

基于FPGA的异构计算是趋势
电子说
描述
算起来,人工智能(AI)概念已经提出60多年了,而最近两年,得益于智能终端的普及带来的数据爆发式增长,以及深度学习、神经网络算法的发展,AI市场受到了空前的关注,但AI要得以快速普及,还缺少高算力的推动,需要提供更好的硬件加速条件。
2018年4月17日,业界领先的异构加速和业务卸载方案提供商杭州加速云信息技术有限公司在京举办了科技峰会及新产品发布会,隆重发布了四大创新产品(两个系列硬件加速产品(SC-OPS, SC-VPX)、两个IP库 (FDNN, FBLAS))及三大解决方案(深度学习解决方案、高性能计算及数字信号处理解决方案、边缘计算解决方案)。
抢先布局异构计算
杭州加速云信息技术有限公司创始人兼CEO邬刚是学习通信出身,最早跟随中国程控电话交换机之父邬江兴院士进入通信行业。两年之后,他加入了华为负责芯片设计。2007年开始创业,创办过3家公司,对CPU总线、多核处理器的发展有着清晰的理解。经过多年的积累和对未来市场的预估,2015年9月,邬刚先生创办了加速云。
杭州加速云信息技术有限公司创始人兼CEO 邬刚
加速云的解决方案可以广泛应用于深度学习、人工智能、金融、机器视觉等领域。目前已与阿里、腾讯、科大讯飞等多家企业开展深入合作。
“加速云是从技术上推导出来的一家公司,起源于2014年我们家迎来第一个小朋友,在陪产过程中形成的一个想法。” 邬刚先生提及创办加速云的心路历程,“在2014年,按照英特尔的发展,下一步一定是异构,我们当时认为异构,要么用GPU,要么用FPGA。英特尔在GPU上有一次失败尝试,加上GPU自身功耗太高等问题,FPGA会是异构计算的一个理想选择。”
事实上,在加速云诞生之初已经拥有强大的技术储备。基于FPGA来做异构计算是邬刚先生2014年4月就想出来的计划,直等到2014年10月英特尔在IDF大会上宣布x86+FPGA处理器,他认为这个机会点来了,11月份正式开始研究,到2015年4月,研发出了第一代原型机,2015年9月开始量产,加速云公司随之注册。
在深度学习中,做好算法只完成了1/3,在这个团队里面,既需要很强的实现算法的能力,还要有非常强的工程化能力,这种工程化的能力,包括接口和实现量产的能力。“我们知道做出一个东西很容易,但是做好还是挺难的。我们有一个非常小的板卡,迭代了四代,每一次迭代都要花百万人民币,因为硬件投入很大,每次迭代有可能只改了一点,我们发现未来可能存在的一些风险问题,就把它改掉,这是我们团队特别的地方。我们是一个工程化能力非常强的团队,整体技术行不行是我们最重要的考量。” 邬刚先生介绍。
基于FPGA的异构计算是趋势
目前处于AI大爆发时期,异构计算的选择主要在FPGA和GPU之间。尽管目前异构计算使用最多的是利用GPU来加速,FPGA作为一种高性能、低功耗的可编程芯片,在处理海量数据时,FPGA计算效率更高,优势更为突出,尤其在大量服务器部署时,隐形的运营成本会得到显著降低。
此外,低延迟、确定性延迟,也是FPGA天然的优势。
邬刚表示:“人工智能已经进入我们的生活,但是未来发展还存在瓶颈,需要硬件技术和算法方面的突破。异构计算是计算架构的未来趋势,而FPGA 是实现异构计算的完美选择。加速云创新的异构计算加速平台解决方案,具有高性能、高效率、低延时特性以及可编程性和远程可重构能力,非常适合云上的弹性业务的需求。我们希望能够通过我们的技术,帮助更多的企业实现深度学习,在大数据时代赢得先机。”
全球最高性能FPGA加速卡
SC-OPS是加速云推出的全球首张Intel Stratix 10 FPGA加速卡,采用Intel最新14nm工艺的Stratix10 GX2800 FPGA器件,单板支持12个200维双精度线性方程求解,运算时间为466us,为x86系统60~120倍性能;单卡可以实现4500帧/S以上图像分类(采用AlexNet卷积神经网络模型,int16)。
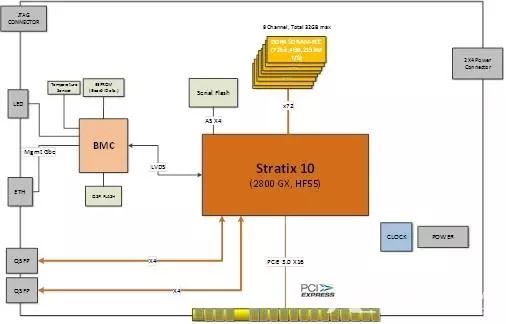
SC-OPS可以广泛应用于数据中心、云计算、机器视觉、深度学习、高性能计算、仿真、金融等领域。
全球最高集成度VPX业务卡
SC-VPX是全球计算密度最高的VPX刀片加速平台,采用Intel Stratix 10 GX2800器件,兼容GX1650,构造业界先进、灵活、高效的信号处理和深度学习架构,主要定位高校研究所等单位的雷达、通信、深度学习相关领域的产品原型快速搭建和算法开发与应用。
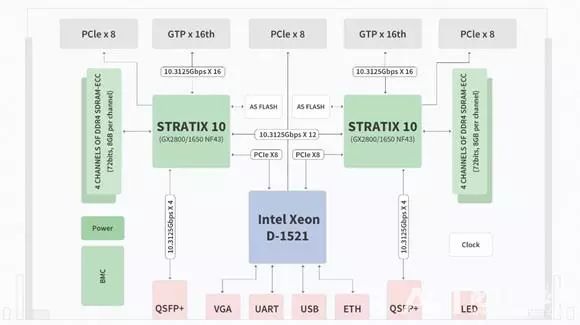
6U整机可以支持92T/50T FLOPS单精度浮点处理能力,整机可以通过交换板互联构筑更大的系统;支持OpenCL、Verilog开发,支持高性能计算库。
RTL级深度学习加速库
深度学习加速库FDNN是国内首个支持通用卷积神经网络的FPGA加速库,基于RTL级代码,可以提供很高的性能和灵活配置特性。
参数可配置的深度学习基础库:卷积、池化、全连接、非线性函数;兼容CAFFE/TensorFlow模型数据;常见各种模型:VGG16, Lenet, YOLO, SSD, ResNet。
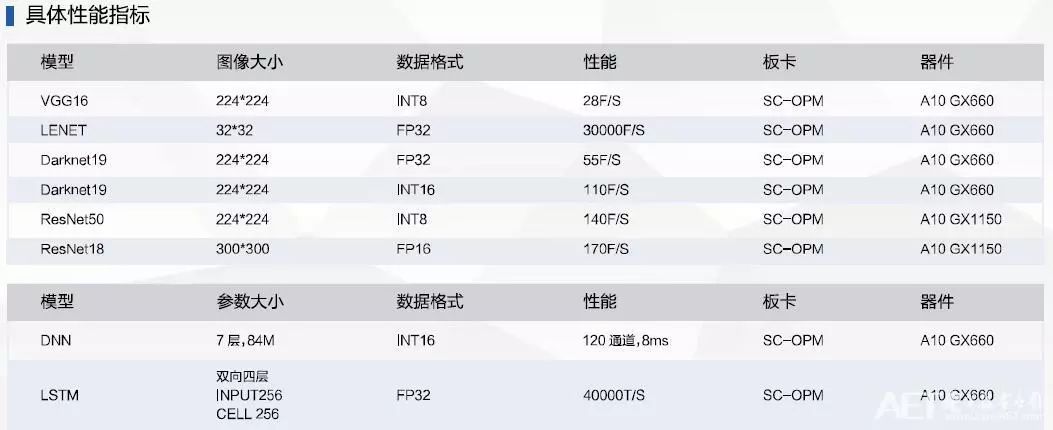
RTL级高性能数学加速库
高性能计算加速库FBLAS是业界更高性能的RTL级数学加速库。参数可配的OpenBlas库Level2/3:矩阵乘、矩阵分解、矩阵求逆,线性方程求解、微分方程求解,三角函数、非线性求解、超越函数,傅里叶变换。
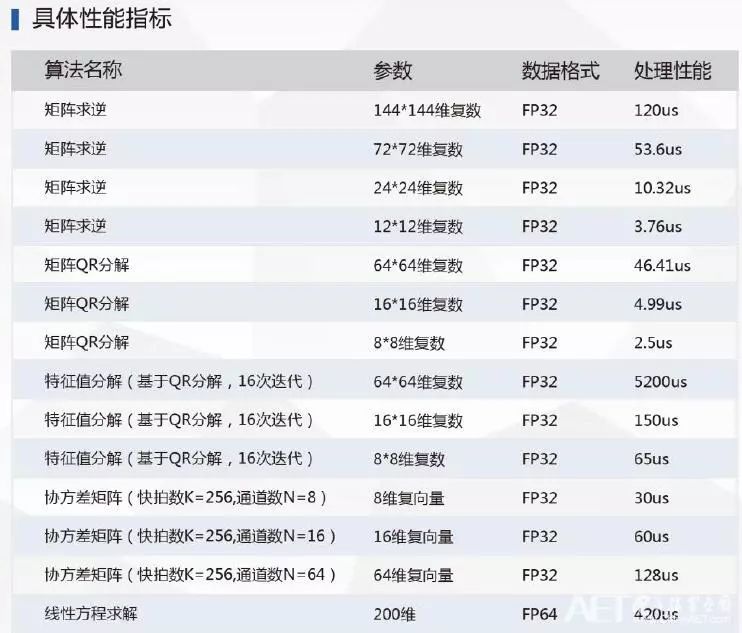
FDNN是专门为深度学习设计的,FBLAS更多是偏向于数字信号处理和高性能计算。
三大解决方案
•深度学习加速解决方案-加速云推出一整套基于FPGA的深度学习加速方案,包括SC-OPM/SC-OPF/SC-OPS加速卡及FDNN加速库,满足客户对深度学习高性能、灵活性加速要求。为了方便客户使用高层语言开发,加速云提供基于FPGA完整的OpenCL异构开发环境,快速实现用户自定义的深度学习加速方案。同时加速云也提供快速深度神经网络定制加速服务。
•数字信号处理解决方案-针对雷达、通信等数字信号处理系统的要求,结合Intel最新14nm工艺的 Stratix10 FPGA系列,加速云提供了一套完整的硬件和软件相结合的解决方案,实现了高性能矩阵运算(矩阵乘、转置、求逆、QR分解)和超高速FFT(傅立叶变换)。为了方便客户使用高层语言开发,加速云提供基于FPGA完整的OpenCL异构开发环境,快速实现用户自定义的信号处理加速方案。
•边缘计算解决方案-加速云智能工控解决方案采用高性能Intel Arria10 GX660器件, 具有模块化设计,强实时特性和高性能的算法IP加速、完整的OpenCL异构开发环境,可以实现新一代高性能边缘计算网关,应用于各种工业环境。
加速云最核心的竞争力在于其IP方面,除了用于数字信号处理和高性能计算的数学库FBLAS,以及用于深度学习的FDNN库,还具有很多接口类的IP(高速通信接口、视频接口)、协议类IP(压缩、解压缩、加解密),研发团队在FPGA方面有着十多年的经验,积累了很多相关的IP。
凭借自身在FPGA上的技术优势,加速云获得合作伙伴的大力支持,可以率先拿到英特尔第一批流片的内部测试芯片,对加速云保持技术领先非常重要。
北京站是加速云“加速新科技,驱动智未来” 科技峰会的首站,接下来加速云将在上海、成都、西安三大城市分享其最新成果。过去两年,加速云平均每年都有获得一次融资,据悉,第三轮融资正在达成。
-
「深圳云栖大会」大数据时代以及人工智能推动下的阿里云异构计算2018-04-04 1749
-
异构计算在人工智能什么作用?2019-08-07 3603
-
什么是异构并行计算2021-07-19 2164
-
异构计算的前世今生2021-12-26 3238
-
异构计算场景下构建可信执行环境2023-08-15 1004
-
异构计算芯片的机遇与挑战2017-09-27 1422
-
深度解析FPGA异构计算芯片的技术特性2017-10-24 6651
-
FPGA异构计算现状及优化2017-11-15 8966
-
异构计算是未来趋势,看加速云玩转FPGA2018-06-08 1826
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 23449
-
异构计算,你准备好了么?2018-09-25 677
-
异构计算面临的挑战和未来发展趋势2023-04-26 2914
-
异构计算:解锁算力潜能的新途径2024-07-18 25431
-
【一文看懂】什么是异构计算?2024-12-04 3812
-
异构计算的概念、核心、优势、挑战及考虑因素2025-01-13 1781
全部0条评论

快来发表一下你的评论吧 !
