

能透过333口诀,快速理解AI到底是什么
电子说
描述
所谓人工智能(Artificial Intelligence;缩写:AI),是指以人工方式来实现人类所具有之智慧的技术。只不过,目前能实现与人类智能同等的技术还不存在,世界上绝大多数的人工智能还是只能解决某个特定问题。本篇文章是在我阅读了几本AI的相关书籍后,所概略统整出的架构,希望让初次接触AI的读者,能透过333口诀,快速理解AI到底是什么。
一、AI的三次浪潮
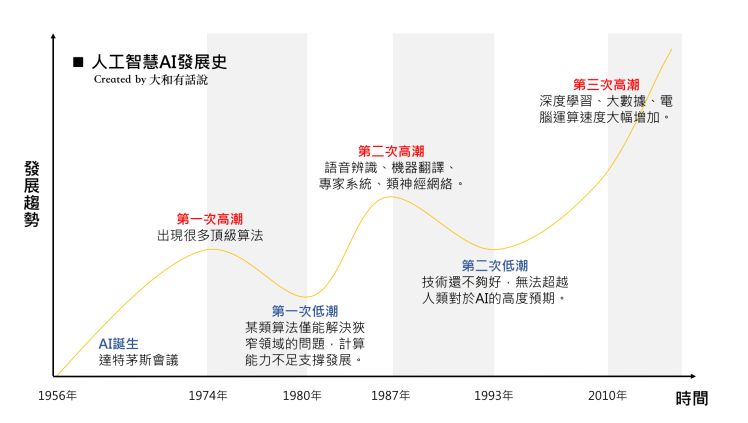
人工智能AI发展史
第一次AI浪潮
第一次AI浪潮起于1950~1960年,止于1980年代。由于出现在网络之前,因此又被称为“古典人工智能”。这时期出现的“符号主义”与“联结主义”,分别是日后“专家系统”与“深度学习”的雏形。只不过,虽然当时的成果已能解开拼图或简单的游戏,却几乎无法解决实用的问题。
第二次AI浪潮
第二次AI热潮伴随着计算机的普及,出现在1980年代。这时期所进行的研究,是以灌输「专家知识」作为规则,来协助解决特定问题的“专家系统”(Expert system)为主。然而,纵使当时有商业应用的实例,应用范畴却很有限,热潮也因此逐渐消退。
第三次AI浪潮
第三次AI浪潮则出现于2010年代,伴随着高性能计算机、因特网、大数据、传感器的普及,以及计算成本的下降,“机器学习”随之兴起。所谓机器学习(Machine leaning),是指让计算机大量学习数据,使它可以像人类一样辨识声音及影像,或是针对问题做出合适的判断。
二、AI的三大技术
快速了解了AI的发展史后,我们来看看当代人工智能的三大代表性模型:遗传算法、专家系统、类神经网络。
1、遗传算法 遗传算法(Genetic algorithm;GA),又称为演化式算法(Evolutionary algorithm),是受达尔文演化论所启发的人工智能。它透过「适者生存」的规则,将“优秀的个体”想象成“好的答案”,透过演化的方式来找出最佳解。
2、专家系统 专家系统(Expert system),则是针对预设的问题,事先准备好大量的对应方式。它应用在很多地方,尤其是疾病诊断。只不过,专家系统只能针对专家预先考虑过的状况来准备对策,它并没有自行学习的能力,因此还是有其局限性。
3、类神经网络 从第三次AI浪潮所兴起的机器学习(Machine learning)有许多种手法,其中最受瞩目的,莫过于深度学习(Deep learning)了。所谓深度学习,是透过模仿人脑的“类神经网络”(Neural network)来学习大量数据的手法。
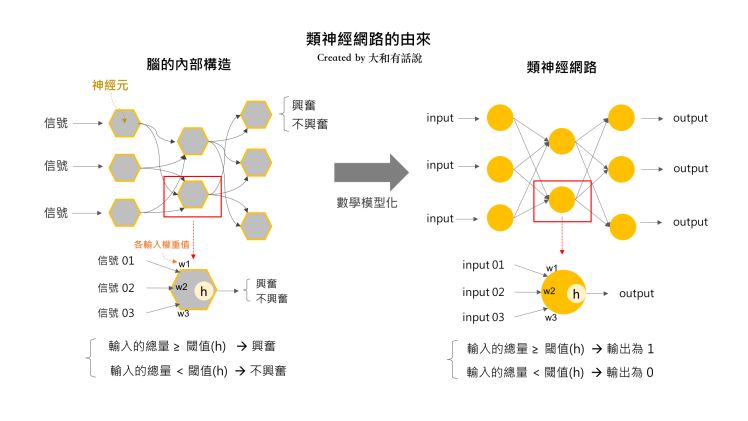
类神经网络的由来
若你去观察脑的内部,会发现有大量称为“神经元”的神经细胞彼此相连。一个神经元从其他神经元那里接收的电气信号量达某一定值以上,就会兴奋(神经冲动);在某一定值以下,就不会兴奋。 兴奋起来的神经元,会将电器信号传送给下一个相连的神经元。下一个神经元同样会因此兴奋或不兴奋。简单来说,彼此相连的神经元,会形成联合传递行为。我们透过将这种相连的结构来数学模型化,便形成了类神经网络。
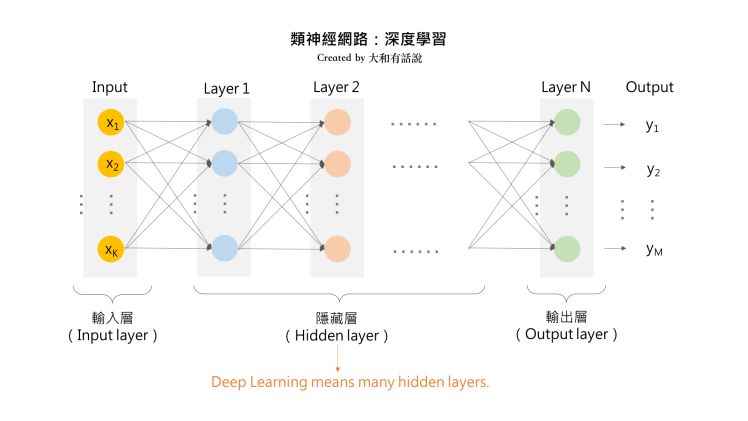
类神经网络:深度学习
我们可以发现,经模型化的的类神经网络,是由“输入层”(Input layer)、“隐藏层”(Hidden layer)及“输出层”(Output layer)等三层所构成。另外,学习数据则是由输入数据以及相对应的正确解答来组成。 以影像辨识为例,为了让AI学习类神经网络的模型,首先必须先将影像学习数据分割成像素数据,然后将各像素值输进输入层。 接受了数据的输入层,将像素值乘上“权重”后,便传送给后方隐藏层的神经元。隐藏层的各个神经元会累加前一层所接收到的值,并将其结果再乘上“权重”后,传送给后方的神经元。最后,经由输出层的神经元的输出,便可得到影像辨识的预测结果。 为了让输出层的值跟各个输入数据所对应的正解数据相等,会对各个神经元的输入计算出适当的“权重”值。 这个权重的计算,一般是使用“误差倒传递算法”(Error Back Propagation),使用与正解数据之间的误差,从输出层逆推回去。透过各「权重」的调整,来缩小输出层的值与正解数据的值之间的误差,以建立出完成学习的模型。 由于过去类神经网络之间进行传递的权重值难以优化,因此曾有多数研究者对类神经网络的研究持否定态度。直到2006年,辛顿(Geoffrey Hinton)开发出自动编码器(Autoencoder)的手法,才突破了这项瓶颈。 自动编码器是指,在类神经网络的输入层和输出层使用相同数据,并将隐藏层设置于二者之间,藉此用来调整类神经网络之间的权重参数的一种手法。
利用以自动编码器所获得的类神经网络权重参数值进行初始化后,便能应用「误差倒传递算法」,提高多层类神经网络的学习准确度。 透过类神经网络,深度学习便成为了“只要将数据输入类神经网络,它就能自行抽出特征”的人工智能,而这又称为“特征学习”(feature learning)。 深度学习最擅长的,是它能辨识图像数据或波形数据这类无法符号化的数据。自2010年代以来,如Google、Microsoft及Facebook等美国知名IT企业,都开始着手深度学习的研究。例如,苹果「Siri」的语音识别,Microsoft搜索引擎「Bing」所具备的影像搜寻等等,而Google的深度学习项目也已超过1,500项。 至于深度学习如此飞跃的成长,要归功于硬设备的提升。图形处理器(GPU)大厂辉达(NVIDIA)利用该公司的图形适配器来提升深度学习的性能,提供链接库(Library)和框架(framework)产品,并积极开设研讨课程。另外,Google也公开了框架「TensorFlow」,可以将深度学习应用于数据分析。
三、AI的三大应用
AI应用领域主要可分为语音识别、影像辨识以及自然语言处理等三部分。
1、语音识别
语音识别部分,透过多年来语音识别竞赛CHiME的研究,已经有了等同人类的辨识度(CHiME,是针对实际生活环境下的语音识别,所进行评测的国际语音识别竞赛)。此外,Apple、Google、Amazon也相继提出可应用于日常生活的服务,因此其成熟度已达到实用等级。
2、影像辨识
影像辨识部分,虽然一般图片的辨识已有同等于人类的辨识率,但动态影像的辨识准确度却仍比不上人类,目前还在进行各种算法的测试。其中,影像辨识目前最火热的应用场域非自动驾驶莫属了。 整个汽车、信息通讯产业都正朝着自驾车的方向努力,例如Google持续进行自动驾驶的研究,TOYOTA也在美国设立丰田研究所,可以知道现阶段的开发已十分接近实用化。因此,我们可判断目前影像辨识的成熟度是介在研究和实用等级之间。
3、自然语言处理
自然语言处理(Natural language processing;NLP),是试着让人工智能能理解人类所写的文字和所说的话语。NLP首先会分解词性,称之“语素分析”(morphemic analysis),在分解出最小的字义单位后,接着会进行“语法分析”(syntactic analysis),最后再透过“语意分析”(semantic analysis)来了解含意。 输出部分,自然语言处理也与生成文法(generative grammar)密切相关。生成文法理论认为,只要遵循规则即可生成文句。这也代表着,只要把规则组合在一起,便可能生成文章。 在自然语言处理中,最具代表性的应用就是“聊天机器人”(Chatbot)了,它是一种如真人般,可透过文字讯息与人对话的程序。2016年,脸书推出了“Facebook Messenger Platform”,而Line也推出了“Messaging API”,因而促使这种搭载NLP技术的聊天机器人成为瞩目的焦点。 另外,由IBM所开发的华生(IBM Watson),也是应用NLP的人工智能而成。华生可以从维基百科等语料库中抽取知识,学习词汇与词汇之间的相关性。现在,就连软件银行(SoftBank)机器人Pepper也是搭载华生系统。 只不过,由于在日常对话中,我们很常省略词句,也不一定会提及时空背景,因此当前的Chatbot尚无法与人类进行天花乱坠的对话。所以说,现行多数的Chatbot厂商,还是会限定对话的环境与应用领域。
-
PLC到底是什么呢?2014-10-10 5329
-
这是到底是什么元件?2016-05-26 5134
-
请问CKFA到底是什么2018-08-20 2568
-
这个到底是什么电路2019-01-20 1311
-
请问NPU到底是什么?2020-12-08 2958
-
DSP到底是什么?DSP的要素是什么?2021-03-05 3383
-
如果买了5G手机,能达到的理论速率到底是多少呢?2021-06-18 5150
-
QPainter到底是什么?2021-09-28 1889
-
STM32固件库到底是什么?2021-11-30 2295
-
RGB屏到底是什么?2022-02-14 1986
-
呼吸灯到底是如何影响人的视觉的?2023-11-08 629
-
车规级芯片到底是什么本文带你快速了解2019-03-17 27810
-
单片机P0口的AD0-7到底是什么意思2019-07-11 3296
-
边缘AI它到底是什么?能做什么?2024-01-11 2705
-
IEC 到底是什么?为什么它能影响全球?2025-09-04 4360
全部0条评论

快来发表一下你的评论吧 !
