

PCI5565反射内存网技术的应用研究
通信网络
描述
随着嵌入式与通信技术的发展,数控系统经历了由传统的单处理器的集中式体系结构到开放式体系结构,再到多处理器的分布式数控系统体系结构的发展过程。分布式数控系统以高精、高速的加工特征为发展核心,同时以达到异构网络间信息的无缝融合,实现高实时性、高可靠性和高兼容性的新一代生产制造系统为发展方向。
针对如何提高分布式数控系统实时通信能力的问题,陶林等[1]提出了一种基于以太网的分布式数控系统实时通信网络; 宋真君等[2]提出了基于工业以太网的分布式控制系统体系结构,虽然以太网技术有良好的稳定性、低成本、高带宽及优良的兼容性等优点,但以太网的CSMA /CD( 载波多路访问、冲突检测)的传输机制决定了它无法确保网络传输延迟,导致其实时性差。金振华[3]提出了基于CAN 总线的分布式数控系统,虽然各种现场总线广泛应用于连接现场设备,有布线简单、硬件成本低、运行精确稳定等优点,但数据传输率低,实时性不高。反射内存网光纤总线不但数据传输率远高于以太网和现场总线,而且是一种实时、确定性的网络,可以较好地解决实时系统中数据传输的实时性问题[4 - 5]。
反射内存技术用于所有使用以太网、光纤通道或其他串行网络将计算机或可编程逻辑控制器连接在一起的应用场合,如实时的飞行仿真器、电讯、高速过程控制( 轧钢厂和制铝厂) 、高速测试和测量系统等,但并非适用于所有应用场合[6 - 8]。因此反射内存网是否适用
于分布式数控系统,如何将反射内存网有效地应用到数控机床中成为反射内存网络应用的关键问题。文中在分析分布式数控系统基本结构和反射内存网工作原理的基础上,提出了一种基于反射内存网的分布式数控系统实时通信网络方案,给出了系统的基本框架结构、节点模型和拓展结构。该结构方案的实现不仅极大地提高了网络带宽,而且也提高了数控系统数据传输的实时性能。
1 分布式数控系统基本结构
分布式数控系统是分布式控制思想在数控系统上的综合应用。随着数控系统功能的增加,数控机床加工速度的提高,许多数控系统采用了多微处理器结构,每个微处理器通过数据总线或者通信方式进行连接,共享系统的公用存储器与I /O 接口,每个处理器分担系统的一部分工作[3,9- 11]。在分布式数控系统中,信号传递对实时性要求越来越高。
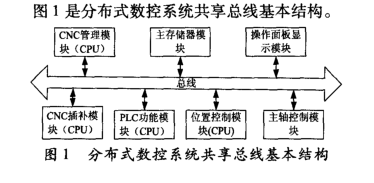
图1 是分布式数控系统共享总线基本结构。
2 反射内存网技术
2. 1 反射内存网工作原理
反射内存网( Reflective Memory Network,RNN) 是一种高速实时网络,是由光纤连接的高速共享内存网络,与一般的基于TCP/IP 协议的局域网一样,也是在每个节点计算机上附加一块网卡。反射内存网接口适配器为各任务设备和反射内存光纤网络相连的接口,具有数据传输及网络管理双重功能,是整个反射内存环网的核心设备。RM 接口适配器主要由光电转换、数据编/解码/并行处理、网络管理状态机、存储器、协议管理模块及任务设备接口等组成,系统功能框图如图2 所示。
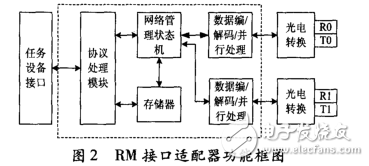
图2 RM 接口适配器功能框图
反射内存网是一种特殊的共享内存系统,每个节点都占有一段对应的内存地址,可以在每一个节点子系统中独立地保存整个系统内存。在实时通信网的节点机上各插一块反射内存卡,卡上带有双口内存,各层软件可以读写这些内存[12 - 13]。反射内存网可以在分布系统中实现内存到内存的通信。当数据被写入一台机器的反射内存卡的内存中后,反射内存卡FPGA 硬件通过光纤自动将数据传输到实时通信网上其他反射内存网中反射内存网节点卡的内存里。通常,一个节点的更新只有不到0. 4 μs 的时间延迟,传输遍历所有反射内存卡,所有反射内存网节点中对应地址都被写入对应数据。因此,实时通信网上各成员在访问数据时,只要访问本地反射内存卡的内存即可[9, 14 - 15]。一个反射内存网节点由本地内存、嵌入式接口和用来提供访问主机和反射内存的仲裁逻辑构成,反射内存网节点可以安装或者连接在不同种类的计算机总线上,包括VME、PCI /PCI - X、PCI Express 等[4]。
2. 2 反射内存网拓扑结构
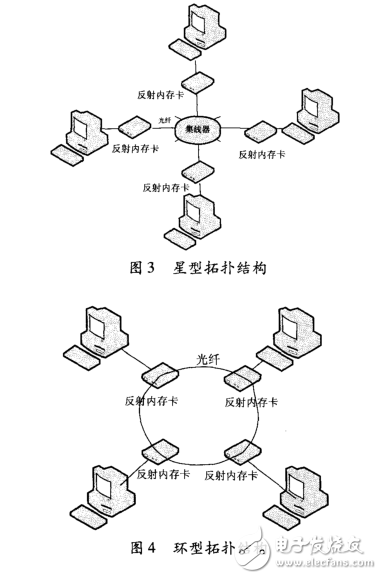
反射内存网主要是由反射内存卡通过光纤等传输介质连接而成的,它主要有两种物理拓扑结构: 星型拓扑结构( 如图3 所示) 和环型拓扑结构( 如图4 所示) 。对于环型拓扑结构的反射内存网,相邻反射内存卡通过输入端和输出端的连接形成一个环形网络,数据包沿着环形网络进行传递。其优点是不需要光纤Hub、光纤使用量小、节省经费; 缺点是每个节点都有延时,如果任何节点或者光纤发生故障时,数据包将不能被发送,从而导致整个传递网络瘫痪。因此,一般采用星型结构。事实上,星型拓扑结构只是一个物理意义上的结构,因为网络集线器内部结构是环型连接。逻辑上来讲,它仍然是一个环型结构[4]。在网络中的每一个节点都有唯一的节点ID,在同一个网络中,不允许有两个一样的标识ID,这个ID 是通过板上的拨码开关进行设置的。ID 号越小,优先级越高。当数据源节点通过集线器发送数据包时,集线器可以根据相邻板的高低ID 来找出数据传递方向,从而实时更新所有节点的相应数据。在星型配置中,如果一个节点不工作时,集线器可以自动屏蔽故障节点,而不影响其他节点的数据传输,当然星型结构的缺点是网络中的Hub 一旦发生故障,整个网络将会瘫痪[16]。图3 星型拓扑结构图4 环型拓扑结构
3 基于反射内存网的分布式数控系统的构建
3. 1 数控系统网络构建根据数控系统信息传输的特点及总体传输要求,拟采用反射内存光纤总线连接CNC 装置、PLC、故障诊断专家系统、HMI 控制面板、CAD/CAM、数控加工仿真模拟系统等部件构成一个分布式数控系统。总线网络的每个任务节点接一个RM( Reflective Memory) 接口适配器,每个RM 接口适配器均集成一块专用的存储空间,系统将该存储空间映射到该网络节点处理系统的地址空间,这样节点处理系统对RM 接口适配器的操作就和对本机内存操作方式一样。当节点任务设备往映射到反射存储器的虚拟地址空间的某个位置写数据的时候,反射内存网络协议在纳秒级的时间内将数据传播到网络上的每个其他节点。并且更新的传播操作是异步的,没有应用系统处理器的介入。数控系统网络连接结构如图5 所示。
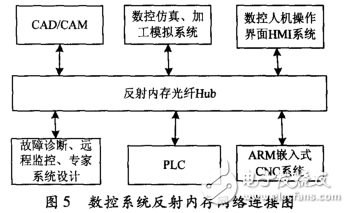
图5 数控系统反射内存网络连接图分布式数控系统工作过程: CAD/CAM 系统对待加工零件建模,并根据加工工艺生成NC 代码[17]; 数控仿真加工及加工模拟系统对生成的NC 代码进行图形仿真,进行预加工,检测是否有刀具干涉等异常现象;HMI( 人机操作界面) 作为工控机的输入和显示单元是系统和用户之间进行信息交换的媒介,显示各种控制信号的状态,操作人员可以通过它对机床进行操作,对机床参数进行设定和修改,加载零件加工文件; CNC模块接收上位机传送的加工代码,通过解释器、插补器生成运动控制指令; 远程监控及故障诊断专家系统通过采集数控系统及机床本体传感器件信息,远程监控机床运行状态,对运行故障进行故障原因分析和故障点定位。如果将这些功能或者系统装在一台计算机上,会增加计算机负载,而插补过程是一个高实时性的过程,用反射内存网络把这些模块分别连接起来,并且其相互之间信息交换几乎没有时间延迟,相当于一台计算机实现的控制,能很好地满足数控机床对加工实时性的要求。
3. 2 反射内存网络通讯过程
由于反射内存网的传输是纯硬件操作,所以不受特定网络协议的限制,也就不用编写复杂的接口程序,软件上只需几行代码就可以完成对反射内存卡的读写操作。整个通讯过程如下:Step1: 打开板卡并复位板卡;Step2: 板卡初始化设置:执行中断初始化函数( INT_Init) ;设置板卡中断包中断使能( RM_IntDataArrive_IntEnable) ;使能光纤收发器( RM_FM_Enable)Step3: 通讯开始
(1) 发送方发送中断包( RM_TxIntPkt) ,中断包中断后,中断处理函数自动调用中断处理函数( RM_Rx-IntPkt) 。发送方发送数据包( RM_TxDatPk) : 当产生一个对SDRAM 的写操作时,反射内存卡自动将数据和其他相关信息( 包括数据地址、节点号等) 写入到发送缓冲器中,在发送缓冲器中,发送电路检测并将数据变成一个4 到64 字节长度可变的数据包,通过光纤接口发送到下一个板卡的接收端口。
( 2) 接收方接收中断包; 中断包中断后,中断处理函数自动调用中断处理函数( RM_RxIntPkt) 。接收数据包( RM_RxDatPkt) ,写入磁盘,开启线程函数查询板卡接收数据包状态( RM_IntStatus) ,先判断本节点是否需要写入数据,若不需要,则直接转发写中断给下一组内节点; 否则,向其反射内存卡中写入数据后发送读中断,接收电路解开数据包并将数据存储到板载的接收缓冲器中,在接收缓冲器中,另一个电路将数据写入到本地的SDRAM 的和源节点相同的地址中。同时该电路将数据发送到发送FIFO 中,重复这个处理过程直至所发送的数据返回到源节点接收端,然后源节点将节点ID 相同的数据从网络中删除,从而实现所有节点都被更新。重复上述流程。退出程序,关闭板卡( RM_Card_close) 。
3. 3 带宽及实时性分析高速、高精加工中插补周期一般控制在1 ~ 2 ms,插补周期越短,以直代曲插补直线段越逼近实际加工曲线,加工精度越高。对于分布式数控系统而言,地理位置上相对独立的各个单元通过网络通信系统进行互联,数据传输的带宽及实时性会极大地影响实际加工效果。

表 1 为几种数控系统中常用网络通信方式的对比情况。文中采用的发射内存网带宽最高可达1. 06Gbps,网络传输延迟为400 ~ 750 ns,这两个指标都明显优于FDDI( Fiber Distributed - Data Interface) 、CAN、工业以太网及PROFIUBS 现场总线。表1 几种通讯网络对比网络类型带宽实时性分析RMN 1. 06 Gbps 节点确定的传输延迟为400 ~ 750 nsFDDI 100 Mbps光缆延迟和站延迟使其响应时间至少为> 5msCAN 1 Mbps数据率很低,速度低,一般响应时间5 ~ 10ms工业以太网100 MbpsCSMA/CD 的传输机制决定了它无法确保传输延迟的确定性,导致其实时性差。传输延迟可达到1 ~ 10 msPROFIBUS < 12 Mbps 响应时间> 10 ms4
结束语文
中对反射内存网技术应用于数控系统这一极富研究价值的领域作了初步探索,提出了一种基于反射内存网的分布式数控系统实时通信网络方案,给出了系统的基本框架结构、节点模型和拓展结构。在实际应用中,可以考虑把反射内存网同以太网相结合,在强实时部分使用反射内存网,在弱实时部分则利用以太网,实现资源的充分利用,降低开发成本。
-
深度解析pci接口反射内存卡2024-10-16 2194
-
VMIC-5565反射内存2024-10-15 1164
-
pci接口反射内存卡2024-09-06 614
-
PCI 接口的反射内存卡2024-09-04 1265
-
PCI5565反射内存卡系统结构与使用2023-11-29 1946
-
浅谈VMIPCI5565反射内存卡PCIE5565反射内存交换机这两种数据传输方式的特点和优势2023-11-13 1625
-
5565系列反射内存卡详细说明2023-07-04 2928
-
VMIPCI5565反射内存卡PCI-5565反射内存 VMIC-5565多模 PMC5565 1553B协议光达航电科技 2023-06-25
-
RFM反射内存5565控制和状态寄存器2018-08-13 2416
-
光纤反射内存-GE-55652018-01-13 8158
-
2015反射内存卡组网结构 -带水印2017-10-14 1197
全部0条评论

快来发表一下你的评论吧 !
