

一种相对直接使用的distillation的变体方法
电子说
描述
在提出备受瞩目的“胶囊网络”(Capsule networks)之后,深度学习领域的大牛、多伦多大学计算机科学教授Geoffrey Hinton近年在distillation这一想法做了一些前沿工作,包括Distill the Knowledge in a Neural Network等。今天我们介绍的是Hinton作为作者之一,谷歌大脑、DeepMind等的研究人员提交的distillation的更进一步工作:通过online distillation进行大规模分布式神经网络训练。该工作提出了Codistillation的概念,通过大规模实验,发现codistillation方法提高了准确性并加快了训练速度,并且易于在实践中使用。
与几乎任何基本模型配合时,诸如集成(ensembling)和蒸馏(distillation)等技术都可以提升模型的质量。但是,由于增加了测试时间成本(对于ensembling)和训练pipeline的复杂性(对于distillation),这些技术在工业环境中使用具有挑战性。
来自谷歌、谷歌大脑、DeepMind的研究人员,包括Geoffrey Hinton等人,在他们提交给ICLR 2018的论文“Large scale distributed neural network training through online distillation”中,探讨了一种相对直接使用的distillation的变体方法,该方法不需要复杂的多级设置或非常多的新超参数。

研究者提出的第一个主张是:在线蒸馏(online distillation)使我们能够使用额外的并行性来适应非常大的数据集,并且速度提高一倍。更重要的是,即使我们已经达到额外的并行性对同步或异步随机梯度下降没有好处的程度,我们仍然可以加快训练速度。在不相交的数据子集上训练的两个神经网络可以通过鼓励每个模型同意另一个模型的预测来共享知识。这些预测可能来自另一个模型的旧版本,因此可以使用很少被传输的权重来安全地计算它们。
论文提出的第二个主张是:online distillation是一种成本效益高的方法,可以使模型的精确预测更具可重复性。研究者通过在Criteo Display Ad Challenge数据集,ImageNet和用于神经语言建模的最大数据集(包含6×1011个tokens)上进行实验,支持了提出的这些主张。
Codistillation:优于分布式SGD
对于大规模的、具有商业价值的神经网络训练问题,如果训练时间能够大幅加快,或最终模型的质量能够大幅提高,从业者会愿意投入更多的机器用于训练。目前,分布式随机梯度下降(SGD),包括其同步和异步形式(Chen et al.,2016)是在多个互联机器上进行大规模神经网络训练的主要算法。但是,随着机器数量的增加,训练一个高质量模型所需时间的改善程度会降低,直到继续增加机器却无法进一步缩短训练时间。基础架构的限制,以及优化上的障碍,一起限制了分布式 minibatch SGD的可扩展性。
分布式SGD的精确可扩展性限制将取决于算法的实现细节,基础架构的具体情况以及硬件的能力,但根据我们的经验,在实际设置中,在超过100台GPU workers上进行有效扩展可能非常困难。没有任何训练神经网络的算法可以无限扩展,但即使扩展得比分布式SGD的限制多一点,也是非常有价值的。
一旦我们达到了向分布式SGD添加worker的限制,我们就可以使用额外的机器来训练模型的另一个副本,并创建一个集成(ensemble)以提高准确性(或通过以更少的step训练ensemble中的成员来提高训练时的精度)。ensemble能够做出更稳定和可重复的预测,这在实际应用中很有用。但是,ensemble增加了测试时的成本,可能会影响延迟或其他成本限制。
为了在不增加测试时间成本的情况下获得几乎与ensemble相同的好处,我们可以对一个n-way模型的ensemble进行蒸馏(distill),得到一个单一模型,这包括两个阶段:首先我们使用nM机器来训练分布式SGD的n-way ensemble,然后使用M机器来训练student网络,以模拟n-way ensemble。通过在训练过程中增加另一个阶段并使用更多机器,distill一般会增加训练时间和复杂性,以换取接近更大的 teacher ensemble 模型的质量改进。
我们认为,从时间和pipeline复杂性两方面来看,额外的训练成本阻碍了从业者使用ensemble distillation,尽管这种方法基本上总是能够改善结果。在这项新的工作中,我们描述了一个简单的distillation的在线变体,我们称之为codistillation。Codistillation通过向第i个模型的损失函数添加一个项来匹配其他模型的平均预测值,可以并行训练n个模型的副本。
通过大规模实验,我们发现,与分布式SGD相比,通过允许有效利用更多计算资源,codistillation提高了准确性并加快了训练速度,甚至加速效果超过了给SGD方法添加更多worker。具体来说,codistillation提供了在不增加训练时间的情况下distill一个模型ensemble的好处。与Multi-phase的distillation训练过程相比,Codistillation在实践中使用也相当简单。
这项工作的主要贡献是codistillation的大规模实验验证。另一个贡献是,我们探索了不同的设计选择和codistillation的实现考虑因素,提出了实用的建议。
总的来说,我们认为在实践中,codistillation比精心调参的offline distillation得到的质量提升是次要的,更有趣的研究方向是将codistillation作为一种分布式训练算法来研究。
在这篇论文中,我们使用codistillation来指代执行的distillation:
所有模型使用相同的架构;
使用相同的数据集来训练所有模型;
在任何模型完全收敛之前使用训练期间的distillation loss。

codistillation算法
实验与结果
为了研究分布式训练的可扩展性,我们需要一个代表重要的大规模神经网络训练问题的任务。神经语言建模是一个理想的测试平台,因为网络上有大量的文本,并且也因为神经语言模型的训练成本可能非常高。神经语言模型是实现分布式SGD(如机器翻译和语音识别)常用重要问题的代表,但是语言建模更容易评估和使用更简单的管线。为了尽可能清晰地提高潜在的可扩展性,我们选择了一个足够大的数据集,它完全不可能通过现有的SGD并行化策略来训练一个表达模型。为了证实我们的结果并不是特定于语言建模的某些特性,我们也验证了我们在ImageNet (Russakovsky et al., 2015)上的一些大规模的codistillation结果。为了证明在减少预测过程中进行编码的好处,并研究算法的其他特性,我们可以使用更小的更便宜的实验,但在研究可扩展性时,真正达到分布式SGD的极限是很重要的。
1. 达到分布式SGD的极限,用于在Common Crawl上训练RNN
在我们的第一组实验中,我们的目标是大致确定在我们的Common Crawl神经语言模型设置中可以有效使用SGD的GPU的最大数量。由于我们的数据集比英文维基百科数据量大两个数量级,因此不用担心重新访问数据,即使在相对较大规模的实验中,这也会使独立副本更加相似。我们尝试使用32和128个workers的异步SGD,在必要的情况下,通过增加参数服务器的数量来分配权重,以确保训练速度被GPU计算时间瓶颈。我们发现很难保持训练的稳定性,并防止RNNs与大量GPU的异步SGD出现差异。我们尝试了一些workers提升计划和不同的学习速率,但最终决定将重点放在同步算法上,使我们的结果更少地依赖于我们的基础结构和实现的特定特性。梯度的稳定性很难独立于特定的条件下进行分析,而实现和基础结构的差异更容易抽象为同步SGD。虽然可能需要更多的努力使异步工作良好,但陈旧的渐变对学习进度的削弱作用是一个众所周知的问题,Mitliagkas等人(2016)认为,异步可以有效地增加动量,这也是为什么它容易分化的原因。在初步实验中,从codistillation中获得的收益似乎与选择异步或同步SGD作为基本算法无关。
可同时用于同步SGD的最大GPU的数量取决于基础架构限制、尾延迟和批处理大小的影响。完全同步的SGD相当于批量大得多的单机算法。增加有效的批量大小可减少梯度估计中的噪声,从而允许更大的步长,并有望实现更高质量的更新,从而实现更快的收敛速度。鉴于有效的无限训练数据(即使使用256个GPU,我们也不访问所有常见爬网训练数据),我们直观地预计会增加有效批量,最终增加步骤时间。我们采用完全同步的SGD在Common Crawl上训练了语言模型,并使用128和32,64,128和256GPU的批处理大小。因此,有效的批量大小范围为4096至32768.一般来说,我们应该期望需要增加学习率,因为我们增加了有效的批量大小,所以对于每个GPU我们尝试的学习率为0.1,0.2和0.4。对于32和64GPU,0.1表现最好,因为原先的三种学习率都没有对256GPU表现良好,我们还尝试了0.3的额外中级学习率,这是256的最佳表现学习率。
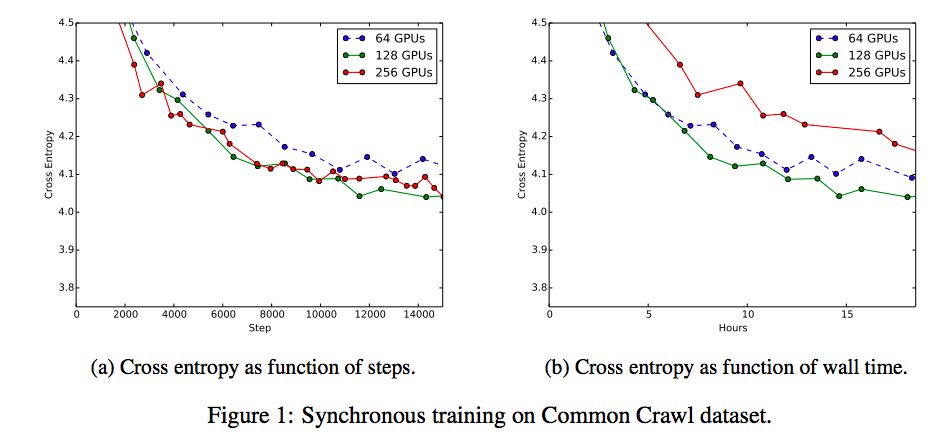
图1a将验证误差作为我们尝试过的不同数量的GPU的全局步骤的函数,使用了每个GPU数量的最佳学习速率。增加数量(因此有效的批处理大小)减少了达到最佳验证错误所需的步骤数,直到128GPU,在这一点上没有额外的改进。图1b对相同数量的同步GPU的验证误差与Wall time进行对比。在这些特殊的实验中,与128个GPU同步的SGD是训练时间和最终准确度方面最强的基线。因此,我们将其余实验集中在与128位同步SGD进行比较,并研究使用同步SGD作为子程序的codistillation,但它也适用于异步算法。
2. 带同步SGD的CODISTILLATION
对于Common Crawl上的语言建模,具有128GPU的同步SGD实现了标准分布式训练的最佳结果,至少是我们尝试过的配置,并且我们无法使用256个GPU来提高训练时间。虽然额外的GPU似乎不能帮助基本的同步SGD,但我们的假设是,如果我们使用两组128GPU(使用同步SGD定期交换检查点)双向codistillation,那么额外的128GPU将提高训练时间。
一个问题是,codistillation仅仅是一种惩罚确信输出分布(penalizing confident output distributions)或平滑标签的方法,所以我们也将其与两个标签平滑基线进行比较。第一个基线用符合统一分配的术语代替codistillation损失术语,第二个基线使用与使用一个与unigram分布相匹配的术语。在初步实验中手动调整权衡超参数。另一个重要的比较是两个神经网络的集成,每个神经网络都有128GPU和同步SGD。
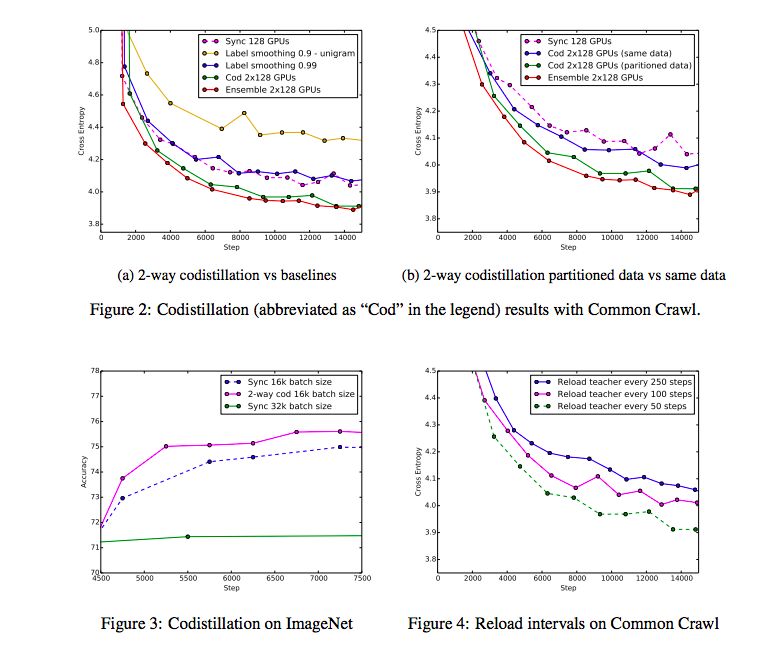
图2a利用128个GPU的两个组,以及同步SGD的训练曲线和标签平滑基线(每个使用128个GPU)和一个包含128个GPU基线的两个实例的训练曲线,绘制了验证交叉信息和同步训练的步骤。
讨论和未来的工作
Distillation是一种非常灵活的工具,尤其是在模型训练过程期间而不是之后进行。它可用于加速培训、提高质量,以新的、更有效的沟通方式下进行训练,并减少预测的流失。然而,我们仍有许多问题需要探讨。例如,我们主要关注对彼此进行codistilling的模型对上。如果成对是有用的,那么其他拓扑也是有用的。完全连接的图形可能使模型过于相似,太快以至于环形结构也可能变得有趣。我们也没有探究teacher models预测的准确性的局限性。也许可以对teacher models进行积极的量化,使其在很大程度上与普通训练一样廉价,即使是非常大的模型。
有些矛盾的是,坏模型之间codistilling可以比独立的模型训练更快地学习。从某种程度上讲,teacher models所犯的错误可以帮助student model做得更好,而且比仅仅看到数据中的实际标签要好。描述teacher models的理想特性是未来工作的一个令人兴奋的途径。在这项工作中,我们只从检查点提取预测,因为预测是可识别的,而且不像网络的内部结构,没有虚假的对称。也就是说,从一个检查点提取更多信息可能比仅仅预测没有触及到工作人员交流梯度的相同问题,允许使用teacher models作为更强的调节者。也许可以用基于codistillation的方法来增强McMahan等人(2017)提出的在带宽受限的设置环境下的联合学习。
-
一种中频直接采样方案2012-11-25 0
-
有没有一种方法直接从芯片上读取27443的程序?2019-09-17 0
-
荣小菜补钙记第19期:数据操作之变体数据提取2021-03-11 0
-
分享一种新的失效保护方法2021-05-14 0
-
一种伺服电机的控制方法2021-09-03 0
-
YOLOv6中的用Channel-wise Distillation进行的量化感知训练2022-10-09 0
-
一种实用的电炉控温方法2009-01-12 1349
-
一种改进直接转矩控制性能的方法2009-04-03 840
-
Yahalom协议及其变体的时序缺陷分析与改进2009-04-17 656
-
启辉器熔焊的一种预防方法2010-03-29 1034
-
一种直接强度解调应用分析2011-09-13 540
-
一种新型的电刷调整方法2017-01-02 689
-
一种简化的永磁无刷直流电机直接转矩控制方法2017-01-21 810
-
一种自动生成反向传播方程的方法2018-08-14 3813
-
一种结合相对信息熵的改进LEACH协议2021-04-02 642
全部0条评论

快来发表一下你的评论吧 !
