

基于FPGA为实现平台的低功耗高速解码器系统
电子说
描述
针对传统编解码算法复杂度高、不易扩展等问题,对自编码神经网络前向传播算法和结构进行了研究,提出了一种以自编码神经网络为编解码算法,以FPGA为实现平台的低功耗高速解码器系统。该系统实现了字符的编解码,同时可被应用于各种多媒体信息的编解码。通过ModelSim仿真,Xilinx ISE实现后进行硬件实测,对计算精度、资源消耗、计算速度和功耗等进行分析。实验测试结果表明,所设计的解码器能够正确完成数据解码功能,算法简洁高效,扩展能力强,系统具有低功耗、速度快等特点,可广泛应用于各种低功耗、便携式产品。
0引言
计算机处理多媒体或文字信息的基础是对相关信息进行编码和解码,以利于信息的传输、显示和保护[1]。面对巨大信息量的处理需求,快速高效的编解码系统能够有效提高信息处理能力。近年来,随着神经网络的发展和应用,利用神经网络进行数学函数回归的方案,为信息的编解码提供了简单有效的途径[2]。自编码神经网络是一种无监督的人工神经网络,其利用反向传播算法训练使得网络的输出值等于输入值,从而为输入数据学习到一种特征表示,广泛应用于图像压缩和数据降维等领域[3-4]。自编码神经网络输出等于输入的特点适合用于数据编码和解码,相比于传统的编解码方法,如熵编码[5],该算法更简洁高效,结构可扩展,实用性更强[3]。
而随着编解码器在一些低功耗、便携式产品中的应用,高速、高精度和低功耗已经成为编解码器的一种发展趋势。现场可编程门阵列(Field Programmable Gate Array,FPGA)是一种可编程逻辑器件,用户可通过硬件描述语言完成硬件电路设计。FPGA内部集成了具有高性能的数字信号处理器和大量存储资源,可以高效低成本地实现定点运算和数据存储,因此目前FPGA是一种理想的编解码器实现平台[5-6]。FPGA中各个硬件模块并行执行,可将计算量大的算法映射到FPGA中实现硬件加速。有学者尝试采用FPGA作为神经网络的实现平台,并取得了优异的性能,尤以速度和功耗突出[7-8]。综上所述,基于自编码神经网络,以FPGA为实现平台的编解码系统,具有灵活性高、高速、低功耗等特点,可广泛应用于各种低功耗、便携式应用中。
本文通过分析自编码神经网络的结构和特点,提出了一种用于数据解码的硬件实现架构。根据网络计算过程中包含的运算和神经元间的并行性特点,结合FPGA高并行、低功耗和高速数据处理的优势,将自编码神经网络的解码部分映射到FPGA中。该架构具有速度快、功耗低等特点,除文中论述的文字信息解码外,该架构具备扩展到图像编解码的可能性。
1自编码神经网络
人工神经网络是基于生物神经网络的基本原理,通过模拟人脑神经系统的结构和功能而建立的一个数学模型,该模型拥有以任意精度逼近一个离散值、实数值或者目标函数的功能[9-10]。自编码神经网络是一种无监督的人工神经网络,其采用反向传播算法,通过学习试图使得网络的输出值等于输入值,从而为输入数据学习到一种特征表示[3-4]。
自编码神经网络模型是一种对称结构,中间为隐含层,输入输出层神经元节点数相等且通过训练使得网络输出值和输入值相等。如图1所示为自编码神经网络的结构图,输入层和输出层含有m个神经元,隐含层含有n个神经元,输入层和隐含层下方的“+1”是偏置节点。自编码神经网络的输入层到隐含层构成编码器,隐含层到输出层构成解码器,对自编码神经网络的训练过程就是通过调整编码器和解码器中的权值和偏置,使其逼近一个恒等函数,从而使得网络输出值等于输入值,这样网络隐含层的输出数据为原始输入数据的另一种特征表示,即该数据经过自编码神经网络的解码器可以恢复原始的输入数据[11]。
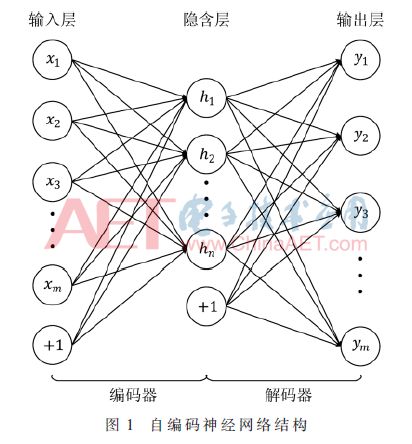
在本文中,利用自编码神经网络的编码器对输入数据进行编码,所得到隐含层的输出数据称为原始数据的编码;该编码数据经过自编码神经网络的解码器实现数据解码,从而恢复原始输入数据。下面参照图1所示的自编码神经网络结构,介绍自编码神经网络的前向计算过程,首先计算隐含层n个神经元的输出如式(1):
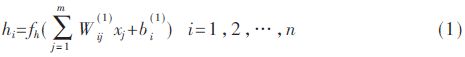
输出层m个神经元的输出如式(2):

通过对网络前向计算过程式(1)和式(2)的分析可以看出:自编码神经网络对信息的处理为从输入层开始,经过隐含层直到输出层输出为止,每一层各个神经元之间的计算具有独立性和并行性;式(1)和式(2)的计算包括乘加运算和激励函数运算,且两者按照顺序依次进行。
2FPGA设计方案
本章对基于FPGA的硬件解码系统的设计需求进行分析,介绍整个系统的硬件架构设计、系统工作原理,最后对设计中的网络计算模块进行详细介绍。
2.1系统分析
本文在FPGA中设计实现图1所示自编码神经网络的解码器部分,从而实现数据解码功能。在软件端对自编码神经网络进行训练,得到网络模型后将对现今最通用的单字节编码ASCII码归一化后的数据输入至自编码神经网络的编码器以获得编码数据,最后将编码数据送至FPGA端实现数据解码以恢复原始输入的ASCII码。
通过对自编码神经网络前向计算的分析,其计算过程中包括乘加运算和激励函数运算,网络每层中各个神经元之间的计算具有独立性和并行性。而对编码数据进行解码操作的过程中,要求所设计的硬件系统具有实时性特点。FPGA作为一个分布式并行处理系统,其内部包含大量逻辑单元和计算单元,且具有可编程、速度快、灵活性高、易配置、设计周期短等特点,因此本文选用FPGA作为所设计数据解码器的硬件实现平台。
所设计的解码器为图1所示自编码神经网络的隐含层到输出层部分,其所包含的权值参数有n×m个,偏置参数有m个,n和m分别表示网络隐含层和输出层神经元的个数。由于实现解码功能仅需要网络的前向计算,因此网络的权值和偏置为固定值,所以在设计中可利用FPGA内部资源对网络权值和偏置进行存储并以固定值的形式参与网络运算。
解码器一次完整的解码过程可简述为:输入数据→解码计算→输出结果。在实际应用中往往包含有多组编码数据,因此设计中将编码数据存储在外部存储器中以供FPGA读取。SD存储卡是一种基于半导体快闪记忆器的新一代记忆设备,由于它具有体积小、数据传输快、可热插拔等优良特性,被广泛应用于便携式设备中[13]。因此本设计选择使用SD卡来存储编码数据。SD卡读操作为每次读取一个扇区的数据,而网络计算模块的输入数据的个数与图1所示隐含层神经元个数相同,两个数据量并不匹配。另外,SD卡读数据操作和网络计算为异步关系,因此本设计中加入FIFO模块,作为SD卡读数据模块和网络计算模块两个异步模块之间的数据缓存器,这样的设计也易于扩展到其他不同神经元数量的网络结构。
另外,为了便于人为控制对多组编码数据进行解码,系统设计中利用按键来产生一次解码操作的起始信号。本设计是以ASCII码的编码和解码对系统进行测试,因此设计中采用专门显示字母、数字和符号等的工业字符型液晶LCD1602显示解码结果。最后为了增加FPGA硬件系统稳定性,减少系统时钟的抖动和倾斜,设计中增加混合模式时钟管理器(MMCM),用于在与输入时钟信号有设定的相位和频率关系的情况下,生成不同的时钟信号,该信号用于各个模块工作。
2.2硬件系统架构
基于上述分析,所设计FPGA硬件系统结构如图2所示。系统外围模块包括存储编码数据的SD卡,产生差分时钟信号的晶振,产生复位信号和控制系统工作的按键,和显示网络计算结果的LCD1602显示器。FPGA内部包含三大模块,分别是:数据加载模块、数据处理模块和混合模式时钟管理器。
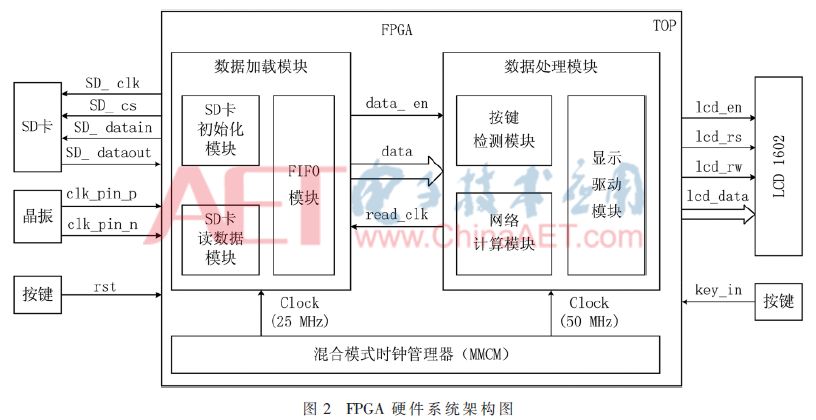
设计中利用SD卡来存储编码数据,对SD卡的操作采用简单的命令/响应协议[13],全部命令由FPGA发起,SD卡接收到命令后返回响应数据。要读取SD卡中的数据,需要首先完成SD卡的初始化,该系统按照功能分别设计SD卡初始化模块和SD卡读数据模块,其符合FPGA模块化的设计原则。FIFO模块作为SD卡和网络计算模块之间的数据缓存器,同时又用于异步数据传输,因此在设计中采用独立的读时钟和写时钟,以用于异步操作。
按键检测模块不断读取外部按键输出信号key_in的值,当检测到按键按下时该模块产生一个高脉冲信号,该信号将作为一次解码操作的起始信号。网络计算模块按照神经网络的计算方法对读入的数据进行计算。显示驱动模块设计中采用有限状态机的方式控制LCD1602的初始化和数据显示操作,该模块与网络计算模块之间有信号线连接,以实现将计算结果送至显示驱动模块,显示驱动模块控制LCD1602对计算结果进行显示。
在图2所示的硬件架构图中,混合模式时钟管理器将外部时钟分频产生各个模块工作所需要的时钟信号,其通过两个时钟线分别与数据加载模块和数据处理模块连接,而数据加载模块和数据处理模块之间通过data_en、data和read_clk 3个信号连接。
2.3系统工作原理
FPGA的特点是可以实现并行操作,在图2所示的系统架构图中,数据加载模块和数据处理模块以并行异步的方式工作,下面对其工作原理分别介绍。
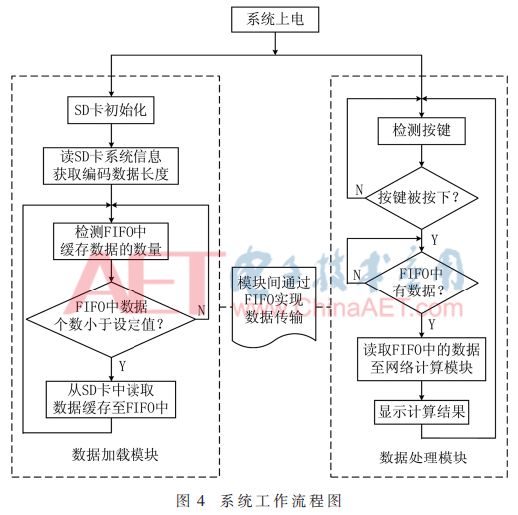
数据加载模块:系统上电后,数据加载模块首先控制SD卡初始化模块对SD卡进行初始化,其初始化操作包含有一系列的命令,在初始化完成后SD卡初始化模块输出初始化完成信号。由于SD卡中的编码数据是在PC端以FAT32文件系统的形式写入的,因此在对SD卡初始化完成后,数据加载模块控制SD卡读数据模块读取SD卡中的FAT32文件系统信息,获取编码数据的长度,即文件所包含的字节数,该数据将用于控制对编码数据的读取。最后,数据加载模块不断检测FIFO中缓存数据的数量,当数据的数量不足设定值时便控制SD卡读数据模块将SD卡中的编码数据读入FIFO中进行缓存。
数据处理模块:当按键检测模块检测到外部按键被按下时会产生一个高脉冲信号,然后数据处理模块会通过data_en、data和read_clk 3个信号从FIFO中读取数据到网络计算模块进行计算,然后通过显示驱动模块控制将计算结果显示在外部的LCD1602上。数据加载模块和数据处理模块之间data_en、data和read_clk 3个信号的时序关系如图3所示,当data_en为高电平时,代表FIFO中存在有效的数据可以读取,此时每当read_clk信号的上升沿到达时,从data端口可以读取一个数据。

如图4所示为FPGA硬件系统工作流程图,其中SD卡读操作和网络计算之间为异步关系,系统中所加入的FIFO模块作为SD卡读数据模块和网络计算模块两个异步模块之间的数据缓存器。
2.4网络计算模块设计
网络计算模块是本设计中的核心模块,用于实现图1中的解码器,将编码数据和解码器部分的权值与偏置按式(2)进行乘加运算,并经过激励函数得到输出值。
通过对网络前向计算分析可知其包括乘加运算和激励函数运算。由于本设计中自编码神经网络的输入是对ASCII码归一化后的数据,即原ASCII码值除以128后的值,因此在FPGA模块中激励函数的输出值需要扩大128倍才是真正的ASCII码值。由于128=27,在FPGA中乘操作可通过移位实现,因此对计算结果扩大128倍相当于将二进制格式的小数点右移7位。更进一步,直接截取小数点后7位即为计算结果扩大128倍后的ASCII码值。因此在网络计算模块将计算分为3部分:乘加运算、激励函数运算和截位运算,如图5所示为一个输出层神经元的计算结构示意图,输出层各个神经元按照图5所示的计算结构以并行、独立的方式进行计算。
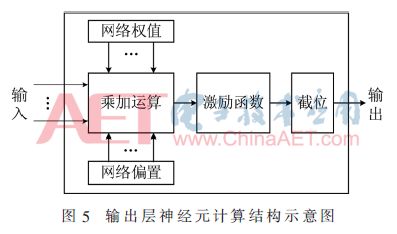
模块中的乘加运算是将编码数据、解码器部分权值和偏置按照式(2)中激励函数内部的乘加运算规则进行计算。本设计输出层神经元的激励函数为hard_sigmoid函数[12],表达式为式(3):
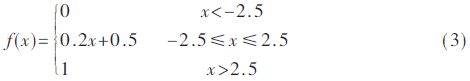
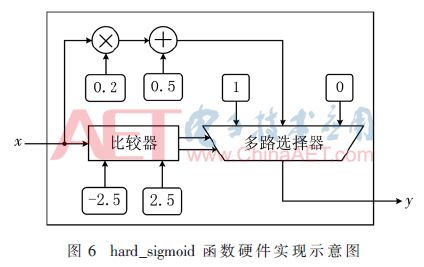
根据定义,hard_sigmoid函数为分段函数,且各段均为线性关系,其非常便于在FPGA系统中实现,即利用条件判断语句对输入进行判断并输出不同的值,如图6所示为hard_sigmoid函数硬件实现示意图。
3系统测试分析
为了测试所设计自编码神经网络在FPGA平台上的实现,本文选择的网络结构为输入层、输出层含有4个神经元节点,隐含层含有8个神经元节点。所选择的应用背景为对ASCII码的编码和解码,其中软件端完成对ASCII码的编码,所得到的编码数据在FPGA端实现解码。
本实验测试集由软件生成,软件环境下对ASCII码中非控制字符(码值为32~127,共96个)做归一化处理,然后按照随机组合的方式4个一组输入至所设计的自编码神经网络并获得隐含层的输出,将该输出作为FPGA的测试输入数据保存在SD卡中。所选择的FPGA硬件平台是Xilinx VC707 FPGA开发板,系统开发环境为Xilinx ISE 14.7,仿真环境为ModelSim SE 10.1c,如图7所示为硬件系统测试图。

在图7所示的硬件系统测试图中,①为SD卡,②为LCD1602显示屏,③为控制按键。系统上电后,通过控制按键的按下操作不断从SD卡中读取数据,经过网络计算模块计算后将结果显示在LCD1602显示屏上,每次显示4个字符,如图7中LCD1602显示屏的第二行即为解码后的4个数据,对应于图1所示神经网络的4个输出。
3.1网络计算结果分析
神经网络经过训练得到一组最优参数,包括网络权值和偏置。为了在FPGA中实现所设计自编码神经网络的解码器部分,需要获取对ASCII码编码后的数据(神经网络隐含层的输出数据)和解码器部分的网络权值与偏置。另外由于FPGA仅能对二进制数据识别和计算,因此需要将上述数据转换为二进制数据。
在FPGA设计中,数据的表示方式与FPGA逻辑资源消耗直接相关的。数据表示位数越多,数据精度越高,逻辑资源的消耗也就越多,因此在FPGA设计中需要权衡FPGA资源消耗和数据精度之间的关系。结合本文的实际应用,同时为了更好地权衡FPGA设计中的精度、资源占用和功耗,本设计采用定点数表示上述数据。
由于在FPGA设计中采用有限位定点数来表示数据时,对原数据进行定点量化的过程中会因为数据的截断而产生误差。根据网络计算模块的设计,其输出为计算结果二进制小数点后7位,因此在设计中需要保证这7位数据正确,即与原始输入数据相比,经过解码后输出结果的误差需要小于2-7,即应小于7.812 5×10-3。本文利用MATLAB下的Fixed Point Toolbox对数据进行量化,然后分析本设计中数据不同的量化位数对计算结果误差的影响,如图8所示为定点数表示中小数点的位数和最大误差之间的关系。
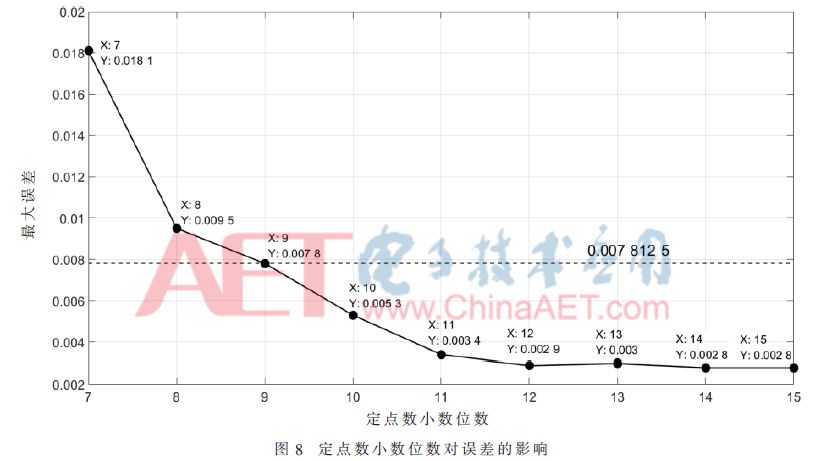
从图8可以看出:
(1)随着定点数小数位数的增加,最大误差值不断降低,即数据精度越来越高;
(2)定点数小数位变为12位之后,其最大误差基本保持不变;
(3)定点数小数位为9位时,其最大误差与7.812 5×10-3基本一致;定点数小数位为10位时,其最大误差已符合小于7.812 5×10-3的要求。
基于图8所示的分析结果,本文在对设计中的网络权值、偏置和编码数据进行定点数量化时,小数位均设计为10位。进一步通过对网络的权值、偏置和编码数据的大小范围进行分析可以确定其整数位的位数,3种数据的二进制定点数格式如表1所示。
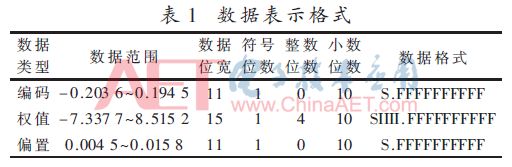
本设计在ModelSim环境下对网络计算模块进行仿真,并对模块输出的计算结果与软件中的原始输入数据进行分析比对,所测试数据中的绝对误差最大值小于7.812 5×10-3,符合设计中的误差要求。另外通过硬件实测,所有被编码后的数据经过FPGA计算后均被正确解码,并将结果显示在LCD1602上,即所设计的FPGA硬件系统正确地完成了解码功能,从而验证了对所设计网络计算模块的误差分析。
3.2系统性能分析
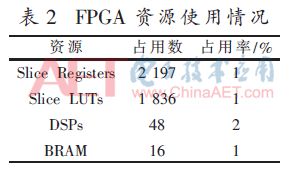
如表2所示为Xilinx ISE对系统工程综合实现后列出的主要资源占用情况。可以看出,DSP资源占用较大,主要原因是网络计算模块中的乘加计算和激励函数运算均含有定点数乘法和加法操作,因此会占用较多的DSP资源。另外,BRAM资源的占用主要来自于FIFO模块的实现和网络计算模块中网络权值与偏置的存储。
如表3所示为FPGA硬件实现数据解码的速度和软件解码速度的比较,软件解码是在MATLAB软件中测试所得,CPU为Intel Core i7,主频为2.5 GHz。FPGA硬件解码速度是通过在FPGA中设置计数器,对从读取解码器输入数据到最后输出结果的时钟进行计数,然后利用ChipScope工具查看计数值来计算工作时间。表3中的结果显示,相比于CPU软件解码,本文所设计的FPGA硬件解码器加速了7倍以上。

通过Xilinx ISE自带的XPower工具可以得到FPGA的运行功耗大致为0.389 W,所设计系统的外围设备中LCD1602功耗大致为0.693 W,其余外设的功耗可忽略不计,因此整个系统总功耗为1 W左右。而相比之下,Intel Core i7-6500U主频为2.5 GHz的CPU的功耗可高达65 W,可见本系统功耗仅为通用CPU的1.5%,因此特别适合将本文所设计的基于FPGA的解码器应用于低功耗便携式设备中。
4结论
利用神经网络所具有的输入输出之间的映射关系,可以简单高效地实现数据编码和解码。本文根据自编码神经网络的结构和特点,将其用于编码和解码,并在FPGA中实现自编码神经网络的解码器部分。通过对软件算法的设计和网络计算过程的分析,按照功能和需求对FPGA模块进行设计。利用ModelSim软件对所设计的各个FPGA模块进行仿真验证,利用Xilinx ISE对整个工程进行设计、综合和实现,并将编程文件下载至Xilinx VC707 FPGA开发板中进行验证,同时对FPGA系统的资源占用、计算速度和功耗进行评估。通过测试,对于在软件中经过编码的数据,在FPGA系统中可以正确解码。同时相比于通用CPU,该系统计算过程加速了7倍以上,而运行功耗仅为CPU的1.5%,因此具有速度快、功耗低的特点,特别适合将其应用于实时性、低功耗便携式设备中。
-
TVP5151超低功耗NTSC/PAL/SECAM视频解码器数据表2024-07-03 463
-
ES8336低功耗音频编解码器规格书2023-06-13 1357
-
低功耗 1-of-2解码器/解复用器-74AUP1G192023-02-14 401
-
AD74111:低成本、低功耗单声道音频编解码器数据表2021-05-24 922
-
SSM2604:低功耗音频编解码器数据表2021-04-20 821
-
SSM2602: 低功耗音频编解码器2021-03-21 845
-
SSM2603:低功耗音频编解码器 数据手册2021-03-19 1485
-
一种基于低成本FPGA的高速8B_10B编解码器设计_陈章进2017-03-19 834
-
一种高速卷积编解码器的FPGA实现2017-02-07 922
-
数字语音解码器的低功耗设计方案2012-08-20 2906
-
【FPGA设计实例】基于FPGA的正交解码器建立2012-03-15 11295
-
MAX9526低功耗视频解码器2011-03-08 2013
-
欧胜超低功耗编码解码器WM8904带有W类耳机和线路驱动器2010-01-15 2976
-
欧胜推出超低功耗音频编码解码器2010-01-13 1110
全部0条评论

快来发表一下你的评论吧 !
