

一文解析STM32内存管理和堆栈的认知与理解
电子说
描述
本文主要介绍了STM32内存管理和堆栈的认知与理解,首先介绍的是内存管理的实现原理及分配、释放原理,其次介绍了stm32的存储器结构,最后阐述了堆栈的认知与理解,具体的跟随小编一起来了解一下吧。
STM32内存管理详解
内存管理,是指软件运行时对计算机内存资源的分配和使用的技术。其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。内存管理的实现方法有很多种,他们其实最终都是要实现 2 个函数: malloc 和 free; malloc 函数用于内存申请, free 函数用于内存释放。
内存管理的实现原理
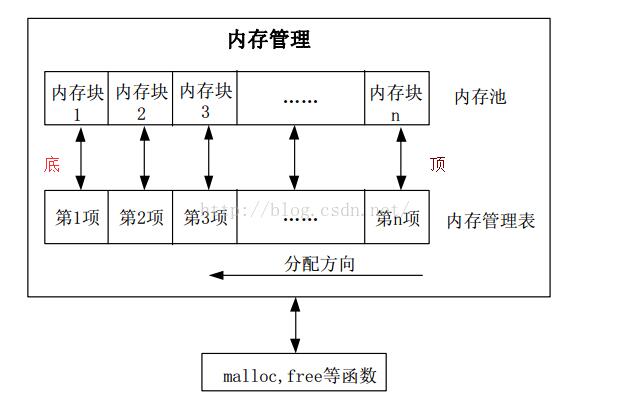
从上图可以看出,分块式内存管理由内存池和内存管理表两部分组成。内存池被等分为 n块,对应的内存管理表,大小也为 n,内存管理表的每一个项对应内存池的一块内存。内存管理表的项值代表的意义为:当该项值为 0 的时候,代表对应的内存块未被占用,当该项值非零的时候,代表该项对应的内存块已经被占用,其数值则代表被连续占用的内存块数。比如某项值为 10,那么说明包括本项对应的内存块在内,总共分配了 10 个内存块给外部的某个指针。内寸分配方向如图所示,是从顶底的分配方向。(即从高位地址到低位地址)即首先从最末端开始找空内存。当内存管理刚初始化的时候,内存表全部清零,表示没有任何内存块被占用。
分配原理
当指针 p 调用 malloc 申请内存的时候,先判断 p 要分配的内存块数( m),然后从第 n 项开始,向下查找,直到找到 m 块连续的空内存块(即对应内存管理表项为 0),然后将这 m 个内存管理表项的值都设置为 m(标记被占用),最后,把最后的这个空内存块的地址返回指针 p,完成一次分配。注意,如果当内存不够的时候(找到最后也没找到连续的 m 块空闲内存),则返回 NULL 给 p,表示分配失败。
释放原理
当 p 申请的内存用完,需要释放的时候,调用 free 函数实现。 free 函数先判断 p 指向的内存地址所对应的内存块,然后找到对应的内存管理表项目,得到 p 所占用的内存块数目 m(内存管理表项目的值就是所分配内存块的数目),将这 m 个内存管理表项目的值都清零,标记释放,完成一次内存释放。
stm32的存储器结构
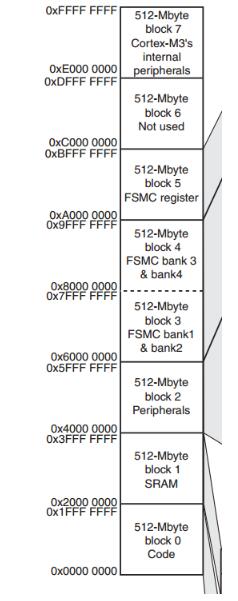
Flash,SRAM寄存器和输入输出端口被组织在同一个4GB的线性地址空间内。可访问的存储器空间被分成8个主要块,每个块为512MB。
FLASH存储下载的程序。
SRAM是存储运行程序中的数据。
所以,只要你不外扩存储器,写完的程序中的所有东西也就会出现在这两个存储器中。
堆栈的认知与理解
1、STM32中的堆栈
这个我产生过混淆,导致了很多逻辑上的混乱。首先要说明的是单片机是一种集成电路芯片,集成CPU、RAM、ROM、多种I/O口和中断系统、定时器/计数器等功能。CPU中包括了各种总线电路,计算电路,逻辑电路,还有各种寄存器。Stm32有通用寄存器R0‐R15 以及一些特殊功能寄存器,其中包括了堆栈指针寄存器。当stm32正常运行程序的时候,来了一个中断,CPU就需要将寄存器中的值压栈到RAM里,然后将数据所在的地址存放在堆栈寄存器中。等中断处理完成退出时,再将数据出栈到之前的寄存器中,这个在C语言里是自动完成的。
2、编程中的堆栈
在编程中很多时候会提到堆栈这个东西,准确的说这个就是RAM中的一个区域。我们先来了解几个说明:
(1) 程序中的所有内容最终只会出现在flash,ram里(不外扩)。
(2) 段的划分,是将类似数据种类存储在一个区域里,方便管理,但正如上面所说,不管什么段的数据,都是最终在flash和ram里面。
C语言上分为栈、堆、bss、data、code段。具体每个段具体是存储什么数据的,直接百度吧。重点分析一下STM32以及在MDK里面段的划分。
MDK下Code,RO-data,RW-data,ZI-data这几个段:
Code是存储程序代码的。
RO-data是存储const常量和指令。
RW-data是存储初始化值不为0的全局变量。
ZI-data是存储未初始化的全局变量或初始化值为0的全局变量。
Flash=Code + RO Data + RW Data;
RAM= RW-data+ZI-data;
这个是MDK编译之后能够得到的每个段的大小,也就能得到占用相应的FLASH和RAM的大小,但是还有两个数据段也会占用RAM,但是是在程序运行的时候,才会占用,那就是堆和栈。在stm32的启动文件.s文件里面,就有堆栈的设置,其实这个堆栈的内存占用就是在上面RAM分配给RW-data+ZI-data之后的地址开始分配的。
堆:是编译器调用动态内存分配的内存区域。
栈:是程序运行的时候局部变量的地方,所以局部变量用数组太大了都有可能造成栈溢出。
堆栈的大小在编译器编译之后是不知道的,只有运行的时候才知道,所以需要注意一点,就是别造成堆栈溢出了。不然就等着hardfault找你吧。
3、OS中的堆栈及其内存管理。
嵌入式系统的堆栈,不管是用什么方法来得到内存,感觉他的方式都和编程中的堆差不多。目前我知道两种获得内存情况:
(1)用庞大的全局变量数组来圈住一块内存,然后将这个内存拿来进行内存管理和分配。这种情况下,堆栈占用的内存就是上面说的:如果没有初始化数组,或者数组的初始化值为0,堆栈就是占用的RAM的ZI-data部分;如果数组初始化值不为0,堆栈就占用的RAM的RW-data部分。这种方式的好处是容易从逻辑上知道数据的来由和去向。
(2)就是把编译器没有用掉的RAM部分拿来做内存分配,也就是除掉RW-data+ZI-data+编译器堆+编译器栈后剩下的RAM内存中的一部分或者全部进行内存管理和分配。这样的情况下就只需要知道内存剩下部分的首地址和内存的尾地址,然后要用多少内存,就用首地址开始挖,做一个链表,把内存获取和释放相关信息链接起来,就能及时的对内存进行管理了。内存管理的算法多种多样,不详说,这样的情况下:OS的内存分配和自身局部变量或者全局变量不冲突,之前我就在这上面纠结了很久,以为函数里面的变量也是从系统的动态内存中得来的。这种方式感觉更加能够明白自己地址的开始和结束。
这两种方法我感觉没有谁更高明,因为只是一个内存的获取方式,高明的在于内存的管理和分配。
-
堆栈内存和堆内存之间的区别2023-08-07 1088
-
任哲UCOS入门教程中内存中存有任务代码和任务堆栈理解不了2019-05-08 1142
-
对堆栈的理解2021-11-08 1237
-
关于stm32内存架构的分析和理解2022-01-20 991
-
STM32内存管理的相关资料推荐2022-02-09 739
-
对单片机堆栈的理解2022-02-21 2134
-
内存管理概述及原理2022-02-23 1233
-
详细解析STM32中的堆栈机制2018-01-15 13205
-
STM32内存管理以及STM32中的堆栈2018-03-29 13268
-
STM32单片机的堆栈深入解析2020-10-30 5259
-
裸机内存管理解析2021-12-01 471
-
STM32的内存管理相关(内存架构,内存管理,map文件分析)2021-12-05 756
-
详解STM32单片机的堆栈2022-02-08 957
-
STM32内存管理以及堆和栈的理解2022-02-11 434
-
堆栈和内存的基本知识2024-08-29 1421
全部0条评论

快来发表一下你的评论吧 !
