

Transformer架构中编码器的工作流程
描述
编码器是Transformer体系结构的基本组件。编码器的主要功能是将输入标记转换为上下文表示。与早期独立处理token的模型不同,Transformer编码器根据整个序列捕获每个token的上下文。
其结构组成如下:
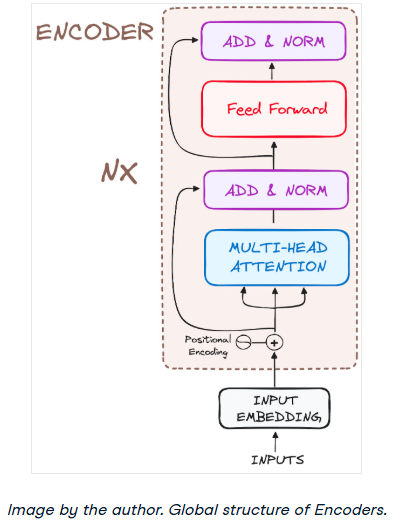
把它的工作流程分解成最基本的步骤:
步骤1 -输入嵌入
嵌入只发生在最底部的编码器中。编码器首先使用嵌入层将输入标记(词或子词)转换为向量。这些嵌入捕获符号的语义并将其转换为数值向量。
所有编码器接收一个向量列表,每个向量的大小为512(固定大小)。在底部的编码器中,这将是单词嵌入,但在其他编码器中,是直接在它们下面的编码器的输出。
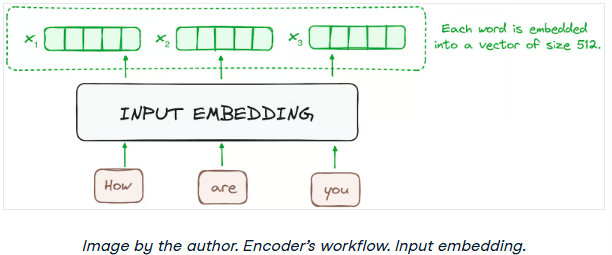
步骤2 -位置编码
由于transformer没有像RNN那样的递归机制,因此它们使用添加到输入嵌入中的位置编码来提供有关序列中每个标记的位置的信息。这使他们能够理解每个单词在句子中的位置。
为了做到这一点,研究人员建议使用各种正弦和余弦函数的组合来创建位置向量,使这种位置编码器能够用于任何长度的句子。在这种方法中,每个维度由波的唯一频率和偏移量表示,其值范围从-1到1,有效地表示每个位置。
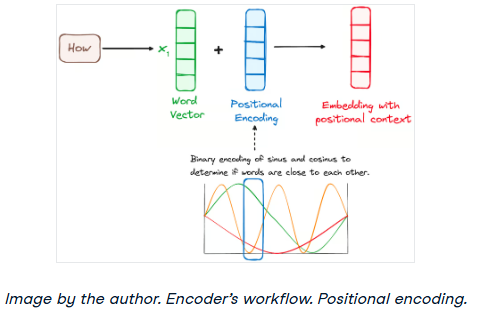
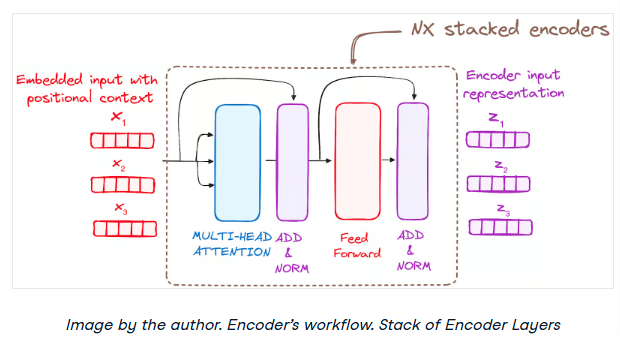
步骤3 -编码器层堆栈
Transformer编码器由一堆相同的层组成(在原始Transformer模型中为6层)。
编码器层用于将所有输入序列转换为连续的抽象表示,该表示封装了从整个序列中学习到的信息。该层包括两个子模块:
Multi-Head attention机制。
一个完全连接的网络。
此外,它结合了每个子层周围的剩余连接,然后进行层规范化。
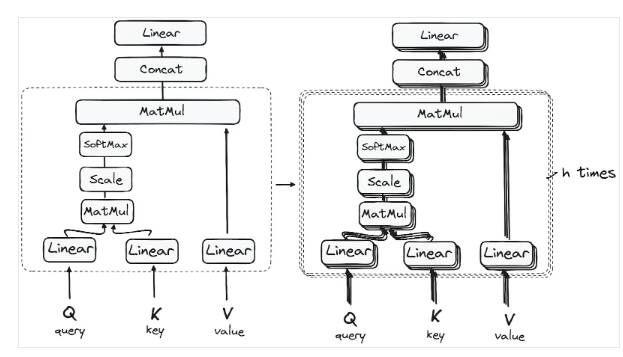
步骤3.1 Multi-HeadSelf-Attention机制
在编码器中,Multi-Headattention利用了一种特殊的attention机制,即Self-Attention。这种方法使模型能够将输入中的每个单词与其他单词关联起来。例如,在给定的示例中,模型可能会学习将单词“are”与“you”联系起来。
这种机制允许编码器在处理每个标记时专注于输入序列的不同部分。它计算attention分数的基础是:
查询是一个向量,表示attention机制中输入序列中的特定单词或标记。
在attention机制中,键也是一个向量,对应于输入序列中的每个单词或标记。
每个值都与一个键相关联,并用于构造注意力层的输出。当一个查询和一个键匹配得很好,这基本上意味着它们有很高的attention分数,相应的值在输出中被强调。
第一个Self-Attention模块使模型能够从整个序列中捕获上下文信息。而不是执行单一的attention功能,查询,键和值是线性投影h次。在查询、键和值的每个投影版本上,attention机制并行执行,产生h维输出值。
详细架构如下:
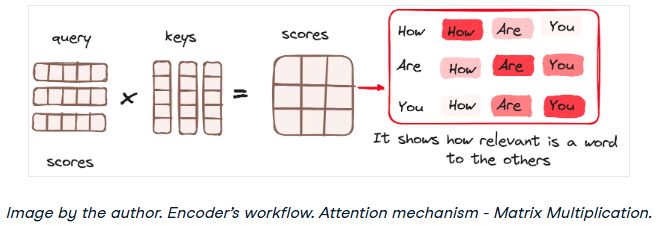
矩阵乘法——查询和键的点积
一旦查询、键和值向量通过线性层,在查询和键之间执行点积矩阵乘法,从而创建分数矩阵。
分数矩阵建立了每个单词对其他单词的强调程度。因此,在同一时间步长内,每个单词相对于其它单词被分配一个分数。分数越高,说明attention越集中。
这个过程有效地将查询映射到相应的键。
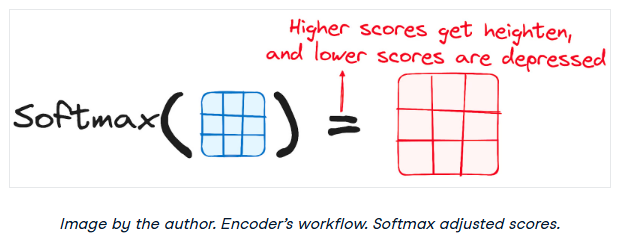
降低attention分数的大小
然后通过将分数除以查询维度和关键向量的平方根来缩小分数。这一步的实现是为了确保更稳定的梯度,因为值的乘法可能导致过大的影响。

将Softmax应用于调整后的分数
然后,对调整后的分数应用softmax函数得到关注权重。这导致概率值范围从0到1。softmax函数强调高分,淡化低分,从而增强了模型有效判断哪些词应该得到更多关注的能力。
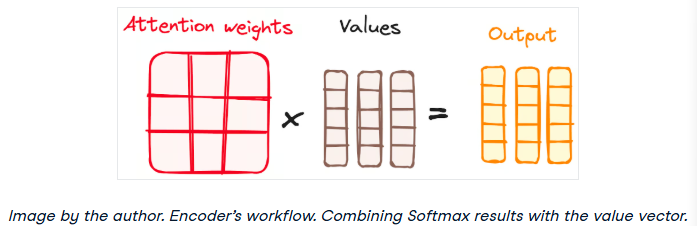
结合Softmax结果与值向量
attention机制的下一步是将softmax函数的权重与值向量相乘,得到一个输出向量。
在这个过程中,只有呈现高softmax分数的单词被保留。最后,这个输出向量被送入一个线性层进行进一步处理。
我们终于得到了attention机制的输出!
所以,你可能想知道为什么它被称为Multi-Head attention?
请记住,在所有进程开始之前,我们会中断查询、键和值h次。这个过程被称为Self-Attention,在每个小阶段中(heads)分别发生。每个head都独立发挥其魔力,召唤出一个输出向量。
这个整体经过最后的线性层,就像一个过滤器,对集体表现进行微调。这里的美妙之处在于每个head的学习多样性,丰富了编码器模型,具有强大的和多方面的理解。
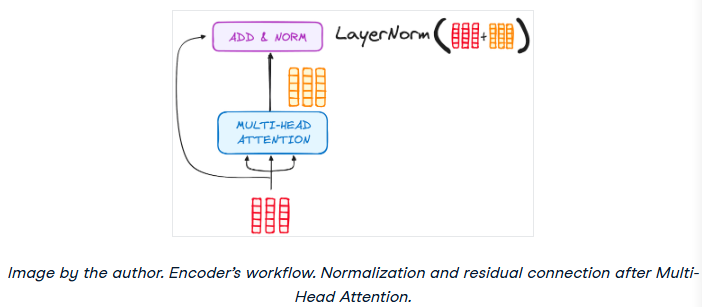
步骤3.2 归一化和残留连接
编码器层中的每个子层后面都有一个规范化步骤。此外,每个子层的输出被添加到它的输入(残余连接),以帮助缓解梯度消失问题,允许更深入的模型。这个过程在前馈神经网络之后也会重复。
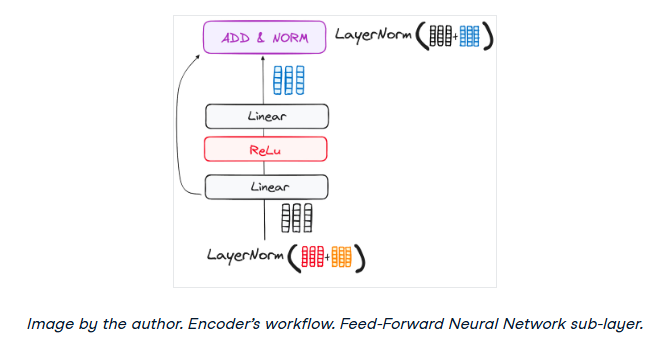
步骤3.3 前馈神经网络
归一化剩余输出通过点向前馈网络导航,这是额外细化的关键阶段。
把这个网络想象成两个线性层,在它们之间有一个ReLU激活,作为一个桥梁。一旦处理完毕,输出就会走上一条熟悉的路径:它循环回去,并与点向前馈网络的输入合并。
这次团聚之后是另一轮归一化,确保一切都调整得很好,并与下一步同步。
步骤4 -编码器的输出
最终编码器层的输出是一组向量,每个向量表示具有丰富上下文理解的输入序列。然后将该输出用作Transformer模型中解码器的输入。
这种编码为解码器铺平了道路,指导它在解码时注意输入中的正确单词。
可以把它想象成建造一座塔,在那里可以堆叠N个编码器层。这个堆栈中的每一层都有机会探索和学习attention的不同方面,就像知识层一样。这不仅使理解多样化,而且可以显著增强Transformer网络的预测能力。
- 相关推荐
- 热点推荐
- 编码器
- 模型
- Transformer
-
磁铁在编码器中的作用与应用2026-03-19 763
-
Transformer架构中解码器的工作流程2025-06-10 1599
-
NX CAD软件:数字化工作流程解决方案(CAD工作流程)2025-02-06 1270
-
磁性直线编码器工作原理2023-06-26 3004
-
神经编码器-解码器模型的历史2023-06-20 2191
-
基于 Transformers 的编码器-解码器模型2023-06-16 2151
-
基于transformer的编码器-解码器模型的工作原理2023-06-11 3395
-
工作流程图怎么用?有哪些绘制工作流程图的软件2020-07-28 7746
-
编码器正交编码工作原理2018-08-02 34007
-
编码器元件工作原理及其应用电路2018-03-04 41825
-
编码器工作原理和选型方法2010-04-21 1990
-
编码器,编码器是什么意思2010-03-08 3495
-
光电编码器,光电编码器的工作原理2010-03-02 9655
-
光电编码器的工作原理2009-01-05 3422
全部0条评论

快来发表一下你的评论吧 !
