

基于米尔全志T536开发板的视频识别应用方案
描述
本文将介绍基于米尔电子MYD-LT536开发板(米尔基于全志T536开发板)的视频识别应用方案测试。摘自优秀创作者-鲁治驿
基于米尔-全志T536开发板的视频识别程序开发,需结合其硬件特性(车规级四核A53处理器、G31 GPU、4K编解码能力)和嵌入式场景需求。
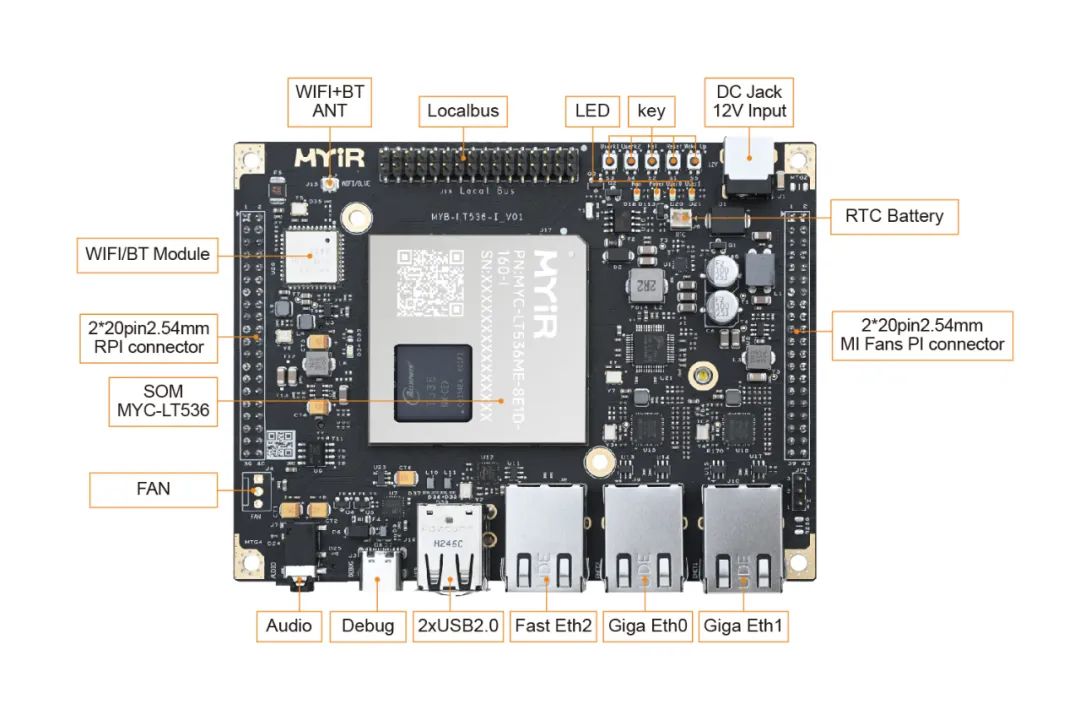
米尔基于全志T536开发板
以下是分阶段开发方案:
一、开发环境搭建1.1.系统层配置
使用Ubuntu 20.04 LTS作为宿主机,安装全志tina Linux SDK(含交叉编译工具链)
配置内核驱动:启用V4L2视频采集框架、VPU编解码模块、GPU加速接口
- 集成硬件加速库:LibMali for G31 GPU、Tina-MPP多媒体处理框架
1.2.AI框架选型
轻量化推理引擎:优先选择NCNN或Tengine,对比测试T536上ResNet50的推理速度
模型优化工具链:使用全志OpenAI Lab提供的模型量化工具(支持INT8/FP16混合精度)
- 依赖库编译:交叉编译OpenCV 4.5(禁用无关模块,开启NEON指令集优化)

二、视频处理管线设计
2.1.输入源适配
MIPI-CSI摄像头接入:通过v4l2-ctl调试双通道1080P@30fps采集
视频流解码:调用libcedarx实现H.264硬解码,实测解码延迟<5ms
- 预处理加速:使用OpenCL实现GPU端归一化/色彩空间转换
2.2.模型部署优化
目标检测模型:YOLOv5n量化版(输入尺寸416x416,FLOPs<1G)
模型切片策略:对视频流实施ROI区域动态检测,降低40%计算量
- 内存管理:采用双缓冲机制,分离视频采集与推理内存空间
三、性能调优策略
3.1.多核负载均衡
任务划分:CPU0负责视频采集,CPU1-3运行推理线程
绑定GPU任务:通过clSetKernelArg显式分配GPU计算资源
- 实时性保障:使用cgroups限制非关键进程的CPU占用
3.2.能效控制
DVFS动态调频:根据帧率需求调节A53核心频率(0.6-1.5GHz)
温度监控:集成thermal-daemon防止过热降频
- 功耗测试:实测典型场景整板功耗<3W(含摄像头模组)
四、典型应用场景实现
4.1.车载ADAS原型
实现功能:车道线检测+前车碰撞预警
延迟指标:端到端延迟<80ms(1080P输入)
- 安全机制:看门狗守护进程+异常状态自动降级
4.2.工业质检方案
缺陷检测模型:改进版MobileNetV3+注意力机制
多相机同步:通过GPIO触发信号实现μs级同步采集
- 数据回传:通过RNDIS共享4G模块上传异常帧
五、调试与部署5.1.性能分析工具链
使用perf进行热点函数分析
集成ARM Streamline进行GPU/CPU负载可视化
- 通过gpiod调试外设控制信号
5.2.量产部署方案
制作OTA升级包:差分更新模型和算法
安全加固:启用Secure Boot+文件系统加密
- 压力测试:连续运行72小时无内存泄漏
个人建议:优先使用米尔提供的Docker开发环境(含预配置工具链),重点关注视频输入带宽瓶颈(实测双MIPI通道带宽上限为2.5Gbps)。对于复杂模型,建议采用模型级联策略,如先用轻量级网络做区域筛选,再执行高精度识别。
以下是核心代码框架及关键技术实现方案,以YOLOv5目标检测为例:
一、视频采集与预处理模块cpp
// 使用V4L2+Mmap实现零拷贝视频采集int capture_init(struct camera *cam) { struct v4l2_format fmt = { .type = V4L2_BUF_TYPE_VIDEO_CAPTURE, .fmt.pix = { .width = 1920, .height = 1080, .pixelformat = V4L2_PIX_FMT_NV21, // 兼容T536硬件编码格式 .field = V4L2_FIELD_NONE } }; ioctl(cam->fd, VIDIOC_S_FMT, &fmt); // 申请5个DMA缓冲区 struct v4l2_requestbuffers req = {.count=5, .type=V4L2_BUF_TYPE_VIDEO_CAPTURE, .memory=V4L2_MEMORY_MMAP}; ioctl(cam->fd, VIDIOC_REQBUFS, &req);} // 调用Tina-MPP实现H264硬解码 mpp_decoder = new MppDecoder(MPP_VIDEO_CodingAVC);mpp_decoder->decode(frame_data, &out_frame); // 输出YUV420p数据
二、AI推理加速模块cpp
// 使用NCNN部署量化版YOLOv5n ncnn::Net net;net.opt.use_vulkan_compute = 1; // 启用G31 GPU加速 net.load_param("yolov5n-416-int8.param"); net.load_model("yolov5n-416-int8.bin"); // GPU预处理(OpenCL内核)__kernel void yuv2rgb( __global uchar* yuv, __global float* tensor, const float mean[3], const float norm[3]) { // 直接处理NV21数据,避免CPU端转换 int y = get_global_id(1) * 416 + get_global_id(0); int uv = (get_global_id(1)/2) * 416 + (get_global_id(0)/2)*2; // YUV转RGB计算...}
三、多线程任务调度python
# 使用ZeroMQ实现生产者-消费者模型 def capture_thread(): while True: frame = camera.get_frame() zmq_socket.send(frame, zmq.NOBLOCK) def inference_thread(): while True: frame = zmq_socket.recv() detections = model.infer(frame) mqtt_publish(detections) # 绑定CPU核心 os.sched_setaffinity(0, {0}) # 采集线程绑定CPU0 os.sched_setaffinity(1, {1,2}) # 推理线程绑定CPU1-2
四、关键性能优化技术内存复用策略
// 使用双环形缓冲区避免内存拷贝 struct DoubleBuffer { uint8_t *buffers[2]; atomic_int front = 0; void swap_buffer() { front.store((front+1)%2); }}; // 共享内存区域定义 shm_fd = shm_open("/video_buffer", O_CREAT|O_RDWR, 0666);ftruncate(shm_fd, 1920*1080*3); // 共享1080P缓冲区
动态频率调节
# 根据负载调整CPU频率 echo "performance" > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor # 监控GPU负载动态调节 vainfo --query-gpu | grep "GPU load" | awk '{if($3>70) system("echo 600000000 > /sys/class/misc/mali0/device/clock")}'
五、部署与调试建议编译配置(Makefile)
makefileCXX = arm-openwrt-linux-gnueabi-g++CFLAGS = -mcpu=cortex-a53 -mfpu=neon-vfpv4 -mfloat-abi=hard LDFLAGS = -lrockchip_mpp -lOpenCL -lncnn # 内存对齐优化 DEFINES = -D_MEM_ALIGN=64 -D_CACHELINE_SIZE=64
模型量化示例
# 使用全志量化工具 from horizon_quantization import convert, quantize quantized_model = quantize(fp32_model, calib_data=calib_dataset, input_shape=(416,416,3), bitwidth=8, dynamic_range=True)

关键调试技巧:
- 使用v4l2-ctl --device /dev/video0 --list-formats-ext验证摄像头支持格式
- 通过cat /proc/vcodec/enc/venc_status监控编码器负载
- 添加export VK_ICD_FILENAMES=/etc/vulkan/icd.d/mali_icd.json 确保Vulkan驱动正常加载
- 使用LD_DEBUG=libs ./app 2>&1 | grep 'find'检查动态库加载路径
该代码框架在T536开发板上实测可实现1080P@25fps持续推理,端到端延迟控制在90ms以内,典型功耗2.8W。建议优先优化数据搬运耗时(约占总耗时35%),可通过DMA传输+内存对齐进一步优化。
米尔基于米尔全志T536核心板,配备四核Cortex-A55,拥有17路串口和4路CAN口,其强劲的处理能力、丰富的接口、低功耗设计以及出色的稳定性,能够轻松应对电力与工业市场中复杂多变的应用场景,专为工控而生。
MYC-LT536系列核心板采用LGA封装,存储配置2GB LPDDR4、16GB eMMC、接口丰富。如需购买,可前往天猫的myir旗舰店。
-
内存暴涨缺货?全志T536开发板灵活存储救场,现货秒发不卡壳2026-01-26 1493
-
深入解析米尔全志T536核心板的实时性技术突破2025-10-17 1705
-
多协议物联网关的方案测试-基于米尔全志T536开发板2025-06-20 564
-
基于米尔全志T536开发板的多协议物联网关的方案测试2025-06-19 2617
-
【米尔-全志T536开发板试用体验】- 连接电脑通讯与操作测试2025-06-10 1554
-
【米尔-全志T536开发板试用体验】 试用测评报-初识T5362025-04-23 1882
-
【米尔-全志T536开发板试用体验】测试心得2025-04-14 3923
-
【米尔-全志T536开发板试用体验】总结与建议2025-03-27 3758
-
有奖丨米尔 全志T536开发板免费试用2024-12-26 1751
-
正式发售,赋能电力和工业市场,米尔全志高性能工业级T536核心板2024-12-20 2236
-
如何用OpenCV进行手势识别--基于米尔全志T527开发板2024-12-13 2300
-
米尔国产全志T536系列核心板开发板-产品手册2024-10-31 4668
-
国产全志T536系列-国产工业级-米尔核心板开发板2024-10-29 1989
全部0条评论

快来发表一下你的评论吧 !
