

一文读懂数据的可靠性和持久性
存储技术
描述
越是基本而关键的概念,越容易误解满天飞。像“可靠性”这种被不断提及的名词,如果仔细分辨就会发现里面充斥着各种似是而非的误解和误用。
一、持久性、可用性,傻傻分不清
我们一般所说的“可靠性”,其实是个比较模糊的概念,里面包含持久性和可用性两个层面的意思。
打开AWS S3的介绍页面(https://aws.amazon.com/cn/s3/details/),会看到这样一句话:
“设计目的是在指定年度内为对象提供99.999999999% 的持久性和 99.99% 的可用性。”
这是一句很严谨的表述,如果你已经完全理解这句话的意思,就可以直接跳过本节往下看了。
但如果你似懂非懂还看着“持久性”这个词不怀好意的怪笑,说明你不仅歪脑筋太多,而且当初数据库基础知识没学好,这里的持久性概念,就是从数据库的持久性概念借鉴来的。
持久性和可用性的含义,可以用下面这个图来理解。
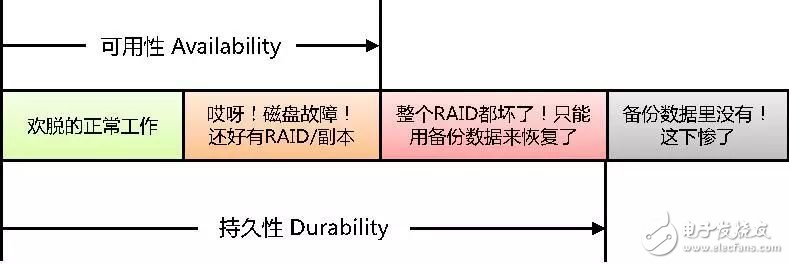
这个图只是简要的说明含义,实际系统中还有集群、容灾等等各种环节,为了不分散焦点,无关本质的部分都略去不提。
简单的说,数据可访问就叫available——可用(这个翻译很靠谱)。而数据暂时不可访问,但是过段时间费些力气能找回来,这样的状态已经不能叫available,但仍然属于durable——持久(这个翻译实在让人抓狂,可是既然从早年数据库领域就一直这么翻译,现在已经成了固定用法,手动无奈)。只有数据彻底丢失,永远找不回来的状态,才超出durable的范围。
可见,持久性比可用性更基础,前者是后者的必要非充分条件。从数值描述上,持久性≥可用性。
另外,讨论持久性和可用性时,需要限定边界条件。孤立系统给出的量化指标,仅指裸奔时的表现,实际使用中还要看外面披着什么样的使用方式。
比如AWS S3给出的那个承诺,持久性99.999999999%的含义,就是每年100000000000个对象中,可能会有1个对象丢失。这当然是个貌似很可靠的系统,假设你租来1百亿个对象,想等着看到其中一个崩溃的话,可能要等10年。
可是且慢,Stack Overflow上曾有个顽皮的提问者,他说如果往AWS S3上存1百亿个文件,是不是10年之内就可能出现文件丢失?
鉴于S3主要用于长期数据归档,且在全球范围用量之大,这个提问并不算抬杠。也就是说,霸道如AWS的11个9持久性,也未必足以支撑浩瀚的数据海洋直到地老天荒。
当然这个提问者并不是真的发现了什么死结,后面的应答者很快就告诉他,只要在存文件的时候,增加一些校验容错机制,就能在S3对象崩掉几个的时候仍然保持文件的完好无损。
对搞存储的人来说,这个道理实在太容易理解了,就是在S3对象上做RAID嘛。这个模式可以推而广之,但凡你对某个系统裸奔的可靠性不够放心,就想办法在上面“做RAID”即可,只要小心别用RAID-0扩大故障概率就行。
总之,理解了持久性、可用性这些概念,并知道哪些受限于设备,哪些掌握于自身,以后再看到那种一味强调几个9的产品宣传,就不至于被轻易忽悠。
二、时间边界和故障规律
一般谈论持久性和可用性,都需要或隐或显的在百分数前面加个“年度”的限定。比如99%可用性,是指每年宕机时间不超过3.65天,即87.6小时。而99.9%可用性,就意味着每年宕机时间不超过8.76小时。人们常提的5个9高可用,即99.999%可用性,折算下来每年宕机时间才仅有5.256分钟。
那么一个霸气侧漏的每年5个9高可用系统,在100年时间里可用性是多少呢?理论上似乎是仍然足够威风的99.9%可用性(精确计算结果应该是略小于99.90005%一丢丢),可是这显然不太合常理。再强壮的硅基物种,在机房里负重蹲上100年,肯定早就彻底散架了。
所以持久性和可用性的另外一个隐含限定——正常寿命之内。可惜对硅基物种正常寿命的界定,也是真假信息混杂。
以最常出故障的磁盘设备为例,每个磁盘型号都有一个MTBF指标(Mean Time Between Failure,平均无故障时间),来声明其可靠性。具体的定义和解释随处可以查到,我就不废话多说。
关于MTBF,我只有一句奉劝:
不要相信!不要相信!永远不要相信!重要的事情说三遍。
作为标榜品质的主要规格指标,磁盘的MTBF已经彻底沦落纯粹吹牛手段,数值从起初还算靠谱的几万小时,一路涨到极度夸张的几百万小时。
100万小时=114年!
你要是真相信有磁盘可以用这么久的话,本文后面的部分也就没必要看下去了。
所幸早在2007年,谷歌的几位大牛就气不过这种不负责任的胡说,用一篇名为《Failure Trends in a Large Disk Drive Population》的论文怒怼硬盘厂商。论文中统计了数万颗磁盘的运维数据,发现实际环境中企业级磁盘和桌面级磁盘的故障概率非常接近,几乎无差别。而厂商却对两种磁盘的MTBF标注差别明显,甚至相差数倍。无论哪种盘,实际统计的AFR(年故障率)都远高于MTBF的推算值若干数量级。
顺便提一句,论文还指出磁盘实际AFR会高达3~8%,远高于磁盘厂商根据返厂报修统计的0.4~1.2%每年。这中间的差额部分去了哪里,大家自行脑补吧。人艰不拆。
谷歌论文的统计对象,都是使用5年以内的磁盘。磁盘的原厂保修期一般也都是5年。这个寿命选择来源于磁盘故障率的U型分布规律。
一般磁盘故障多发生在新上线3个月之内,或是临近保修期结束前后,中间的阶段相对比较消停。
新磁盘的故障,主要由制造过程的疏漏或错误造成。比如盘体密封不严,就会在上线工作后很快发生故障。这属于硅基物种个体的先天缺陷导致的夭折。这类问题在经过一段时间负载后,很快就会全部暴露。
接下来,系统中剩下一群健康的青壮年磁盘,故障率自然会明显下降。然而磁盘这种每分钟要旋转成千上万次的物种,在欢脱的旋转了几万小时之后,还是会铁杵磨成绣花针,最终迎来衰老期。于是故障率又开始上升。
需要注意,磁盘的损耗速度与工作环境和负载有密切的关系。在悠闲舒适的环境中可以顺利撑到5年的磁盘,换到负载繁重残酷压榨的环境里肯定要折寿。
从谷歌那篇论文里可以窥见,谷歌的数据中心一定是个残酷压榨磁盘的血汗工厂,因为里面的磁盘在2年左右就已经开始明显衰老。贴张论文中的图示,大家感受一下。
说了这么多,总结起来就是硅基物种跟我们这些碳基物种一样,都有生老病死的全过程。讨论硅基物种的可靠性,就如同讨论我们碳基物种的健康度,不仅个体间有差异,而且每个个体的情况也随时间和环境的变化而变化。
三、可靠性的量化计算
对可靠性的量化计算,绝对是各种错误频生的重灾区。如果在网上搜索这方面的计算方法,包括来自产品厂商、大学研究机构、社区论坛自由人士等各方面给出的种种计算公式和计算逻辑,80%以上都存在错误和漏洞。
有实际运维经验的机房背锅侠们,见多了这种貌似有理实则计算结果很扯的各类公式之后,都会对系统可靠性心生迷之不可知,继而抛弃多年的理工科信念,毅然走上迷信的道路。
为了挽救迷途的运维工程师,重振数理化的威望,我们还是认真看看可靠性到底怎么计算吧。
对于简单系统,相信理工科毕业的同学们还不至于被搞晕。
比如串行系统(RAID-0就是典型)中,所有单元都健康时系统才健康,所以系统健康概率计算方法就是每个单元健康概率的相乘。类似的,并行系统(比如多副本)中,所有单元都故障时系统才故障,所以系统故障概率是所有单元故障概率的乘积,而健康概率就是1减去故障概率。
脑力热身完成,我们现在考虑一个稍微复杂一些的系统。
假设一个n节点的分布式存储系统,每个节点中m颗磁盘,系统中采用k副本数据保护,副本都是跨节点保存,每颗磁盘的健康概率是p,那么系统的总体健康概率是多少呢?
好吧,我承认,难度跳跃比较大,从热身的基本概念直接跳到这里的确少了些铺垫。那我们至少先琢磨一下,这些条件是否足够推算出系统的可靠性,是否还需要增加哪些限定条件。
敲黑板!重点来了!
大部分网上的错误计算逻辑,其实都忽视了同一个因素——时间。
我在前一节提到过,如果一个单元或系统,在1年里的可靠性是99%,那么它在1天里的可靠性应该是99.997%,在10年里的可靠性又变成了90.4%。不统一时间跨度之前,不能量化计算。就像各种理财产品一样,有的3个月赚2%,有的5年赚20%,要想比较哪个收益率高,首先必须把收益换算为年化收益率。可靠性也是一样,在计算过程中,时刻需要注意“年化”处理。
我们再看刚刚题目中n、m、k、p几个条件,除了p需要考虑年化之外,似乎其他几个条件都跟时间没有直接关系,我们应该可以开始推算了。
先别急,我们还需要考虑另外一个问题——什么状态是故障状态?
一定会有人不假思索脱口而出,多盘同时故障,多到k副本全都坏了,就是故障状态。可是,哪里有严格意义的“同时”呢?所有磁盘在同一月或同一年里全都坏过一遍,算不算“同时”呢?
我相信大多数明白人嘴里这么说的时候,心里想的其实就是多盘故障的时间点过于密集,以至于k副本全坏光之前,都来不及修复出一份好数据。这才是我们常说的“多盘同时故障”实际所指的真实含义。
基于这样的认识,我们知道在判定系统是否故障时,其实隐含着一个时间因素——数据修复所需要的时间窗口,也称为降级(Downgrade)时间窗口。
这个时间窗口是从健康状态下第一颗磁盘故障算起,直到修复回健康状态为止。其中一般包含备件更换时间t和数据重建时间τ,总降级窗口为t+τ。
现在的很多分布式存储为了缩短这个降级窗口,可以不等更换坏盘,直接在现有空闲空间进行重建。这种情况下t=0。数据修复重建无论如何都需要时间开销,所以τ总不会为零。
我们现在知道刚才那个系统中,必须再附加t和τ两个因素,才能进行可靠性计算。
到此铺垫结束,公式出场。系统年化健康概率H的计算公式如下:
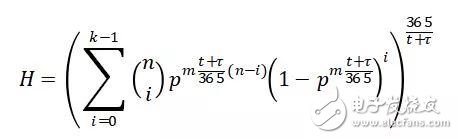
公式中t和τ的单位为天。
我还得承认,推演这个公式的过程中,没有考虑故障的U型分布,而是简单的用平均分布代替。至于原因嘛,我当然不会承认自己懒,也不会卖萌说等着大家来完善云云。我只是觉得未来的海量系统不会再像现在这样分批次规划建设,而是滚动式持续建设。那样的话,系统中不同批次的设备混在一起,各年龄段都有,这个U型分布问题也就自然会被熨平。
暂时懒(kan)得(bu)看(dong)公式的同学也不要发飙,我列这个公式出来主要是想证明理工科信念还是要坚持,不能因为网上哪些逻辑有漏洞的错误就颠覆轻易放弃自己的信仰。只要考虑的因素周全一些,即便复杂系统里,也可以量化计算健康概率。
有兴趣的同学可以试试用这个公式描画一下H(n)、H(m)、H(t+τ)曲线,看看各个变量如何影响系统健康概率H的变化。相信你会有很多符合实际经验,又颇感新鲜意外的感受。
我自己也做了一些延伸的变量曲线图,这里就不贴出来了。有缘的话,等到4月14日深圳GOPS大会上跟大家分享。
这次GOPS大会上,我还要介绍一项彻底推翻可靠性构筑逻辑的新技术——磁盘故障预测。没地方打广告,就只能借自己的文章广告一下了。
-
一文读懂芯片可靠性试验项目2025-02-21 1998
-
#硬声创作季 #可靠性 电子封装可靠性评价中的实验力学方法-2水管工 2022-09-29
-
对高级持久性威胁(APT)有什么应对措施?2021-05-24 1612
-
单片机应用系统的可靠性与可靠性设计2021-01-11 4342
-
什么是高可靠性?2020-07-03 14301
-
Intel Optane DC持久性内存讨论2018-11-12 6390
-
持久性内存编程工具的介绍2018-11-08 4138
-
GO语言的可靠性和持久性2017-09-28 2898
全部0条评论

快来发表一下你的评论吧 !
