

机器人平台JetPack 3.1使Jetson的低延迟推断性能翻了一番
描述
NVIDIA发布了针对Jetson TX1和TX2的生产Linux软件JetPack 3.1。随着TensorRT 2.1和cuDNN 6.0的升级,JetPack 3.1可为实时应用程序(如视觉导航和运动控制)提供高达2倍的深度学习推理性能,这些应用程序可从批量加速1中获益。改进的特性使Jetson能够部署更强大的智能,实现一代自动化机器,包括传送机器人,远程呈现和视频分析。为了进一步推动机器人技术的发展,NVIDIA最近推出的Isaac Initiative是一个端到端的平台,用于在现场培训和部署高级AI。
图1. Liquid Robotics公司的再生波和太阳能波浪滑翔机能够与Jetson一起自主穿越海洋进行低功耗视觉和人工智能处理。
AI在边缘
当NVIDIA推出Jetson TX2时,事实上的边缘计算平台获得了显着的功能提升。如图1中的Wave Glider平台所示例,网络边缘的远程物联网(IoT)设备经常会遇到降低的网络覆盖率,延迟和带宽。虽然物联网设备通常用作将数据转发到云端的网关,但边缘计算重新考虑了物联网访问安全板载计算资源的可能性。NVIDIA的Jetson嵌入式模块在Jetson TX1上提供1 TFLOP / s的服务器级性能,在功耗低于10W的Jetson TX2上提供双倍的AI性能。
JetPack 3.1
带有Linux的JetPack 3.1对于Tegra(L4T)R28.1是带有长期支持(LTS)的Jetson TX1和TX2的生产软件版本。用于TX1和TX2的L4T板级支持包(BSP)适用于客户的产品化,其共享的Linux内核4.4代码库提供了兼容性和两者之间的无缝移植。从JetPack 3.1开始,开发人员可以在TX1和TX2上访问相同的库,API和工具版本。
表1:Jetson TX1和TX2的JetPack 3.1和L4T BSP中包含的软件包版本。NVIDIA JetPack 3.1 - 软件组件Linux Tegra R28.1Ubuntu 16.04 LTS aarch64CUDA工具包 8.0.82cuDNN 6.0TensorRT 2.1 GAGStreamer 1.8.2VisionWorks 1.6OpenCV4Tegra 2.4.13-17Tegra系统分析器 3.8Tegra图形调试器 2.4Tegra多媒体APIV4L2相机/编解码器API除了从cuDNN 5.1升级到6.0以及维护更新到CUDA 8之外,JetPack 3.1还包括用于构建流媒体应用程序的最新视觉和多媒体API。您可以将JetPack 3.1下载到您的主机上,以便使用最新的BSP和工具对Jetson进行闪存。
使用TensorRT 2.1进行低延迟推理
JetPack 3.1中包含最新版本的TensorRT,因此您可以在Jetson上部署优化的运行时深度学习推断。TensorRT通过网络图优化,内核融合和半精度FP16支持提高推理性能。TensorRT 2.1包括多重配料等关键特性和增强功能,进一步提高了Jetson TX1和TX2的深度学习性能和效率,并降低了延迟。
批量大小1的性能得到显着改善,导致GoogLeNet的延迟降至5毫秒。对于延迟敏感的应用程序,批处理大小1提供最低的延迟,因为每一帧在到达系统时都会被处理(而不是等待批量处理多个帧)。如Jetson TX2上的图2所示,使用TensorRT 2.1实现了GoogLeNet和ResNet图像识别推断的TensorRT 1.0吞吐量的两倍。
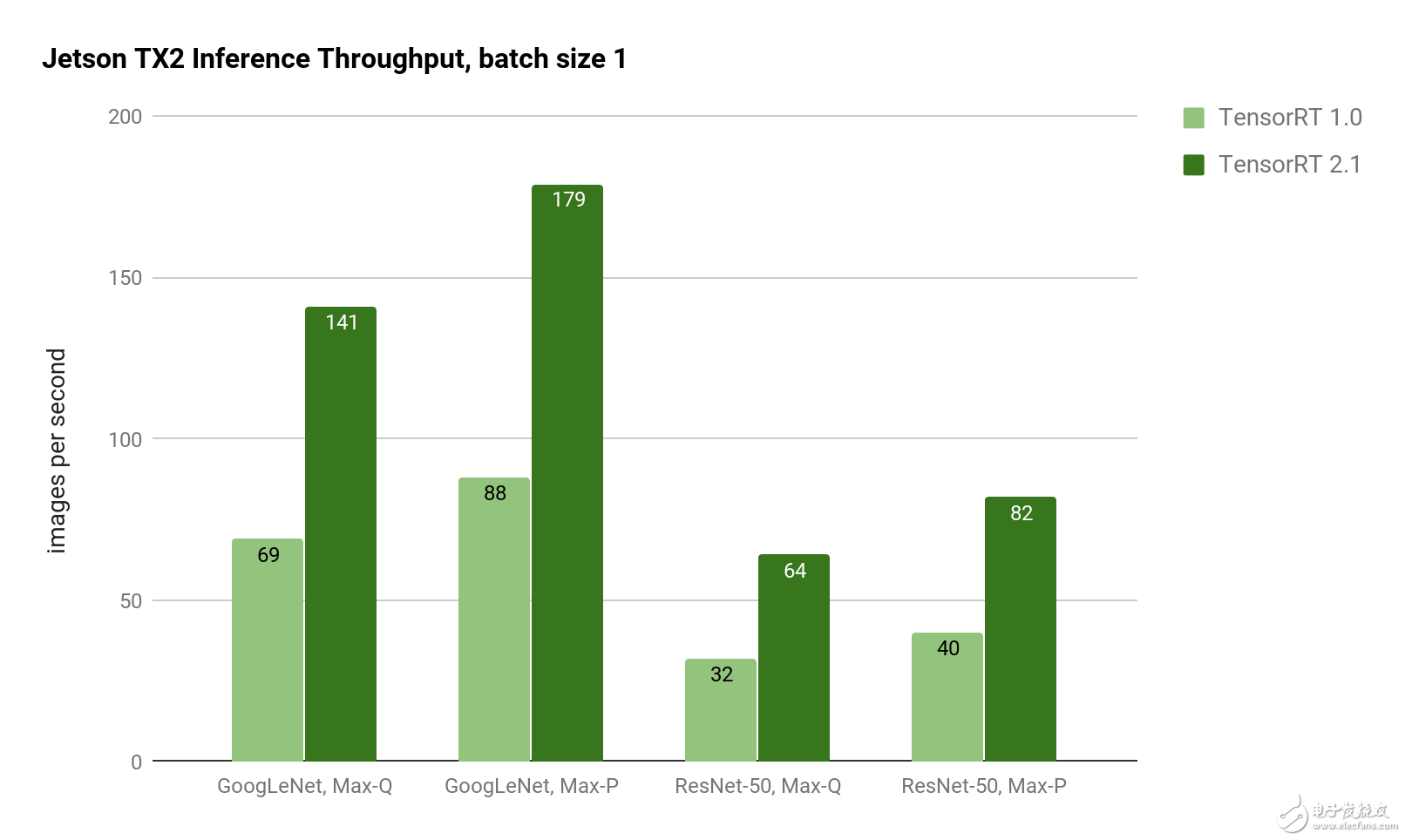 图2:使用Jetson TX2 Max-Q和Max-P功率曲线的GoogLeNet和ResNet-50的推理吞吐量。TensorRT 2.1在GoogleLeNet和ResNet上提供了两倍的推理吞吐量。
图2:使用Jetson TX2 Max-Q和Max-P功率曲线的GoogLeNet和ResNet-50的推理吞吐量。TensorRT 2.1在GoogleLeNet和ResNet上提供了两倍的推理吞吐量。
表2中的等待时间显示批量大小为1时的比例缩减。对于Genson TX2,Jetson TX2在Max-P性能曲线中实现了5ms的延迟,在Max-Q效率曲线中运行时延迟了7ms。ResNet-50在Max-P中有12.2ms的延迟,在Max-Q中有15.6ms的延迟。ResNet通常用于提高超越GoogLeNet的图像分类精度,使用TensorRT 2.1可以使运行时性能提高2倍以上。凭借Jetson TX2的8GB内存容量,即使在像ResNet这样的复杂网络上,也可以实现高达128的大批量生产。
表2:比较TensorRT 1.0和2.1的Jetson TX2深度学习推断延迟测量。(越低越好。)网络潜伏加速TensorRT 1.0TensorRT 2.1GoogLeNet,Max-Q14.5ms7.1ms2.04xGoogLeNet,Max-P11.4ms为5.6ms2.04xResNet-50,Max-Q31.4ms15.6ms2.01xResNet-50,Max-P24.7ms12.2ms2.03x减少的延迟允许深度学习推理方法用于要求接近实时响应的应用中,如避免碰撞和高速无人机和地面车辆上的自主导航。
自定义图层
通过用户插件API支持自定义网络层,TensorRT 2.1能够运行最新的网络和功能,扩展支持包括残余网络(ResNet),递归神经网络(RNN),一次只能看一次(YOLO)和更快-RCNN。自定义图层是在用户定义的C ++插件中实现的,这些插件实现IPlugin了以下代码中的界面。
#include“NvInfer.h”使用命名空间nvinfer1;class MyPlugin:IPlugin{上市:
int getNbOutputs()const;
Dims getOutputDimensions(int index,const Dims * inputs,
int nbInputDims);
void configure(const Dims * inputDims,int nbInputs,
const Dims * outputDims,int nbOutputs,
int maxBatchSize);
int initialize();
void terminate();
size_t getWorkspaceSize(int maxBatchSize)const;
int enqueue(int batchSize,const void * inputs,
void ** outputs,void *工作区,
cudaStream_t流);
size_t getSerializationSize();
void serialize(void * buffer);保护:
虚拟〜MyPlugin(){}};
您可以使用IPlugin类似于上述代码的自定义定义来构建自己的共享对象。在用户enqueue()函数内部,您可以使用CUDA内核实现自定义处理。TensorRT 2.1使用这种技术来实现用于增强对象检测的Faster-RCNN插件。另外,TensorRT为长时间短期记忆(LSTM)单元和门控循环单元(GRU)提供了新的RNN层,以改进时间序列序列的基于记忆的识别。开箱即用地提供这些功能强大的新图层类型可加速在嵌入式边缘应用程序中部署高级深度学习应用程序。
 图3:与Jetson一起提供的用于AI研发的机器人参考平台。
图3:与Jetson一起提供的用于AI研发的机器人参考平台。
NVIDIA Isaac计划
随着人工智能能力的快速提升,NVIDIA推出了艾萨克计划,以推进机器人和人工智能领域的先进技术。Isaac是开发和部署智能系统的端到端机器人平台,包括模拟,自主导航堆栈和嵌入式Jetson以供部署。为开始开发自主AI,Isaac支持图3所示的机器人参考平台。这些Jetson驱动的平台包括无人机,无人地面车辆(UGV),无人地面车辆(USV)和人类辅助机器人(HSR)。参考平台提供了一个Jetson驱动的基础,可以在实地进行实验,并且该计划将随着时间的推移而扩展,以包含新的平台和机器人。
开始部署AI
JetPack 3.1包括cuDNN 6和TensorRT 2.1。它现在可用于Jetson TX1和TX2。凭借对单批次推断的低延迟性能以及对具有自定义层的新网络的支持,双倍的Jetson平台比以往任何时候都更有能力进行边缘计算。要开始开发人工智能,请参阅我们的两天演示系列培训和部署深度学习视觉基元,如图像识别,物体检测和分割。JetPack 3.1大大提高了这些深度视觉原语的性能。
-
 429493174
2018-05-08
0 回复 举报前排前排 收起回复
429493174
2018-05-08
0 回复 举报前排前排 收起回复
-
使用NVIDIA Jetson打造机器人导盲犬2024-11-09 1761
-
使用机器学习和NVIDIA Jetson边缘AI和机器人平台打造机器人导盲犬2024-11-08 1440
-
打造一个异构机器人平台2022-07-27 1913
-
SwarmUS异构机器人平台2022-07-25 529
-
SwarmUS群体机器人平台2022-07-21 1089
-
怎么实现三路超声波避障移动机器人平台的设计?2021-11-10 1476
-
NVIDIA Jetson的相关资料分享2021-11-09 1469
-
机器人平台设计之arduino基础知识分享2021-09-10 2339
-
优傲机器人便是协作机器人领域的上佳之选2020-12-10 2198
-
2018年美国智能音箱普及率几乎翻了一番 其中亚马逊市占率最高2019-01-05 2494
-
自2010年以来 智能手机电池续航能力翻了一番2018-02-06 578
-
《机器人设计与实现》——低成本DIY机器人,一本机器人制作的经典入门书2017-08-01 194215
-
如何使用HRMRP机器人平台构建机器人应用系统2017-02-08 2159
-
【Aworks申请】爬行机器人平台2015-07-07 2793
全部0条评论

快来发表一下你的评论吧 !
