

深度学习和机器学习深度的不同之处 浅谈深度学习的训练和调参
人工智能
描述
近年来,深度学习作为机器学习中比较火的一种方法出现在我们面前,但是和非深度学习的机器学习相比(我将深度学习归于机器学习的领域内),还存在着几点很大的不同,具体来说,有以下几点:
1、深度学习,顾名思义,网络变深了,这就意味着这种深度学习类的网络可能有更多的layers,这意味着什么呢?也即表示这种深层的网络需要学习更多的参数,尽管我们知道在CNN中有共享参数等等技巧,但在此前提下,不妨认为随着网络层数的增多,需要学习的参数也在增加,那问题又来了,参数增加有什么问题吗?当然有问题,这是我们在机器学习领域内探讨的最多的一个问题,因为我们的目的都是为了减少泛化误差,提高模型的泛化能力,而在这一点,显然深度学习比一般意义的机器学习模型要复杂,复杂的模型训练不当,我们知道的,模型的泛化能力会显著下降。
2、深度学习比一般意义的机器学习模型要复杂,不仅表现在上一点的模型本身(指的是layers和parameters),也表现在不同的工作原理上。深度学习不再需要人工设计指定的特征,分类的特征是模型自己去学到的,这一点上意味着深度学习需要有更多的data,这又是和一般意义上的机器学习有所区别的。举个例子,同样是识别车辆,Haar-like+Adaboost可能只需要2-3k训练集,但对于深度学习来说,可能需要20-30k的数据集,当然这么多的data本身是和模型相匹配的,但是在一般意义上,不妨认为深度学习需要更多的data(本文不探讨大数据和深度学习(人工智能)的关系,只在一般意义上做出说明)。
综上所述,其实我们已经认识到了深度学习的本质,其实很简单,就是数据和模型,两者之间相辅相成,相互促进。认识到了深度学习的本质和与一般意义上的机器学习的区别,你才能明白调参和训练的技巧和建议对于深度学习而言是多么的重要,毫不夸张的说,直接影响到我们刚刚谈到的模型的泛化能力,而且是根本原因。
从我们准备数据集到训练到理想的模型的过程顺序,我们把其分成如下几个部分分别叙述。
1、Data augmentation(数据增强)。
个人理解数据增强主要是在准备数据集时,由于需要的data较多又得不到满足,则可以通过对颜色(color)、尺度(scale)、裁剪(crop)、翻转(Flip)、添加噪声(Noise)、旋转(Rotation)等等,这样就增加了数据集的数目,解决的是data不足的问题,近几年GAN模型的研究也取得了较大的发展,其主要的出发点就是解决了监督学习data不足的问题,经常可用于虚拟场景的仿真等等,感兴趣的可以深入研究。
2、Pre-processing(数据预处理)。
个人理解的是有了数据之后,难道就一定能很好的利用这些数据吗?如何评价这些数据的好坏?那要对数据进行预处理,预处理的前提是要正确的理解数据。数据之间存在相关性吗?假设你用了data augmentation,那显然数据集之间的相关性是较大的,说直白点,你用了两张一模一样的数据在训练集里,意义何在?所以接下来要讲的数据预处理很重要。常用的方法有:normalization(归一化)、PCA(主成分分析)、Whitening(白化)等。
(1)Normalization。可以这样认为,归一化主要在干这样一件事:把数据从一个一般的分布,变成0均值、单位方差的分布,为什么这么干呢?原因是这么做更容易收敛,这种方法在Caffe框架中普遍使用(mean value或者mean binaryproto 文件)。Batch Normalization(BN)是一个升级版本,作者主要考虑当使用了饱和的激活函数时,例如sigmoid函数变成0均值、单位方差则会出现在该函数中间近似线性的那一段,这是非常糟糕的,中间线性的部分的拟合能力最差,因此降低了模型的表达capacity,所以BN应运而生,实验表明,其效果sigmoid函数比Relu函数要好。
(2)PCA。研究如何以最少的信息丢失将众多原有的变量信息浓缩到少数几个维度上,即所谓的主成分。首先计算出协方差矩阵,然后求出协方差矩阵的特征向量,并用其对原特征进行线性变换,实现降维。
(3)Whitening。去除特征向量中各个特征之间的相关性,同时保证每个特征的方差一致。 设特征向量 X = (X1,X2,X3),对于向量 X,可以计算出相应的协方差矩阵(根据已有数据集来估计)。我们希望协方差矩阵是一个对角矩阵,因为这意味着 X 的每个元素之间都是互不关联的,但是我们的数据并不具备这样的性质。为了解耦数据,我们需要对原始特征向量执行一个变换,从而使得变换后的向量 Y 的各个特征之间相关性为0。设 Σ 是 X 的协方差矩阵,有:ΣΦ=ΦΛ, 那么 Λ 中的每个元素都是协方差矩阵的特征值,Φ 的每个列向量是相应的特征向量。如果对特征向量做变换:Y = XΦ = X(Φ1,Φ2,Φ3),此时根据向量 Y 计算出来的协方差矩阵是一个对角矩阵。对角矩阵 Λ 的特征值就是 Y 的每个元素的方差,可以全部相同,也可能不相同,如果对变换后的特征向量的某些维度进行缩放,使得 Λ 的每个元素都相等,那么整个过程就是 whitening。
3、Initialization(初始化)。
当前两步完成之后,可以考虑模型参数的初始化方式了。此处举出实例,Caffe中的参数初始化方式有7种方法,分别为:constant、gaussian、positive_unitball、uniform、xavier、msra和bilinear。用的较多的是xavier用在权重初始化上,constant用在偏置初始化上。
4、Activation Functions(激活函数)。
深度学习之所以具有丰富的表达能力,非常关键的一点是激活函数,这就相当于一系列叠加在一起的非线性处理单元,可以想象出这一系列叠加的非线性处理单元原则上可以逼近任意函数(这指的是从输入到输出效果)。几种常用的激活函数:sigmoid、tanh和Relu,但是我们又介绍过之前广泛使用的sigmoid和tanh等饱和激活函数,使用它们在很深网络模型中的训练效果往往很不好,因为存在梯度消失的问题,例如下图中是一个sigmoid函数的例子,由于神经网络在反向传播时,需要乘以激活函数的一阶导数,这样逐层往前传,可想0.930=0.042,这就产生了两个极端,出现了如下图所示的梯度消失区,一旦梯度都已经很小了,还怎么学习?我们在Caffe中常用Relu函数有效地避免这一问题。

图1:sigmoid函数
5、During training(训练过程中)。
在训练过程中,要掌握学习率的变化策略,一般而言Caffe定义学习率在超参数配置文件中(solver.prototxt),并选择了学习速率的衰减策略(学习速率都是开始的时候大,然后之后变小,如何变,怎么变,我们将其称为策略,所以在论文中一般都会谈到这一问题),更为重要的是,可以在网络层定义中指定lr_mult选择某一层的学习率,该技巧也可为之后的调参做准备。另外一点非常重要的是fine-tune,微调的用处通常情况下就是你选择了一个较为深的model,也就是较为复杂的model,你并不需要把所有的layers都重新训练,而只是训练了其中的some layers,此时我们完全可以站在巨人的肩膀上(利用预训练模型的weights初始化),可以省去很多工作,更为重要的是,加上合适的调参还会提高模型的泛化能力(因为预训练的模型往往还未收敛)。
具体来说,存在以下几种情形:
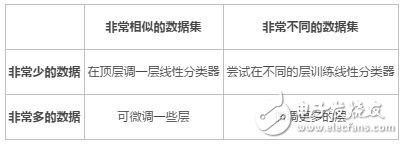
注意微调的时候,在Caffe中操作需要改变微调的那些层的名字(同时根据自己的需要改变layer参数,例如图片的通道、全连接层输出的类别数目等)。
6、Regularizations(正则化)。
正则化也称为Weight-decay(限制权值)。正则化应该讲是一种避免over-fitting的有效方法,这里我们插入一段对over-fitting的分析,就我的认识而言,从事机器学习的工程师们经常会遇到很多问题,很多bug,但是可以这样说over-fitting是所有工程师都必须面对的一个问题,其具有很强的通用性,这是由于方法本身所决定的。既然大家都会遇到这个问题,又该如何解决呢?回头看,我们说过深度学习的本质就是数据和模型,那解决过拟合的根本途径也必须从这两个方向出发,那什么是过拟合呢?形象一点说就是你认为你的model在训练集上已经表现很好了,可是当你把它使用在验证集上的时候,效果则很差,进一步说就是数据集太少或者模型太复杂,两者显然不匹配。现在我们开始从这两个方向分析,解决方法两个:增加数据集和减小模型的复杂度(限制网络的capacity)。此处正则化就是从减小模型的复杂度出发的一项技术,其本质就是控制模型学习的特征数目,使其最小化,从而防止在训练过程中引入训练集的抽样误差,正则化包括L2正则化和L1正则化。
7、Dropout。
Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,如下图所示。对于随机梯度下降来说,由于是随机丢弃,因此每一个mini-batch都在训练不同的网络(对于一个有N个节点的神经网络,采用dropout后,可以认为其是2n个模型的集合),同时每个网络只见过一个训练数据(每次都是随机的新网络),从而将这些多个模型组合起来,以每个模型的平均输出作为结果,caffe中也定义了Dropout层。
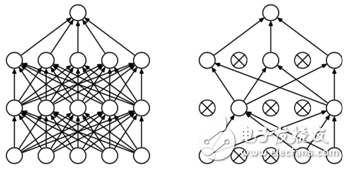
图2 Dropout示例
8、Insights from Figures。
如果说通过上面的方法,你都做了,还是存在问题,那就需要仔细的检查了,检查的方法有很多,其中最为形象生动的,也就是这里要说的就是画图,从图中进行推断。我们知道Caffe也给我们提供了很多画图的tools(称其为可视化),这对写论文、科研分析还是挺好的。言归正传,下面从网上找到几张图片,这些图片都可以从log中通过tools画出,让我们来看一看。
图3表示的是不同学习率下的loss变化曲线,很明显图中的四条曲线随着迭代次数的增加表现出不同的性能,黄色的曲线随着迭代次数的增加,loss先减少而后剧烈增加,往往引发loss等于Nan,这是由于选择的学习率太大的缘故(ps:本人亲测,有几次我在修改一些模型时,开始的loss就很大,然后选择了较大的学习率,一下子就Nan了);蓝色的曲线随着迭代次数的增加,loss的减少速率很慢很慢,而且设置的最大迭代次数已经很大,但网络并没有收敛,这说明选择的学习率太小了;绿色的曲线随着迭代次数的增加,loss的很快减少,并且网络收敛在一个loss较高的地方居高不下,这说明选择的学习率有点大了,已达到局部最优,可观察在网络loss不降时降低学习率;红色的曲线随着迭代的次数的增加,loss缓慢下降,曲线相对平滑,最终收敛在loss很低的水平上,说明选择的学习率较好。当然图中是理想的曲线,只能说明变化趋势,实际情况下曲线是有波动的,有些毛刺感(ps:大量的实践证明可以接受的就是局部最优和全局最优了,也就是红色和绿色曲线代表的过程,当然大多数同志们遇到的都是局部最优,此时我们考虑在局部最优的基础上减小学习率继续训练,两者的区别就是局部最优会保持在一个较高的loss上,当然怎么衡量loss高低没有标准,所以局部最优不代表训练结果就差,局部最优的结果也可以媲美全局最优,因为我们根本不知道全局最优在哪个地方)。
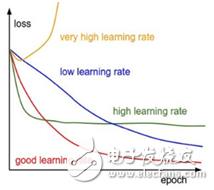
图3:学习率与loss的关系曲线
图4表示的是不同迭代次数的loss变化曲线,从图中可以看到随着迭代次数的增加,loss的变化趋势是减小的,注意图中标注出的“宽度”,如果曲线的宽度太大了,则说明有可能你选择的batch太小了,而其实batch的选择在深度学习中也不是随便来的,太大了不好,太小了也不好,太大了会有显存溢出的错误,太小了有可能某个label很难被学到,这往往导致模型不收敛,或者出现loss为Nan等错误。这个时候可以用accum_batch_size来解决由于硬件不足不能选择较大batch的问题。

图4:迭代次数与loss的关系曲线
图5是模型在训练集和验证集上的精度曲线。红色曲线表示的是模型在训练集上的分类精度,可以看到,还不错,随着迭代次数增加,分类的精度也在增加,并且有收敛的趋势;绿色曲线表示的是模型在验证集上的分类精度,可以看出,与训练集的精度相比,差距很大,说明模型over-fitting了,应该运用上面说到过的解决方法解决。如果图中两者之间没什么大的差距而且精度都很低,应该增加模型的capacity,提升性能。
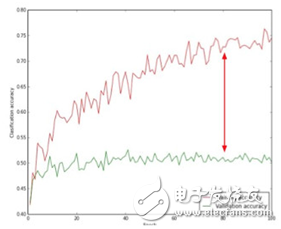
图5:模型在训练集和验证集上的精度曲线
我们都在通往真理的路上。
-
深度学习模型训练过程详解2024-07-01 4600
-
深度学习技术与边缘学习技术的不同之处2023-11-17 1397
-
深度学习框架是什么?深度学习框架有哪些?2023-08-17 4177
-
为什么深度学习是非参数的?2023-05-25 1010
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2146
-
什么是深度学习(Deep Learning)?深度学习的工作原理详解2022-04-01 13661
-
深度学习模型是如何创建的?2021-10-27 2386
-
机器学习和深度学习有什么区别?2021-03-12 9320
-
深度学习的调参经验2019-06-08 2870
-
5分钟内看懂机器学习和深度学习的区别2018-09-13 2135
-
深度学习与数据挖掘的关系2018-07-04 2945
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 4361
全部0条评论

快来发表一下你的评论吧 !
