

适用于无人驾驶的分布式仿真平台
电子说
描述
上周来自百度Apollo的资深架构师——毛继明,为我们带来《适用于无人驾驶的分布式仿真平台》的社群分享,错过社群直播的开发者可以通过此篇内容了解干货!

本次分享主要为以下五个方面的内容:
一、仿真产品的业务价值
二、如何达到真实性
三、如何完成更全面异常检测
四、智能辅助驾驶和全自动无人驾驶的区别
五、全面的无人车能力判定
{ 一 }
仿真产品的业务价值
仿真器,顾名思义,就是用软件模拟真实。但在 Apollo 中,对仿真平台的定位是不仅仅是真实,而是要能够进一步:能够发现无人车算法中的问题。因为在整个算法迭代闭环中,光有拟真是不够的,还需要能够发掘问题,发现了问题后才能去 fix 问题,也就是回到了开发过程。
如此这样,从开发到仿真再回到开发,仿真平台同我们的开发过程串联成一个闭环。只有闭环的东西才能构成持续迭代和持续优化状态。所以仿真平台在整个无人车算法迭代中的地位非常重要。
如上所述,仿真平台的功能。
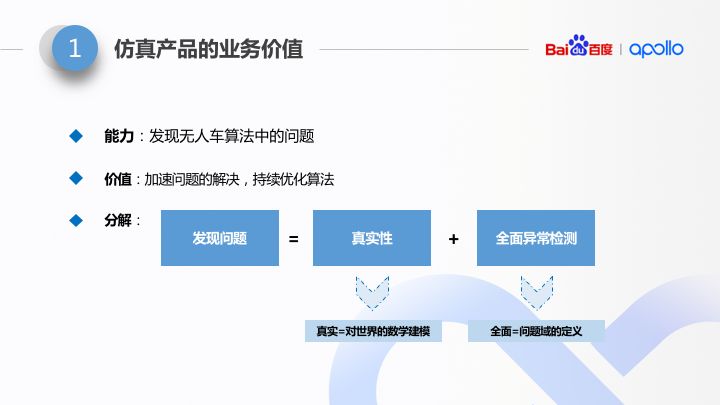
发现问题,进行功能拆解的话,可以拆成有因果关系的两部分:
先要能够真实,接下来要能够进行全面的异常检测。真实性,就是说要能够对世界进行数学建模;全面的异常检测,其中最难的是“全面”二字,这要看我们对“全面的异常”的定义。
{ 二 }
真实→客观世界的数学建模
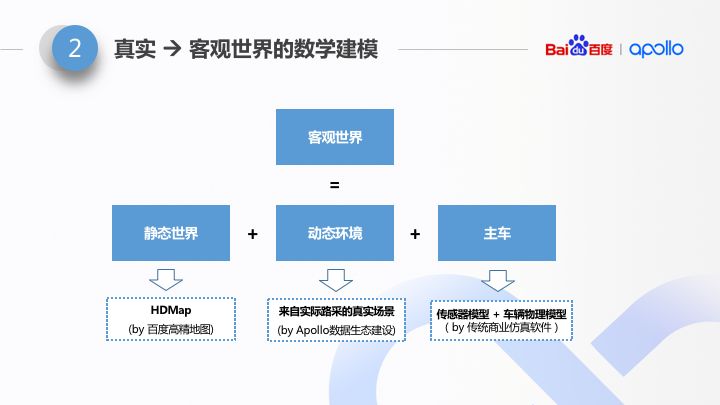
客观世界的真实性表达依赖于三部分:静态环境的真实性、动态环境的真实性、车辆行为(也就是主车)真实性。
准确来说,对于静态环境的真实建模本身并不难,比如游戏画面中,我们能经常看到“照片画质”的渲染,看着都很真。最难的是“成本”两个字,这个成本指的是:单位公里上全部环境建模的时间成本。无人车的场景重建跟游戏中不一样。游戏中是艺术家造出的场景,它不考虑真实。而真实仿真器中的场景是要跟真实世界做 diff 的,需要做到毫厘不差。
1静态环境的真实性
静态环境是相对于动态障碍物而言的,比如道路(包括各种地面元素)、栅栏、红绿灯、路旁的路灯和绿植两侧的高楼。对于自动驾驶来说,它们属于背景元素。当然大家能够理解这跟行人、车辆等动态障碍物的不同。
大家都有过这样的经验,我们自己得到一个结果,这很简单,但若要让自己得到一个跟别人一模一样的结果,这个成本就大太多了。百度内部有成熟的百度高精地图制作流水线,在厘米级精度的世界刻画能力的基础上,成本做到非常低。
那么大家会问,讲了这么多地图生成的事,这跟仿真有什么关系?其实,Apollo 仿真器的静态世界的表达,正是直接使用了 Apollo 高精地图数据。所以它是真实的,且是具有足够低成本的。
2标题内容
然后是动态环境,也就是各种障碍物的行为真实性了。动态障碍物引入了人的因素,相对静态场景重建更难,因为人的行为“难以捉摸”。对于 Apollo 而言,最快和直接的做法,不是拟真,而是直接“真”。
用实际路上采集回的海量真实数据,经过 Apollo 感知算法,做动态场景重建。一方面,我们通过 Apollo 数据生态,会得到更多的数据用来补充场景,另一方面我们利用自身持续迭代的感知算法可以更精准的还原世界。从量和质上都得到持续的提升。
3车辆行为的真实性
主要分传感器模拟和车辆动力学模拟。由于传统的商业仿真软件在这两个领域已经进行了数十年的研发,成果已经被各大车厂所认可。Apollo 倡导开放能力、合作共赢,所以这两块功能 Apollo 仿真平台是以直接 involve 商业仿真软件的方式实现这两块 feature。后面在讲开放性的时候会提到。
{ 三 }
全面的异常检测
在满足了真实性后,我们来看看如何完成下一个需求:更全面异常检测。
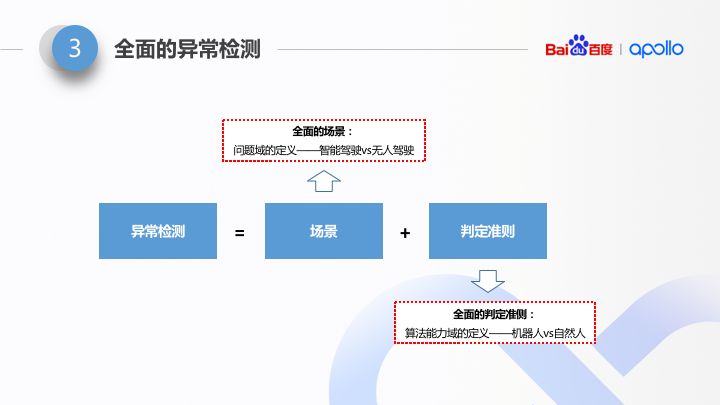
其实大家都知道,尤其是搞 IT 的同学可能会更清楚。所谓异常检测,就是先给一个条件,再给一个预期输出。就是大家写的 UnitTest 的常用版型。方法论上都是一样的。那么对于无人车的异常检测,什么是条件呢?就是车辆运行的场景。什么是预期输出?就是要有一整套判定准则或者说判定算法。
显然,要做到全面的异常检测,这里重点或者说难点,肯定不在后四个字,而在于前面两个字“全面”。场景,要是全面的场景;判定,要是全面的判定。
全面的场景。全面这两个字很虚,而且“100% 全面”在理论上也无法达到。所以,唯一可行的做法是:在受限场景下逼近 100%。这个“受限场景”,换种说法,就是我们无人车算法的问题域定义,也就是说这个算法要解决哪一种受限场景。不同的应用场景,仿真器的设计可能会大有不同。目前以我的理解,能够对仿真器设计产生革命性变化的,只有一种问题域的划分方式,就是智能驾驶 vs 无人驾驶。具体怎么个革命性变化,后面会讲。
全面的判定。这个取决于算法能力域的设计。什么叫算法能力域?就是指算法能达到的上限,也就是说,是 just work,还是 work well。对于判定算法而言,如果仅仅是做“just work”级别的判断其实并不难,难在对“work well”做判断。所以这里,也有一个对仿真器算法产生重大影响的能力域的划分方式,就是: “机器人型驾驶”(just work)的判定,以及“拟人型驾驶”(work well)的判定。
{ 四 }
智能驾驶 vs. 无人驾驶
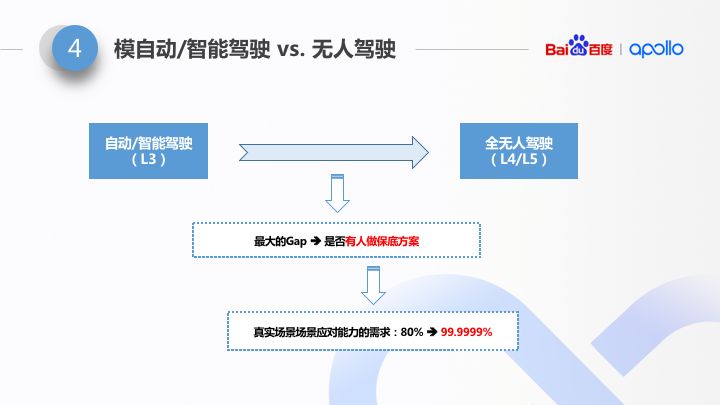
准确来讲,无人驾驶属于智能驾驶的一个分支,这么写可能不太确切。但是,我想强调的是,这其中有一个非常大的差异,无人驾驶和自动驾驶之间的,就是:是否有人。
“是否有人”这个事情,对整个智能驾驶无论是算法、还是硬件设计、还是仿真器的设计,都产生了极大的影响。“没有人来保底”决定了算法需要应对的占比从 80% 到 99.9999%。大家都了解二八法则。从 80% 到 99.9999%,无论是算法、还是硬件、还是仿真,需要解决的问题或者说面临的困难要提高几个数量级。
{ 五 }
复杂城市道路 +99.9999%
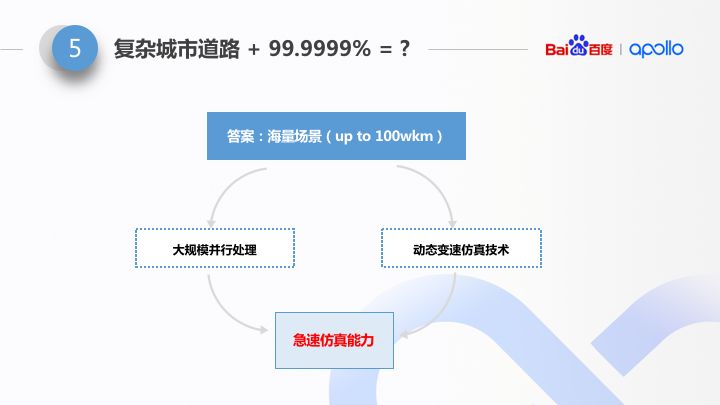
99.9999% 是无人驾驶特有的要求。而 99.9999% 需要的是算法“见多识广”。要解决长尾问题,也就是要应对全自动无人驾驶的 99.9999% 的场景 handle 能力,必须要累计起【海量场景】。
也许大家对海量场景这个事情并没有太多感觉。在实际的生产领域,拥有海量场景其实不是难事,难就难在海量场景的使用效率。前面讲到了,算法需要高速迭代,我们的用户需求是:30 分钟,仿真平台能告诉我们什么。30 分钟,可以算算,平均时速 30km/h,只能跑 15 公里,如果是这种能力的话,其实不用谈海量场景。
所以从百度内部最开始进行无人车项目时,就已着手考虑仿真平台的运行效率。Apollo 仿真平台通过 2 个不同层次的实现方式来进行大幅度优化。从宏观角度出发,通过大规模分布式化来进行;所以Apollo 仿真从最开始,就是以分布式仿真作为方向的。从微观角度出发,通过动态变速仿真来进行。
{ 六 }
大规模分布式的架构设计思考
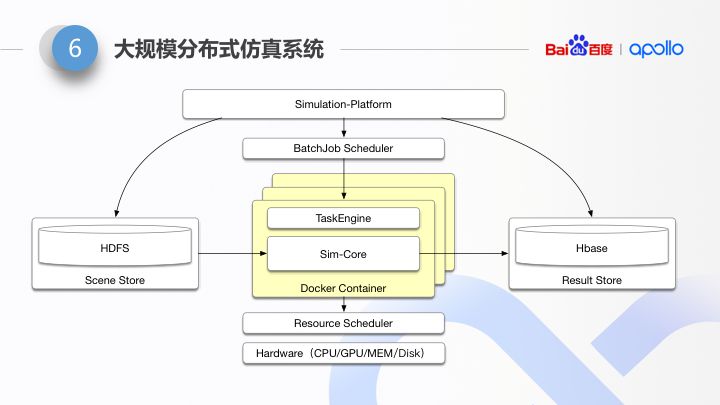
这个是分布式仿真框架的简图。了解分布式计算框架的同学应该比较熟悉。整体上看,分布式仿真架构按层次和功能,可以按照如下几部分进行说明:
由于分布式仿真平台的计算模型很像传统的 MapReduce。所以整个分布式调度 follow 传统的 MR 架构。
下层是 Hardware Resource Scheduler。由于仿真节点的运行会用到 GPU+CPU/only CPU/CPU+FPGA 多种硬件组合,又由于仿真的运行是一种弹性的资源使用。所以我们单独的剥离出来一层 Hardware Resource Scheduler。这层 Scheduler 是支持更换的。比如在百度内部,我们使用了百度内部已有的资源调度器 Matrix,如果是在开源系统里,我们支持使用 K8S,再比如我们跟 Microsoft azure 合作的 Apollo Simulation Global 中,我们使用了 MS 的 cosmos。未来如果做大客户定制化,我们也可以支持大客户内部专门的 Resource Scheduler。
上层是 Batch-job Scheduler。因为分布式仿真运行模式为 Batch-job,所以我们单独剥离了一层 Batch-job Scheduler。它负责 job 的整个生命周期的运行状态的推进,比如各种部署、启动、运行状态检查、重试、优先级、弹性伸缩……等逻辑。这块同样的,我们单独剥离出一层的原因在于,我们解耦了这层标准化的分布式计算模型,也允许根据用户特别的需要进行替换。在内部我们使用了百度的 Normandy 调度框架,在外部我们支持更换成业界主流的 K8S 等。
中间这层是仿真核心。它运行在 Docker Container 中。仿真核心中运行的是客户的算法 + 仿真逻辑:包括场景重建 + 动力学模型 + 精细化度量。由于运行模型复杂,所以我们在 Container 内抽象了上下两层:上层,我们内部叫做 Task Engine,专门负责复杂的仿真执行流程调度。下层是 Sim-Core,用来放置用户的自己的算法。
在外层有两个 Storage Component:Scene Store,Result Store。围绕着计算,统一管理了数据。Simulation-platform 主要提供了提交接口、数据分析、Dashboard 接口,串通起完整的仿真流程,供用户使用。
{ 七 }
动态变速仿真技术
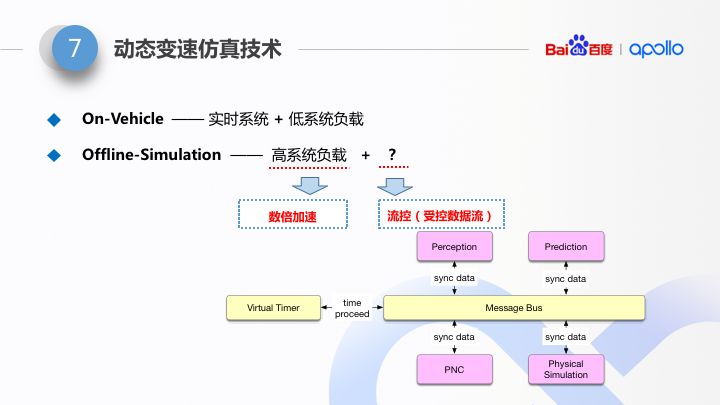
这里做一下对比,真实道路情况下,车载算法是在车载电脑上运行,实时性要求很高,所以往往需要保留较多的系统资源冗余(以应对随时到来的系统处理颠簸的情况),万一出现颠簸状态,实时系统会采用丢帧的方式以保证运行时消息处理的低延迟。
在仿真系统里,这是在离线运行。如果不做任何处理,我们需要用更强力的服务器,保留更多的系统资源,或者降低运行速率,以保证不丢帧。很显然,这种做法一方面带来大量的运行资源的闲置,另一方面降低了我们的运行速度。所以我们引入了动态变速仿真技术。
动态变速仿真技术,本质上是对无人车复杂数据流进行流控的过程。分解来讲:
1)对于处理时间较短的帧,压缩了数据处理的间隔;
2)对于处理时间较长的帧,等待处理完成再继续处理后续的帧。
而整个调度系统是一种根据当前处理帧的耗时做弹性变化。
通过这两项改造,可以达到:不等待 & 不丢帧,这样就可以充分的利用硬件资源,以最快速度运行。据实际测试,采用了动态变速仿真技术,在不影响仿真结果的前提下,单机仿真效率可以提升数倍以上。
{ 八 }
全面的无人车能力判定
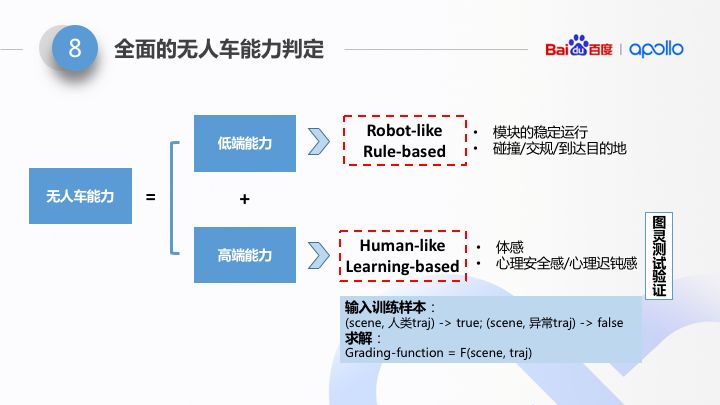
从自动驾驶的能力上看,能力分成两个层面:低端能力(能 work)以及高端能力(像人一样 work well),所以从能力判定的算法上,会有较大的不同。后一种(高端能力级别的判定)很显然是非常有挑战的。
我们先看一下低端的能力判定方法,它包括了两层判定:
Level1:模块的运行可靠性判定。类似模块的 coredump、非法 exit、帧率异常等。
Level2:无人车基础能力的判定。包括:到达目的地、碰撞、违章等。
很显然,这样的两层判定可以通过“通用的规则”来实现。但是此时的通用仅仅代表了无人车能力的下限已经达到。此时无人车仅仅是能够像是机器人一样进行驾驶。
既然有低端能力,就对应有高端能力。何为高端能力?——像自然人一样开车,可以通过图灵测试。它仍然包括了两层判定:
Level3:体感判定。体感判定包括了横摆角,顿挫感等评估体系。
Level4:心理感受。心理感受包括了心理安全感以及迟钝感等。
高端能力的判定。可以是一种图灵测试的验证,是场景特化的。它代表了无人车的能力的上限。
实际上,度量算法的本质可以认为是:f(场景描述,车辆轨迹),即某种场景和轨迹的二元函数。当我们拥有大量的正例以及负例,我们通过机器学习方法,基于大量数据,是可以得到一种具有足够泛化能力的,并且能够达到图灵测试判定能力的度量能力。
事实上,百度长期的无人车路测,使仿真拥有了大量的实际的运营 / 路跑数据,我们针对性的大量采集、标注了细粒度的体感异常的 badcase 样本,进而可以达到相当精准的异常判断能力。我们会在 Apollo 中将这样的能力释放给大家。
-
DASK适用于Python中的并行和分布式计算2022-05-20 4096
-
如何实现无人驾驶硬件平台的设计?2021-11-02 3673
-
介绍无人驾驶硬件平台设计2021-09-09 2877
-
无人驾驶汽车的工作原理是什么?2021-06-28 5732
-
机器学习算法如何用于制造无人驾驶汽车?2021-03-18 2529
-
无人驾驶分级及关键技术2021-01-21 3322
-
适用于Keysight分布式仿真环境的C调试器接口和Keysight 64700系列2019-03-01 1651
-
激光雷达-无人驾驶汽车的必争之地2017-10-20 7035
-
无人驾驶硬件之传感器平台2017-09-30 3601
-
无人驾驶与自动驾驶的差别性2017-09-28 6608
-
无人驾驶电子与安全2017-02-22 4933
-
智能车仿真平台2017-01-05 5673
-
无人驾驶研究平台2016-06-06 13508
-
无人驾驶导航平台2014-11-11 9745
全部0条评论

快来发表一下你的评论吧 !
