界的环境中,环境动态的先验信息可能是未知的,在这种情况下,运用“不理解环境强化学习”算法(model-free RL)去进行预测会更加方便、好用。
Q-learning模型就是一种应用广泛的不理解环境强化学习模型,因此可以用它来模拟PacMan智能体。Q-learning模型的规则是,在状态S下执行行动a,不停更新Q值,而迭代更新变量值算法就是该算法的核心。

Figure 2: Reinforcement Learning Update Rule
这是利用一个深度强化学习实现PacMan游戏的视频:
https://www.youtube.com/watch?v=QilHGSYbjDQ
▌3.最常用的深度学习算法原理是什么?
Q-learning和SARSA是两种最常见的不理解环境强化学习算法,这两者的探索原理不同,但是开发原理是相似的。Q-learning是一种离线学习算法,智能体需要从另一项方案中学习到行为a*的价值;SARSA则是一种在线学习算法,智能体可从现有方案指定的当前行为来学习价值。这两种方法都很容易实现,但缺乏一般性,因为它们无法预估未知状态的值。
一些更加高级的算法可以克服这个问题,如:Deep Q-Networks(其原理为利用神经网络来估计Q值)算法,但DQN算法只能应用在离散的低维动作空间中;DDPG(深度确定性策略梯度算法)则是一个理解环境的、在线的算法,它基于行动者-评论家(Actor-Critic,AC)框架,可用于解决连续动作空间上的深度强化学习问题。
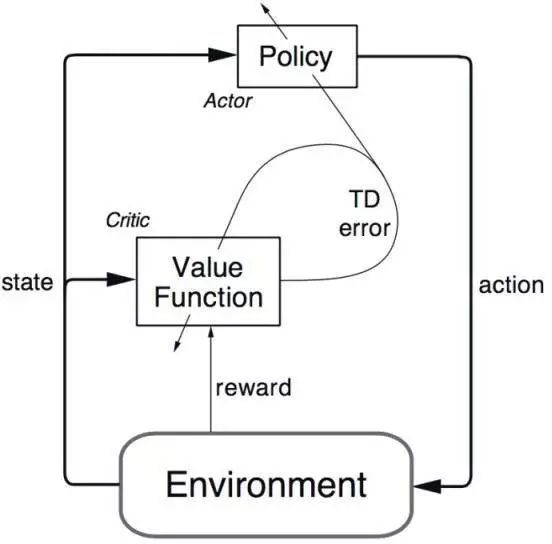
▌4.强化学习有哪些实际应用?
由于强化学习需要大量的数据,因此它最适用于模拟数据领域,如游戏、机器人等。
强化学习广泛应用于设计游戏中的AI玩家。AlphaGo Zero在传统中国游戏围棋中打败了世界冠军,这是AI第一次击败现实中的世界冠军。AI还在ATARI游戏、西洋双陆棋等游戏中有出色的表现。
机器人和工业自动化领域中,深度学习也被广泛应用,机器人能够为自己搭建一个高效的自适应控制系统,从而学习自己的经验和行为。DeepMind关于“带有异步策略更新的机器人操纵的深度强化学习”就是一个很好的例子。
观看这个有趣的演示视频video(https://www.youtube.com/watch?v=ZhsEKTo7V04&t=48s)
强化学习的其他应用包括:文本摘要引擎、从用户交互中学习并随时间改进的(文本、语音)对话代理、医疗保健领域的最优治疗政策、基于强化学习的在线股票交易代理。
▌5.我该如何开始强化学习?
读者可以从以下链接中了解更多关于强化学习的基本概念:
《Reinforcement Learning-An Introduction》——本书由强化学习之父Richard Sutton和他的博士生导师Andrew Barto共同撰写。该书的电子版以在 http://incompleteideas.net/book/the-book-2nd.html找到。
由David Silver提供的Teaching material视频课程可供读者很好的了解强化学习的基础课程:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
Pieter Abbeel 和 John Schulman 的视频technical tutoria也是不错的学习资料:http://people.eecs.berkeley.edu/~pabbeel/nips-tutorial-policy-optimization-Schulman-Abbeel.pdf
开始构建和测试RL代理
若想要开始学习搭建和测试强化学习的智能体,Andrej Karpathy的博客This blog中详细讲述了如何用原始像素的策略梯度来训练神经网络ATARI Pong智能体,并提供了130行Python代码来帮助你建立你的第一个强化学习智能体:http://karpathy.github.io/2016/05/31/rl/
DeepMind Lab是一个开源的3D游戏式平台,它为机遇智能体可以的人工智能研究提供丰富的模拟环境。
Project Malmo是另一个提供基础AI研究的在线平台:https://www.microsoft.com/en-us/research/project/project-malmo/
OpenAI gym则是一个用于构建和比较强化学习算法的工具包:https://gym.openai.com/
-
反向强化学习的思路2019-04-03 0
-
图解:IGBT究竟是什么?2020-08-10 0
-
深度强化学习实战2021-01-10 0
-
电感饱和究竟是什么2021-03-11 0
-
分贝究竟是什么?如何去理解它?2021-05-31 0
-
那uMCP究竟是什么?它与eMCP有什么联系?2021-06-18 0
-
retain,copy与assign究竟是有什么区别呢2021-09-30 0
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28208
-
强化学习新方法,机器人究竟是怎么学习新动作的呢?2018-04-13 9916
-
人工智能机器学习之强化学习2018-05-30 1459
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 17830
-
一文详谈机器学习的强化学习2020-11-06 1843
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 990
-
什么是强化学习2023-10-30 4515
-
如何使用 PyTorch 进行强化学习2024-11-05 661
全部0条评论

快来发表一下你的评论吧 !
