

过拟合的概念和用几种用于解决过拟合问题的正则化方法
电子说
描述
在日常工作、学习中,数据科学家最常遇到的问题之一就是过拟合。你是否曾有过这样一个模型,它在训练集上表现优秀,在测试集上却一塌糊涂。你是否也曾有过这样的经历,当你参加建模竞赛时,从跑分上看你的模型明明应该高居榜首,但在赛方公布的成绩榜上,它却名落孙山,远在几百名之后。如果你有过类似经历,那本文就是专为写的——它会告诉你如何避免过拟合来提高模型性能。

在这篇文章中,我们将详细讲述过拟合的概念和用几种用于解决过拟合问题的正则化方法,并辅以Python案例讲解,以进一步巩固这些知识。注意,本文假设读者具备一定的神经网络、Keras实现的经验。
什么是正则化
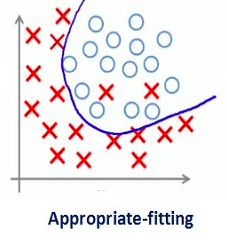
在深入探讨这个话题之前,请看一下这张图片:
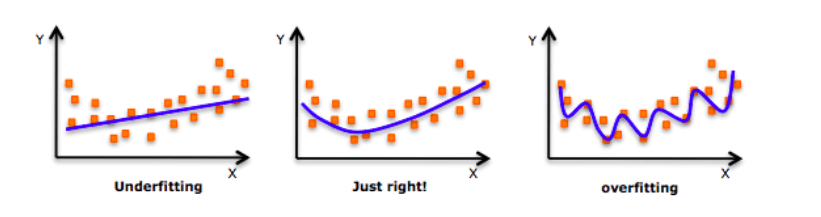
每次谈及过拟合,这张图片就会时不时地被拉出来“鞭尸”。如上图所示,刚开始的时候,模型还不能很好地拟合所有数据点,即无法反映数据分布,这时它是欠拟合的。而随着训练次数增多,它慢慢找出了数据的模式,能在尽可能多地拟合数据点的同时反映数据趋势,这时它是一个性能较好的模型。在这基础上,如果我们继续训练,那模型就会进一步挖掘训练数据中的细节和噪声,为了拟合所有数据点“不择手段”,这时它就过拟合了。
换句话说,从左往右看,模型的复杂度逐渐提高,在训练集上的预测错误逐渐减少,但它在测试集上的错误率却呈现一条下凸曲线。
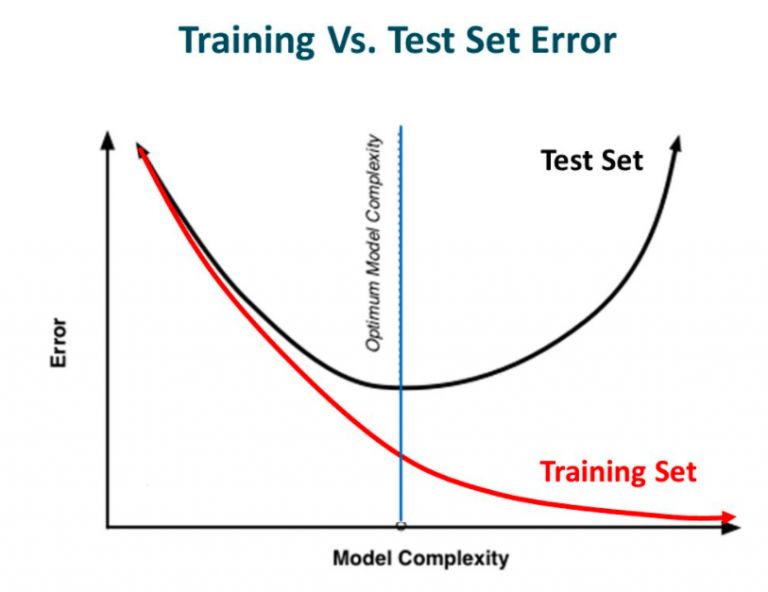
如果你之前构建过神经网络,想必你已经得到了这个教训:网络有多复杂,过拟合就有多容易。为了使模型在拟合数据的同时更具推广性,我们可以用正则化对学习算法做一些细微修改,从而提高模型的整体性能。
正则化和过拟合
过拟合和神经网络的设计密切相关,因此我们先来看一个过拟合的神经网络:
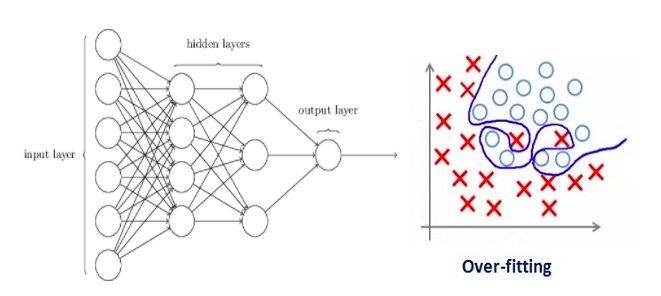
如果你之前阅读过我们的从零学习:从Python和R理解和编码神经网络(完整版),或对神经网络正则化概念有初步了解,你应该知道上图中带箭头的线实际上都带有权重,而神经元是储存输入输出的地方。为了公平起见,也就是为了防止网络在优化方向上过于放飞自我,这里我们还需要加入一个先验——正则化惩罚项,用来惩罚神经元的加权矩阵。
如果我们设的正则化系数很大,导致一些加权矩阵的值几乎为零——那最后我们得到的是一个更简单的线性网络,它很可能是欠拟合的。
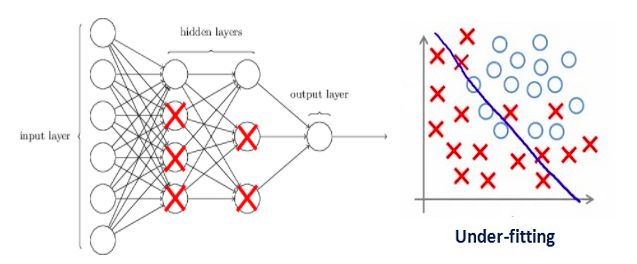
因此这个系数并不是越大越好。我们需要优化这个正则化系数的值,以便获得一个良好拟合的模型,如下图所示。
深度学习中的正则化
L2和L1正则化
L1和L2是最常见的正则化方法,它们的做法是在代价函数后面再加上一个正则化项。
代价函数 = 损失(如二元交叉熵) + 正则化项
由于添加了这个正则化项,各权值被减小了,换句话说,就是神经网络的复杂度降低了,结合“网络有多复杂,过拟合就有多容易”的思想,从理论上来说,这样做等于直接防止过拟合(奥卡姆剃刀法则)。
当然,这个正则化项在L1和L2里是不一样的。
对于L2,它的代价函数可表示为:
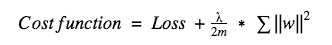
这里λ就是正则化系数,它是一个超参数,可以被优化以获得更好的结果。对上式求导后,权重w前的系数为1−ηλ/m,因为η、λ、m都是正数,1−ηλ/m小于1,w的趋势是减小,所以L2正则化也被称为权重衰减。
而对于L1,它的代价函数可表示为:
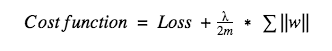
和L2不同,这里我们惩罚的是权重w的绝对值。对上式求导后,我们得到的等式里包含一项-sgn(w),这意味着当w是正数时,w减小趋向于0;当w是负数时,w增大趋向于0。所以L1的思路就是把权重往0靠,从而降低网络复杂度。
因此当我们想要压缩模型时,L1的效果会很好,但如果只是简单防止过拟合,一般情况下还是会用L2。在Keras中,我们可以直接调用regularizers在任意层做正则化。
例:在全连接层使用L2正则化的代码:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01)
注:这里的0.01是正则化系数λ的值,我们可以通过网格搜索对它做进一步优化。
Dropout
Dropout称得上是正则化方法中最有趣的一种,它的效果也很好,所以是深度学习领域常用的方法之一。为了更好地解释它,我们先假设我们的神经网络长这样:
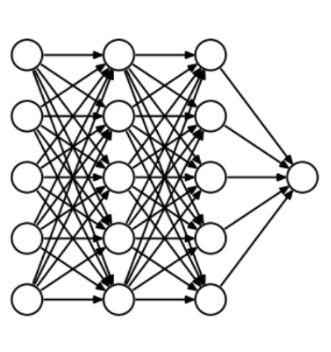
那么Dropout到底drop了什么?我们来看下面这幅图:在每次迭代中,它会随机选择一些神经元,并把它们“满门抄斩”——把神经元连同相应的输入输出一并“删除”。
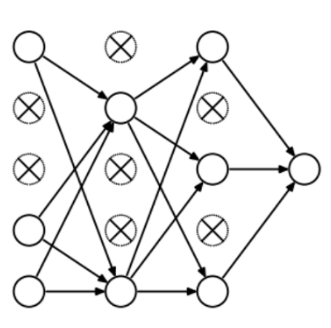
比起L1和L2对代价函数的修改,Dropout更像是训练网络的一种技巧。随着训练进行,神经网络在每一次迭代中都会忽视一些(超参数,常规是一半)隐藏层/输入层的神经元,这就导致不同的输出,其中有的是正确的,有的是错误的。
这个做法有点类似集成学习,它能更多地捕获更多的随机性。集成学习分类器通常比单一分类器效果更好,同样的,因为网络要拟合数据分布,所以Dropout后模型大部分的输出肯定是正确的,而噪声数据影响只占一小部分,不会对最终结果造成太大影响。
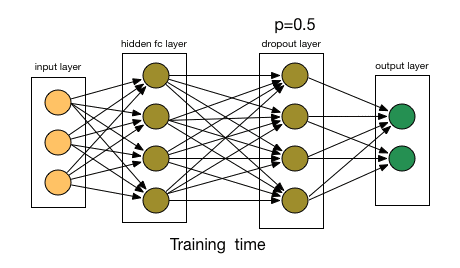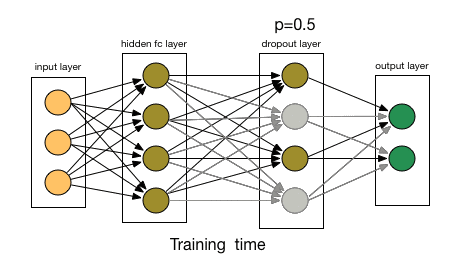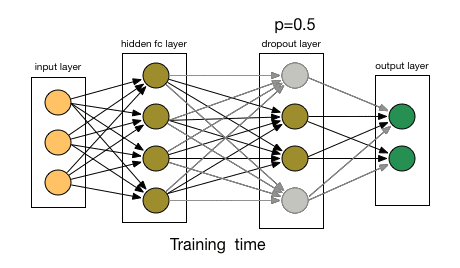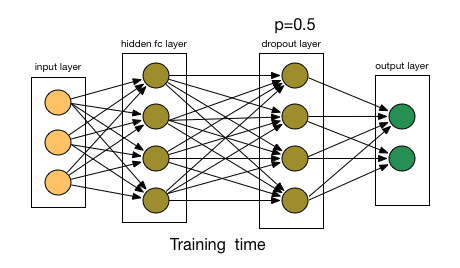
由于这些因素,当我们的神经网络较大且随机性更多时,我们一般用Dropout。
在Keras中,我们可以使用keras core layer实现dropout。下面是它的Python代码:
from keras.layers.core importDropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
注:这里我们把0.25设为Dropout的超参数(每次“删”1/4),我们可以通过网格搜索对它做进一步优化。
数据增强
既然过拟合是模型对数据集中噪声和细节的过度捕捉,那么防止过拟合最简单的方法就是增加训练数据量。但是在机器学习任务中,增加数据量并不是那么容易实现的,因为搜集、标记数据的成本太高了。
假设我们正在处理的一些手写数字图像,为了扩大训练集,我们能采取的方法有——旋转、翻转、缩小/放大、位移、截取、添加随机噪声、添加畸变等。下面是一些处理过的图:
这些方式就是数据增强。从某种意义上来说,机器学习模型的性能是靠数据量堆出来的,因此数据增强可以为模型预测的准确率提供巨大提升。有时为了改进模型,这也是一种必用的技巧。
在Keras中,我们可以使用ImageDataGenerator执行所有这些转换,它提供了一大堆可以用来预处理训练数据的参数列表。以下是实现它的示例代码:
from keras.preprocessing.image importImageDataGenerator
datagen = ImageDataGenerator(horizontal flip=True)
datagen.fit(train)
早停法
这是一种交叉验证策略。训练前,我们从训练集中抽出一部分作为验证集,随着训练的进行,当模型在验证集上的性能越来越差时,我们立即手动停止训练,这种提前停止的方法就是早停法。
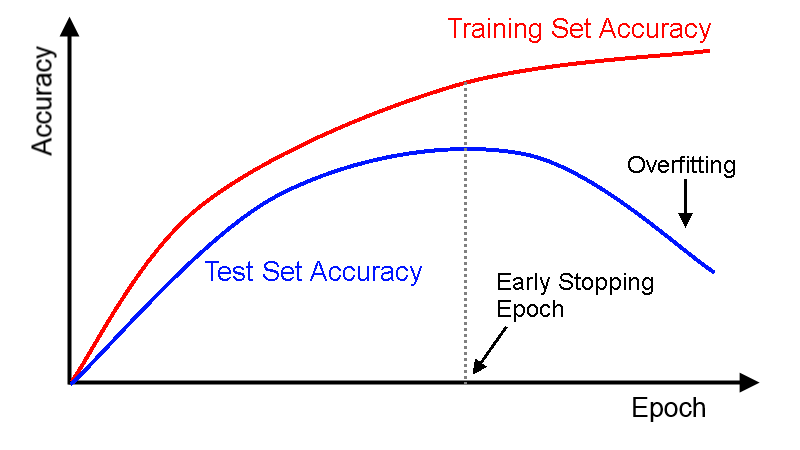
在上图中,我们应该在虚线位置就停止训练,因为在那之后,模型就开始过拟合了。
在Keras中,我们可以调用callbacks函数提前停止训练,以下是它的示例代码:
from keras.callbacks importEarlyStopping
EarlyStopping(monitor='val_err', patience=5)
在这里,monitor指的是需要监控的epoch数量;val_err表示验证错误(validation error)。
patience表示经过5个连续epoch后模型预测结果没有进一步改善。结合上图进行理解,就是在虚线后,模型每训练一个epoch就会有更高的验证错误(更低的验证准确率),因此连续训练5个epoch后,它会提前停止训练。
注:有一种情况是当模型训练5个epoch后,它的验证准确率可能会提高,因此选取超参数时我们要小心。
用keras实例研究MNIST数据
数据集:datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/
学了这么多正则化方法,现在我们就要开始动手实践了。在这个案例中,我们用的是Analytics Vidhya的数字识别数据集。
我们先导几个基本库:
%pylab inline
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
import tensorflow as tf
import keras
# 阻止潜在的随机性
seed = 128
rng = np.random.RandomState(seed)
然后加载数据集:
root_dir = os.path.abspath('/Users/shubhamjain/Downloads/AV/identify the digits/')
data_dir = os.path.join(root_dir, 'data')
sub_dir = os.path.join(root_dir, 'sub')
## 只读取训练文件
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
train.head()
检查一下图像:
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()
# 在numpy数组中存储图像
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
x_train /= 255.0
x_train = x_train.reshape(-1, 784).astype('float32')
y_train = keras.utils.np_utils.to_categorical(train.label.values)
创建验证数据集(7:3):
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = x_train[:split_size], x_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
构建一个带有5个隐藏层的简单神经网络,每层包含500个神经元:
# 导入keras模块
from keras.models importSequential
from keras.layers importDense
# define vars
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10
epochs = 10
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
先跑10个epoch,快速检查一下模型性能:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

L2正则化
from keras import regularizers
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
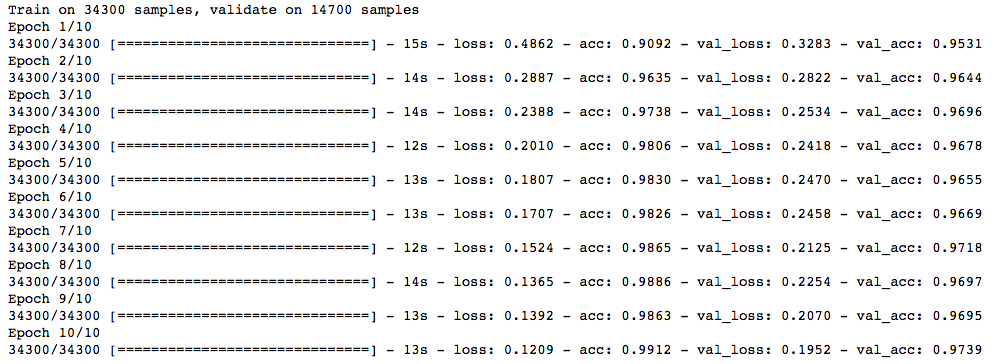
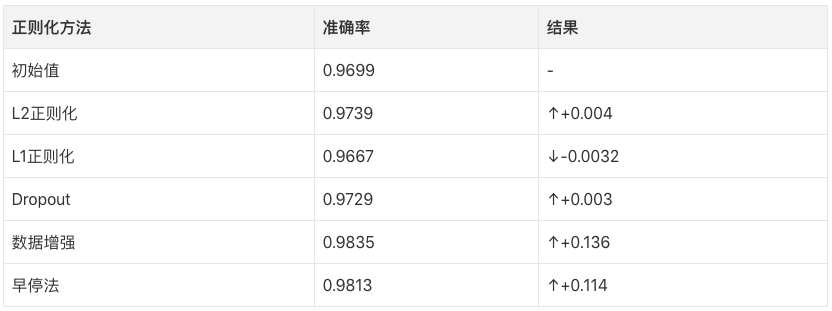
λ等于0.0001,模型预测准确率更高了!
L1正则化
## l1
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu',
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

模型准确率没有任何提高,PASS!
Dropout
## dropout
from keras.layers.core importDropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
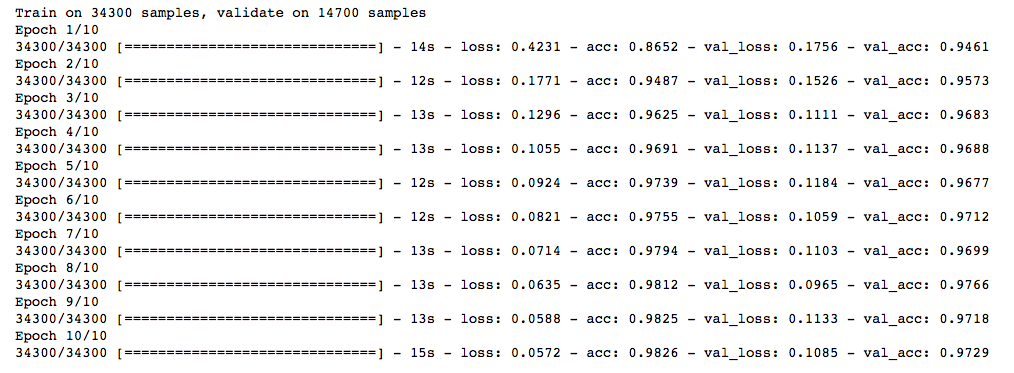
还可以,准确率比一开始提高了一些。
数据增强
from keras.preprocessing.image importImageDataGenerator
datagen = ImageDataGenerator(zca_whitening=True)
# 加载数据
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
x_train = np.stack(temp)
X_train = x_train.reshape(x_train.shape[0], 1, 28, 28)
X_train = X_train.astype('float32')
# 从数据中拟合参数——增加训练数据
datagen.fit(X_train)
在这里,我们用了zca_whitening,它突出了每个数字的轮廓,如下图所示:
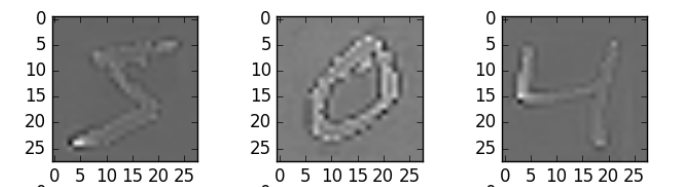
## splitting
y_train = keras.utils.np_utils.to_categorical(train.label.values)
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = X_train[:split_size], X_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
## reshaping
x_train=np.reshape(x_train,(x_train.shape[0],-1))/255
x_test=np.reshape(x_test,(x_test.shape[0],-1))/255
## structure using dropout
from keras.layers.core importDropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

提升非常明显!
早停法
from keras.callbacks importEarlyStopping
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test)
, callbacks = [EarlyStopping(monitor='val_acc', patience=2)])

和上面那些方法相比,早停法只跑了5个epoch就停止了,因为预测准确率没有提高。但是如果我们增加迭代的次数,它应该能给出更好的结果。
-
神经网络中避免过拟合5种方法介绍2020-02-04 25306
-
深层神经网络模型的训练:过拟合优化2020-12-02 3892
-
机器学习基础知识 包括评估问题,理解过拟合、欠拟合以及解决问题的技巧2022-07-12 1773
-
采集正弦曲线过零点附近有波动,怎么用曲线拟合2014-04-09 4548
-
过拟合,欠拟合以及模型的判断2019-04-24 2239
-
模型的过拟合之欠拟合总体解决方案2020-05-15 1794
-
深度学习中过拟合/欠拟合的问题及解决方案2021-01-28 2604
-
曲线拟合的判定方法有哪几种呢2021-11-19 2759
-
基于过拟合神经网络的混沌伪随机序列2009-12-22 864
-
【连载】深度学习笔记4:深度神经网络的正则化2018-08-14 4118
-
欠拟合和过拟合是什么?解决方法总结2020-01-29 33437
-
深度学习中过拟合、欠拟合问题及解决方案2021-01-22 1734
-
正则化方法DropKey: 两行代码高效缓解视觉Transformer过拟合2023-04-17 2213
-
过拟合、泛化和偏差-方差权衡2023-06-12 1128
-
深度学习模型中的过拟合与正则化2024-07-09 2993
全部0条评论

快来发表一下你的评论吧 !
