

人工智能机器学习之强化学习
人工智能
描述
当前人工智能之机器学习算法主要有7大类:1)监督学习(Supervised Learning),2)无监督学习(Unsupervised Learning),3)半监督学习(Semi-supervised Learning),4)深度学习(Deep Learning),5)强化学习(Reinforcement Learning),6)迁移学习(Transfer Learning),7)其他(Others)。
今天我们重点探讨一下强化学习(RL)。
强化学习(RL),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。
那么什么是强化学习?
强化学习是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大,强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历或能力进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改动方案以适应环境。
通俗的讲,就是当一个小孩学习有迷茫或困惑时,如果老师发现小孩方法或思路正确,就给他(她)正反馈(奖励或鼓励);否则就给他(她)负反馈(教训或惩罚),激励小孩的潜能,强化他(她)自我学习能力,依靠自身的力量来主动学习和不断探索,最终让他(她)找到正确的方法或思路,以适应外部多变的环境。
强化学习有别于传统的机器学习,不能立即得到标记,而只能得到一个反馈(奖或罚),可以说强化学习是一种标记延迟的监督学习。强化学习是从动物学习、参数扰动自适应控制等理论发展而来的。
强化学习原理:
如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势加强。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
若已知R/A梯度信息,则可直接可以使用监督学习算法。因为强化信号R与Agent产生的动作A没有明确的函数形式描述,所以梯度信息R/A无法得到。因此,在强化学习系统中,需要某种随机单元,使用这种随机单元,Agent在可能动作空间中进行搜索并发现正确的动作。
强化学习模型
强化学习模型包括下面几个要素:
1) 规则(policy):规则定义了Agent在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射,常用 π来表示。可以分为两类:
确定性的policy(Deterministic policy): a=π(s)
随机性的policy(Stochastic policy): π(a|s)=P[At=a|St=t]
其中,t是时间点,t=0,1,2,3,……
St∈S,S是环境状态的集合,St代表时刻t的状态,s代表其中某个特定的状态;
At∈A(St),A(St)是在状态St下的actions的集合,At代表时刻t的行为,a代表其中某个特定的行为。
2) 奖励信号(areward signal):Reward是一个标量值,是每个time step中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用R来表示。
3) 值函数(valuefunction):Reward定义的是立即的收益,而value function定义的是长期的收益,它可以看作是累计的reward,常用v来表示。
4) 环境模型(a modelof the environment):整个Agent和Environment交互的过程可以用下图来表示:
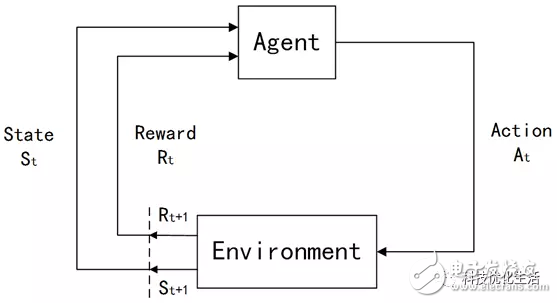
Agent作为学习系统,获取外部环境Environment的当前状态信息St,对环境采取试探行为At,并获取环境反馈的对此动作的评价Rt+1和新的环境状态St+1 。如果Agent的某动作At导致环境Environment的正奖赏(立即报酬),那么Agent以后产生这个动作的趋势便会加强;反之,Agent产生这个动作的趋势将减弱。在强化学习系统的控制行为与环境反馈的状态及评价的反复交互作用中,以学习的方式不断修改从状态到动作的映射策略,达到优化系统性能目的。
-
人工智能和机器学习的前世今生2018-08-27 3501
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2741
-
python人工智能/机器学习基础是什么2020-04-28 3158
-
深度强化学习实战2021-01-10 2795
-
人工智能汽车标定方案2021-09-09 7460
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4517
-
机器学习和人工智能有什么区别?2023-04-12 997
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28662
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4653
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 18439
-
强化学习泡沫之后,人工智能的终极答案是什么?2018-08-09 6827
-
人工智能的强化学习要点2020-05-04 4131
-
复杂应用中运用人工智能核心 强化学习2020-07-27 1201
-
彻底改变算法交易:强化学习的力量2023-06-09 910
-
人工智能强化学习开源分享2023-06-20 743
全部0条评论

快来发表一下你的评论吧 !
