

NVIDIA Jetson TX2将智能提升两倍
描述
NVIDIA推出了Jetson TX2和JetPack 3.0 AI SDK。Jetson是全球领先的低功耗嵌入式平台,可为各地的边缘设备提供服务器级别的AI计算性能。Jetson TX2具有集成的256核NVIDIA Pascal GPU,六核ARMv8 64位CPU复合体和8GB LPDDR4内存以及128位接口。CPU复合体将双核NVIDIA Denver 2与四核ARM Cortex-A57结合在一起。Jetson TX2模块(如图1所示)适合尺寸,重量和功率(SWaP)尺寸为50 x 87毫米,85克和7.5瓦典型能耗的小尺寸,重量和功耗。
物联网(IoT)设备通常用作中继数据的简单网关。他们依靠云连接来执行繁重的工作和数字处理。边缘计算是一种新兴的范例,它使用本地计算来实现数据源的分析。凭借超过TFLOP / s的性能,Jetson TX2非常适合将先进的AI部署到缺乏或昂贵的互联网连接的远程现场位置。Jetson TX2还为需要任务关键型自治功能的智能机器提供接近实时的响应能力和最小的等待时间。
Jetson TX2基于16纳米NVIDIA Tegra“Parker”片上系统(SoC)(图2显示了一个框图)。Jetson TX2的深度学习推断能效比其前身Jetson TX1高两倍,并且性能比Intel Xeon Server CPU高。效率的这种跳跃重新定义了将高级AI从云端扩展到边缘的可能性。
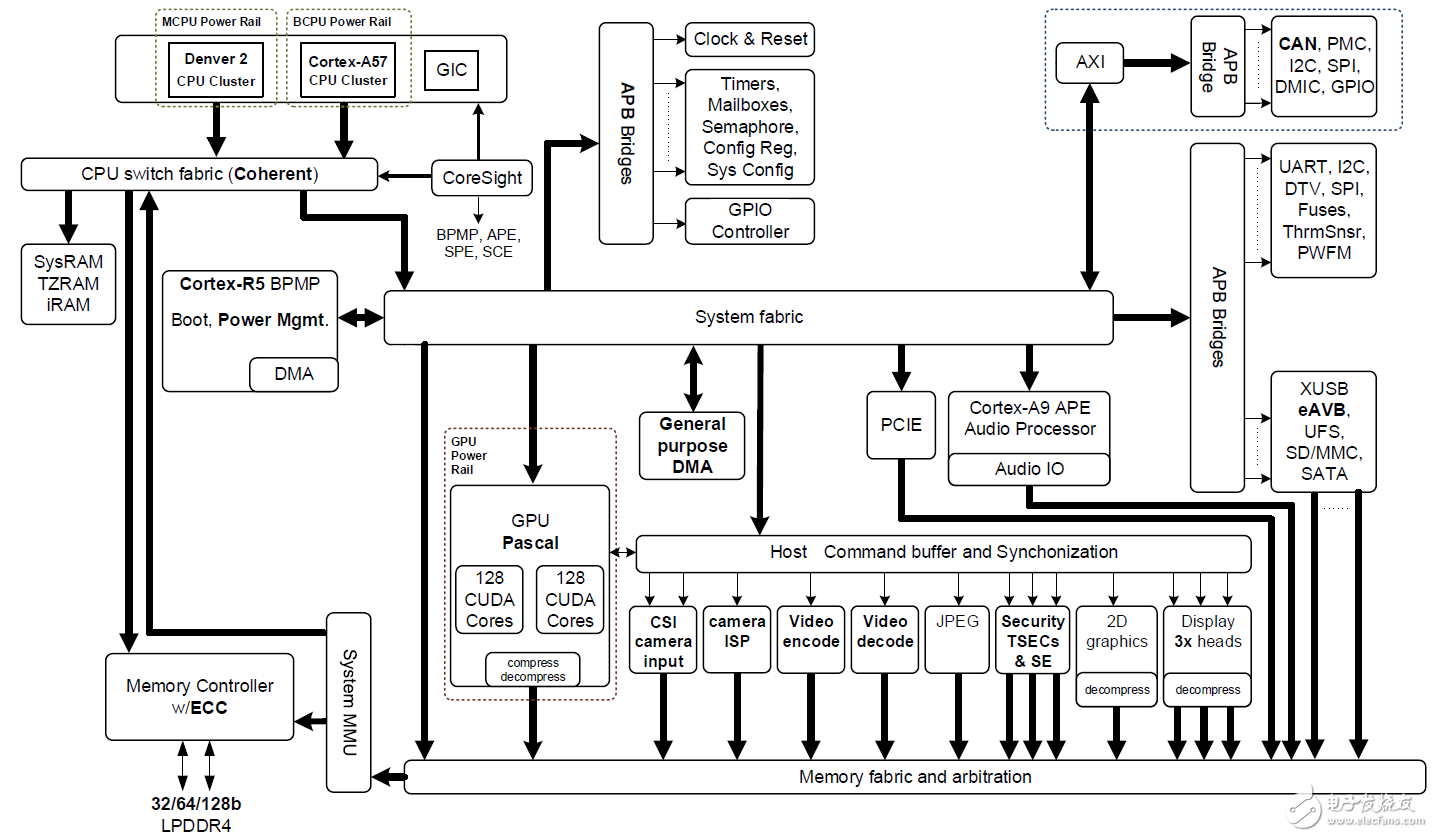 图2:搭载NVIDIA Pascal GPU,NVIDIA Denver 2 + ARM Cortex-A57 CPU集群以及多媒体加速引擎的NVIDIA Jetson TX2 Tegra“Parker”SoC框图(点击图片查看完整分辨率)。
图2:搭载NVIDIA Pascal GPU,NVIDIA Denver 2 + ARM Cortex-A57 CPU集群以及多媒体加速引擎的NVIDIA Jetson TX2 Tegra“Parker”SoC框图(点击图片查看完整分辨率)。
Jetson TX2拥有多个多媒体流引擎,通过卸载传感器采集和分配来保持其Pascal GPU提供数据。这些多媒体引擎包括六个专用MIPI CSI-2摄像机端口,每个通道带宽可提供2.5 Gb / s,双图像服务处理器(ISP)提供1.4 Gigapix / s处理能力,以及支持H.265的4K视频编解码器每秒60帧。
Jetson TX2使用NVIDIA cuDNN和TensorRT库加速前沿深度神经网络(DNN)架构,支持 递归神经网络(RNN), 长期短期记忆网络(LSTM)和在线 强化学习。其双CAN总线控制器使自动驾驶仪集成能够控制使用DNN的机器人和无人机,以感知周围的世界并在动态环境中安全运行。Jetson TX2的软件通过NVIDIA的 JetPack 3.0 和Linux For Tegra(L4T)板级支持包(BSP)提供。
表1比较了Jetson TX2和上一代Jetson TX1的特性。
NVIDIA
Jetson TX1NVIDIA
Jetson TX2中央处理器ARM Cortex-A57(四核)@ 1.73GHzARM Cortex-A57(四核)@ 2GHz +
NVIDIA Denver2(双核)@ 2GHzGPU256核心Maxwell @ 998MHz256核心Pascal @ 1300MHz记忆4GB 64位LPDDR4 @ 1600MHz | 25.6 GB / s8GB 128位LPDDR4 @ 1866Mhz | 59.7 GB / s存储16GB eMMC 5.132GB eMMC 5.1编码器*4Kp30,(2x)1080p604Kp60,(3x)4Kp30,(8x)1080p30解码器*4Kp60,(4x)1080p60(2x)4Kp60相机†12条泳道MIPI CSI-2 | 每通道1.5 Gb / s | 1400万像素/秒ISP12条泳道MIPI CSI-2 | 每通道2.5 Gb /秒| 1400万像素/秒ISP显示2x HDMI 2.0 / DP 1.2 / eDP 1.2 | 2x MIPI DSI无线802.11a / b / g / n / ac 2×2 867Mbps | 蓝牙4.0802.11a / b / g / n / ac 2×2 867Mbps | 蓝牙4.1以太网络10/100/1000 BASE-T以太网USBUSB 3.0 + USB 2.0的PCIeGen 2 | 1×4 + 1×1Gen 2 | 1×4 + 1×1或2×1 + 1×2能够不支持双CAN总线控制器杂项I / OUART,SPI,I2C,I2S,GPIO插座400针Samtec板对板连接器,50x87mm暖流‡-25°C至80°C功率††10W7.5W价钱1K单位299美元1K单位399美元表1:Jetson TX1和Jetson TX2的比较。
*支持的视频编解码器:H.264,H.265,VP8,VP9
†MIPI CSI-2分岔:多达6个2通道或3个4通道相机
‡工作温度范围,TTP最大结温。
††负载下的典型功耗,输入〜5.5-19.6 VDC,Jetson TX2:最大Q值曲线。
性能提高两倍,效率提高两倍
在我 关于JetPack 2.3的文章中,我演示了NVIDIA TensorRT如何提高Jetson TX1深度学习推理性能,效率比桌面级CPU高18倍。TensorRT通过使用图优化,内核融合,半精度浮点计算(FP16)和架构自动调整优化生产网络以显着提高性能 。除了利用Jetson TX2对FP16的硬件支持外,NVIDIA TensorRT还能够批量同时处理多个图像,从而实现更高的性能。
Jetson TX2和JetPack 3.0一起将Jetson平台的性能和效率提升到一个全新的水平,为用户提供两倍于Jetson TX1的性能或两倍于AI应用的性能。这种独特的功能使Jetson TX2成为在边缘需要高效AI的产品和靠近边缘需要高性能的产品的理想选择。Jetson TX2也与Jetson TX1兼容,并为使用Jetson TX1设计的产品提供轻松升级机会。
为了对Jetson TX2和JetPack 3.0的性能进行基准测试,我们将其与服务器级CPU Intel Xeon E5-2690 v4进行比较,并使用GoogLeNet深度图像识别网络测量深度学习推理吞吐量(每秒图像数)。如图3所示,运行功耗低于15W的Jetson TX2的性能优于运行在近200W的CPU,从而在边缘实现了数据中心级别的AI功能。
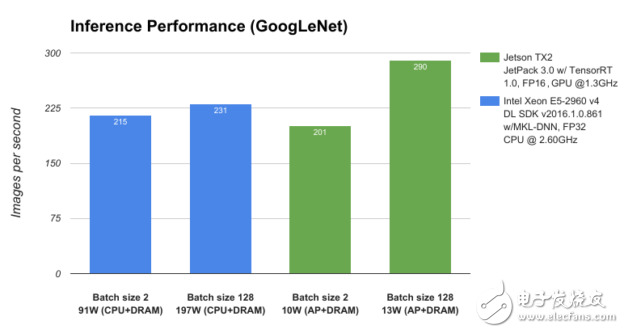 图3:在NVIDIA Jetson TX2和Intel Xeon E5-2960 v4上分析的GoogLeNet网络体系结构的性能。
图3:在NVIDIA Jetson TX2和Intel Xeon E5-2960 v4上分析的GoogLeNet网络体系结构的性能。
Jetson TX2的这种卓越的AI性能和效率来源于全新的Pascal GPU架构和动态能量配置文件(Max-Q和Max-P),JetPack 3.0附带的优化深度学习库以及大容量存储器带宽。
Max-Q和Max-P
Jetson TX2专为7.5W功率下的峰值处理效率而设计。这种性能水平(称为Max-Q)代表功率/吞吐量曲线的峰值。包括电源在内的模块上的每个组件都经过优化,可在此时提供最高的效率。GPU的Max-Q频率为854 MHz,ARM A57 CPU为1.2 GHz。JetPack 3.0中的L4T BSP包含预设平台配置,用于将Jetson TX2设置为Max-Q模式。JetPack 3.0还包含一个新的命令行工具,称为 nvpmodel 在运行时切换配置文件。
虽然动态电压和频率调节(DVFS)允许Jetson TX2的Tegra“Parker”SoC在运行时根据用户负载和功耗调整时钟速度,但Max-Q配置设置了时钟上限以确保应用程序正在运行只在最有效的范围内。表2显示了运行GoogLeNet和AlexNet深度学习基准时Jetson TX2和Jetson TX1的性能和能效。运行在Max-Q模式下的Jetson TX2的性能与Jetson TX1在最大时钟频率下运行的性能相似,但功耗仅为一半,因此能效提高一倍。
尽管大多
-
 潜龙勿用1993_
2019-03-12
0 回复 举报资料心仪已久 十分向往 收起回复
潜龙勿用1993_
2019-03-12
0 回复 举报资料心仪已久 十分向往 收起回复
-
如何在tx2部署模型2024-07-09 2220
-
NVIDIA Jetson TX2为边缘提供双倍的智能2022-04-18 5715
-
Jetson TX2嵌入式开发板有哪些特性以及功能呢2021-12-27 1287
-
怎样在JetSon TX2上移植Vins-Mono与RTAB-Map呢2021-10-19 3802
-
TX2是如何控制风扇转速的2021-09-08 1444
-
如何去搭建一种基于Jetson TX2的全向四轮小车2021-08-26 1822
-
如何在JetSon TX2上移植VINS-Mono与RTAB-Map2021-07-28 1997
-
Jetson tx2 网络无法使用2020-04-11 2423
-
微雪电子NVIDIA Jetson TX2人工智能开发套件介绍2019-11-11 13033
-
NVIDIA Jetson TX2显存的数据手册免费下载2019-11-07 1923
-
Jetson TX2放电电路如何分析2019-02-13 5583
-
Nvidia Jetson TX2系列管脚和功能名称指南2019-01-22 6259
-
NVIDIA Jetson TX2助力安全巡检 大幅提高巡检效率2018-07-17 8871
-
英伟达专为物联网产品发布新品:Jetson TX2移动SoC平台2017-03-08 2847
全部0条评论

快来发表一下你的评论吧 !
