

使用树莓派构建 Slurm 高性能计算集群:分步指南!
描述

在这篇文章中,我将分享我尝试使用树莓派构建Slurm高性能计算集群的经历。一段时间前,我开始使用这个集群作为测试平台,来创建一个更大的、支持GPU计算的高性能计算集群。我获得了高性能计算设置各个组件的实践经验,并了解了它们是如何协同工作的。设置SLURM组件确实是其中的主要部分,经过一番研究,我终于成功搭建了自己的高性能计算集群。由于设置这台机器非常简单,因此它非常适合快速尝试不同的软件包和库,或者调整集群硬件以查看哪种配置效果最佳。
我们的目标是构建一个能够处理多个计算节点的高性能计算集群。从头开始创建这样的系统是一项具有挑战性的任务,需要一定的专业知识。此外,找到一份涵盖配置Slurm集群所有必要步骤的全面教程相当困难,至少根据我的经验是这样。因此,我希望这份分步指南能对你构建自己的高性能计算集群集群有所帮助。
概要
本文从对高性能计算集群的简要介绍开始,并强调了Slurm作为高性能计算集群系统常用的资源管理器和作业调度器的重要性。接下来,我将展示集群网络拓扑结构,讨论必要的先决条件、硬件规格和操作系统设置。之后,我将指导你完成存储节点的设置。然后,通过从源代码构建Slurm,在主节点上安装和配置它,并添加一个额外的计算节点。最后,我将展示几个示例,展示我们构建的Slurm集群的状态以及如何在其中处理作业提交。
特性
最终,你将可以拥有自己的高性能计算集群,需要:
1.Slurm工作负载管理器
2.集中式网络存储
目前,我专注于最小化特性,以防止这篇文章过长。目标是首先设置一个具有基本功能的高性能计算集群,但足够灵活,以便以后进行扩展。
什么是高性能计算集群?
高性能计算集群是由互连的计算机组成的网络,旨在共同解决计算问题并在多个领域高速处理大型数据集。这些集群由多个计算节点组成,每个节点都配备了处理器、内存,并且通常还配备了专门的加速器,如GPU,使研究人员和科学家能够处理计算密集型任务和模拟。
Slurm(简单Linux资源管理工具)是一种开源的高性能计算集群作业调度器和资源管理器。它在高效分配计算资源、管理作业调度以及协调高性能计算集群上的并行计算方面发挥着关键作用。作为Kubernetes集群的替代方案,Slurm专门用于管理科学研究中常见的批处理计算工作负载、模拟和数据分析任务。而Kubernetes则更侧重于容器化应用程序和微服务。
集群网络拓扑
有多种网络拓扑可用于配置高性能计算集群,每种拓扑都针对特定的性能预期和应用需求进行了定制。在我们的场景中,我们专注于通过路由器和交换机在子网(10.0.0.x)内互连三个树莓派。我在路由器上设置了一个DHCP服务器,并保留了IP地址,以便根据每个树莓派的唯一MAC地址为其分配固定的IP地址。然而,这可以通过直接在树莓派上配置静态IP(192.168.0.x)来简化。此外,如果你使用Wi-Fi接入点而不是LAN连接来通过家庭ISP路由器互连树莓派,则可以绕过路由器和以太网交换机的需求。由于此设置旨在用于测试集群,并且不需要快速或甚至稳定的连接,因此这种替代方案是可行的。此外,通过将路由器链接到家庭ISP Wi-Fi接入点并通过以太网共享给设备来提供互联网连接。下图提供了集群网络的视觉表示:
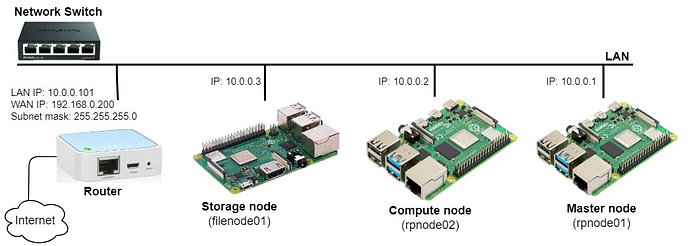
树莓派高性能计算集群网络拓扑
这种网络拓扑提供了可移植性的优势,允许集群轻松连接到不同的接入点。此外,我使用了一个节点专门用于数据管理,作为专用的网络存储服务器。剩下的两个树莓派一个用作主节点和计算节点,另一个用作额外的计算节点。
先决条件
硬件组件
我使用了三个闲置了一段时间的树莓派以及其他一些组件,如下所示:
1.树莓派4 Model B 2GB板(主机名rpnode01)
该设备作为主节点和计算节点。
2.树莓派4 Model B 2GB板(主机名rpnode02)
该设备作为第二个计算节点。
3.树莓派3+ 1GB板(主机名filenode01)
该设备设置为网络存储服务器。
4.USB电源集线器
你需要一个带有多个端口的USB电源充电器,能够同时支持多个树莓派的电力需求(每个树莓派至少2A)。
5.路由器和以太网交换机(可选)
路由器将管理外部连接,而交换机处理内部设备通信。

树莓派集群的照片
操作系统
我使用了Debian bookworm(版本12)OS Lite 64位,它以轻量级著称,这对于像树莓派这样资源有限的系统来说是有益的。预计需要对所有设备进行以下调整:
1.我使用了默认用户pi,并设置了测试密码testpass。然而,这里还有改进的空间,可以利用LDAP或其他认证机制来保持集群中用户和组ID的同步。
2.在节点上启用SSH访问,一种方便的方法是使用SSH密钥共享来访问节点。
3.为CPU和内存启用控制组。通过修改/boot/firmware/cmdline.txt,添加cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory swapaccount=1。更改后重启系统。
4.将以下主机名添加到/etc/hosts:
10.0.0.1 rpnode01 rpnode01.home.local10.0.0.2 rpnode02 rpnode02.home.local10.0.0.3 filenode01 filenode01.home.local
5.如果需要,使用以下命令配置语言和区域设置:
$ sudo raspi-config
6.最后,更新和升级系统包:
$ sudo apt update && sudo apt upgrade
存储节点
在高性能计算集群中,计算节点被设计为无状态的,这意味着它们不保留任何持久数据或状态。相反,所有应用程序软件和用户数据都存储在集中式共享存储上。这种架构提供了几个优势。首先,它通过简化新计算节点的添加而无需在多台机器上复制数据来增强可扩展性。其次,它为用户提供了灵活性,允许他们从集群中的任何计算节点访问其应用程序和数据。第三,将所有数据存储在集中式存储节点上可确保数据完整性和一致性,消除了因在单个计算节点上本地存储数据而可能产生的不一致性担忧。最后,无状态计算节点架构简化了维护任务,如软件更新、硬件更换和故障排除,因为无需转移或备份计算节点上本地存储的数据。
NFS服务器
我在专用节点filenode01上设置了NFS(网络文件系统)服务器,以便拥有网络存储。当我在高性能计算集群的上下文中将计算节点称为“无状态”时,我的意思是计算节点本身不保留任何持久数据。相反,所有用户主目录数据和应用程序软件都驻留在集中式存储节点上。
为此,我使用apt包管理器安装了NFS服务器。这可以通过在终端中运行以下命令来完成:
$ sudo apt install nfs-kernel-server
然后,我通过配置/etc/exports文件来定义我希望通过NFS共享的目录。这是在Unix类操作系统中NFS服务器使用的配置文件。该文件指定了服务器上哪些目录与NFS客户端共享,并定义了这些目录的访问权限。我确保这些文件夹存在,然后使用以下命令添加条目:
$ sudo mkdir -p /home /nfs
$ sudo bash -c "cat >> /etc/exports << EOF/home *(rw,sync,no_root_squash,no_subtree_check)/nfs *(rw,sync,no_root_squash,no_subtree_check)EOF"
在这里,我使用*来允许来自任何节点的访问,并根据需要指定了选项,如rw表示读写访问。编辑exports文件后,通过运行以下命令应用更改:
$ sudo exportfs -ra
如果节点上启用了防火墙,你可能需要打开NFS端口。NFSv4使用TCP和UDP端口2049,而NFSv3使用额外的端口。你可以使用ufw或iptables根据防火墙配置打开这些端口。
我们可以使用showmount来验证NFS共享是否可用。此命令将显示节点上导出的目录列表。
$ sudo showmount -eExport list for filenode01:/home */nfs *
NFS客户端
为了在两个NFS客户端节点(即rpnode01和rpnode02)上启用网络存储访问,我们可以通过调整/etc/fstab文件来包含NFS挂载点。这是一个系统文件,允许在系统启动时自动化挂载文件系统。
在更改此文件之前,请再次确保客户端侧的目录/home和/nfs存在。执行以下命令:
$ sudo mkdir -p /home /nfs
$ sudo bash -c "cat >> /etc/fstab << EOFfilenode01:/home /home nfs defaults 0 0filenode01:/nfs /nfs nfs defaults 0 0EOF"
追加到/etc/fstab的每一行都定义了一个不同的NFS挂载点。它指示系统将主机名为filenode01的NFS服务器上的/home(/nfs)目录挂载到本地的/home(/nfs)目录。如前所述,/home用于用户数据,而/nfs目录用于共享软件栈。重启节点。
为了检查更新的/etc/fstab的正确性,我使用以下命令mount -a。
$ sudo mount -av/nfs : successfully mounted/home : successfully mounted
这会在系统启动时读取/etc/fstab,并挂载尚未挂载的文件系统。
主节点
构建和安装Slurm
我总是更喜欢从源代码编译Slurm,而不是使用预构建的包。这允许定制化,确保访问最新功能和修复,并提供教育价值。从源代码构建Slurm包并使其准备安装的说明与此处所述大致相同,但我做了一些更改,下面将进行解释。
1.先决条件库
在继续配置Slurm之前,请确保已安装以下库或头文件。你可以通过apt包管理器轻松安装它们。
$ sudo apt install libpmix-dev libpam-dev libmariadb-dev \ libmunge-dev libdbus-1-dev munge
2.从源代码构建
让我们从SchedMD的GitHub仓库下载最新版本的Slurm 23.11(在撰写本文时)。我们将为其构建aarch64架构,而不是x86_64。
https://github.com/SchedMD/slurm/tags
$ sudo mkdir /opt/slurm && cd /opt/slurm$ sudo wget https://github.com/SchedMD/slurm/archive/refs/tags/slurm-23-11-6-1.tar.gz$ sudo tar -xf slurm-23-11-6-1.tar.gz
考虑到我们是从头开始构建所有内容,编译Slurm将需要几分钟时间。
$ cd slurm-slurm-23-11-6-1$ sudo ./configure \ --prefix=/opt/slurm/build \ --sysconfdir=/etc/slurm \ --enable-pam \ --with-pam_dir=/lib/aarch64-linux-gnu/security/ \ --without-shared-libslurm \ --with-pmix $ sudo make $ sudo make contrib$ sudo make install
--prefix选项指定了安装编译代码的基础目录。我没有直接安装到/usr,而是将其设置为/opt/slurm/build。原因是在将Slurm安装在额外的计算节点上时,打算利用它来创建可安装的包。
3.构建Debian包
我使用了fpm工具来创建编译代码的Debian包。这需要安装一个额外的包。
$ sudo apt ruby-dev $ sudo gem install fpm
此工具将创建一个包文件slurm-23.11_1.0_arm64.deb。值得一提的是,从Slurm 23.11.0开始,Slurm包含了构建Debian包所需的文件。
$ sudo fpm -s dir -t deb -v 1.0 -n slurm-23.11 --prefix=/usr -C /opt/slurm/build .Created package {:path=>"slurm-23.11_1.0_arm64.deb"}
4. 安装Debian包
接下来,我们通过dpkg命令安装此包:
$ sudo dpkg -i slurm-23.11_1.0_arm64.debPreparing to unpack slurm-23.11_1.0_arm64.deb ...Unpacking slurm-23.11 (1.0) over (1.0) ...Setting up slurm-23.11 (1.0) ...Processing triggers for man-db (2.11.2-2) ...
我们还必须创建slurm系统用户,并使用正确的访问权限初始化所需的目录。确保slurm用户存在,并且其用户ID在集群中同步。请注意,Slurm控制器使用的文件和目录需要由slurm用户可读或可写。此外,日志文件目录/var/log/slurm和状态保存目录/var/spool/slurm必须可写。
在这里,我将slurm用户和组ID固定为151。
$ sudo adduser --system --group -uid 151 slurm
还通过执行以下命令创建了具有预期权限的必要目录:
$ sudo mkdir -p /etc/slurm /var/spool/slurm/ctld /var/spool/slurm/d /var/log/slurm$ sudo chown slurm: /var/spool/slurm/ctld /var/spool/slurm/d /var/log/slurm
Slurm配置
到目前为止,一切进展顺利。到目前为止,我们已经构建并安装了Slurm包。下一步将是配置其各个组件,并将它们作为服务运行。
1.Slurm数据库守护进程
我们将设置Slurm数据库守护进程(slurmdbd)来收集每个作业的详细会计信息,并将所有会计数据存储在数据库中。这首先需要在主节点上创建一个数据库服务器,但理想情况下,它应该位于一个单独的节点上。我选择了MariaDB,这是一个与MySQL兼容的开源数据库。你可以使用以下说明部署数据库服务器:
$ sudo apt install mariadb-server$ sudo mysql -u rootcreate database slurm_acct_db;create user 'slurm'@'localhost';set password for 'slurm'@'localhost' = password('slurmdbpass');grant usage on *.* to 'slurm'@'localhost';grant all privileges on slurm_acct_db.* to 'slurm'@'localhost';flush privileges;exit
之后,我们需要创建/etc/slurm/slurmdbd.conf并添加所需的配置,例如指定认证、数据库服务器主机名、日志记录等。执行以下命令以添加配置文件。
$ sudo bash -c "cat > /etc/slurm/slurmdbd.conf << EOF# Authentication infoAuthType=auth/munge
# slurmDBD infoDbdAddr=localhostDbdHost=localhostSlurmUser=slurmDebugLevel=3LogFile=/var/log/slurm/slurmdbd.logPidFile=/run/slurmdbd.pidPluginDir=/usr/lib/slurm
# Database infoStorageType=accounting_storage/mysqlStorageUser=slurmStoragePass=slurmdbpassStorageLoc=slurm_acct_dbEOF"
此文件描述了Slurm数据库守护进程的配置信息。请注意,它应该只位于执行slurmdbd的计算机上。此外,它必须只能由slurm用户读取。
$ sudo chmod 600 /etc/slurm/slurmdbd.conf$ sudo chown slurm: /etc/slurm/slurmdbd.conf
接下来,我们需要将slurmdbd设置为systemd服务。这可以通过创建/etc/systemd/system/slurmdbd.service来完成。
$ sudo bash -c "cat > /etc/systemd/system/slurmdbd.service << EOF[Unit]Description=Slurm DBD accounting daemonAfter=network.target munge.serviceConditionPathExists=/etc/slurm/slurmdbd.conf
[Service]Type=forkingEnvironmentFile=-/etc/sysconfig/slurmdbdExecStart=/usr/sbin/slurmdbd $SLURMDBD_OPTIONSExecReload=/bin/kill -HUP $MAINPIDPIDFile=/run/slurmdbd.pid
[Install]WantedBy=multi-user.targetEOF"
你现在可以启用并启动slurmdbd.service,如下所示:
$ sudo systemctl enable slurmdbd.service$ sudo systemctl start slurmdbd.service
$ sudo systemctl | grep slurmdbd slurmdbd.service loaded active running Slurm DBD accounting daemon
如果一切顺利,你应该看到slurmdbd服务已启动并正在运行。否则,请检查/var/log/slurm/slurmdbd.log文件或systemd状态。
2.Slurm控制器守护进程
Slurm控制器守护进程(slurmctl)协调Slurm活动,是Slurm的中央管理守护进程。它监控所有其他Slurm守护进程和资源,接受作业,并为这些作业分配资源。我们必须创建一个/etc/slurm/slurm.conf文件。此配置文件定义了Slurm如何与资源交互、管理作业以及与其他组件通信。它包含各种各样的参数,并且必须在集群的每个节点上保持一致。使用以下命令在终端中创建并添加所需的配置:
$ sudo bash -c "cat > /etc/slurm/slurm.conf << EOFClusterName=raspi-hpc-clusterControlMachine=rpnode01SlurmUser=slurmAuthType=auth/mungeStateSaveLocation=/var/spool/slurm/ctldSlurmdSpoolDir=/var/spool/slurm/dSwitchType=switch/noneMpiDefault=pmi2SlurmctldPidFile=/run/slurmctld.pidSlurmdPidFile=/run/slurmd.pidProctrackType=proctrack/cgroupPluginDir=/usr/lib/slurmReturnToService=1TaskPlugin=task/cgroup
# SCHEDULINGSchedulerType=sched/backfillSelectTypeParameters=CR_Core_Memory,CR_CORE_DEFAULT_DIST_BLOCK,CR_ONE_TASK_PER_CORE
# LOGGINGSlurmctldDebug=3SlurmctldLogFile=/var/log/slurm/slurmctld.logSlurmdDebug=3SlurmdLogFile=/var/log/slurm/slurmd.logJobCompType=jobcomp/none
# ACCOUNTINGJobAcctGatherType=jobacct_gather/cgroupAccountingStorageTRES=gres/gpuDebugFlags=CPU_Bind,gresAccountingStorageType=accounting_storage/slurmdbdAccountingStorageHost=localhostAccountingStoragePass=/run/munge/munge.socket.2AccountingStorageUser=slurmAccountingStorageEnforce=limits
# COMPUTE NODESNodeName=rpnode01 CPUs=4 Sockets=1 CoresPerSocket=4 ThreadsPerCore=1 RealMemory=1800 State=idleNodeName=rpnode02 CPUs=4 Sockets=1 CoresPerSocket=4 ThreadsPerCore=1 RealMemory=1800 State=idle
# PARTITIONNSPartitionName=batch Nodes=rpnode[01-02] Default=YES State=UP DefaultTime=1-0000 DefMemPerCPU=200 MaxTime=30-0000 DefCpuPerGPU=1EOF"
再次创建/etc/systemd/system/slurmctld.service以将slurmctl作为systemd守护进程运行。这可以通过运行以下命令来添加:
$ sudo bash -c "cat > /etc/systemd/system/slurmctld.service << EOF[Unit]Description=Slurm controller daemonAfter=network.target munge.serviceConditionPathExists=/etc/slurm/slurm.conf
[Service]Type=forkingEnvironmentFile=-/etc/sysconfig/slurmctldExecStart=/usr/sbin/slurmctld $SLURMCTLD_OPTIONSExecReload=/bin/kill -HUP $MAINPIDPIDFile=/run/slurmctld.pid
[Install]WantedBy=multi-user.targetEOF"
我们现在可以启用并启动slurmctld.service,如下所示:
$ sudo systemctl enable slurmctld.service$ sudo systemctl start slurmctld.service
$ sudo systemctl | grep slurmctldslurmctld.service loaded active running Slurm controller daemon
3.Slurm节点守护进程
如果你想将主节点也用作计算节点,那么你应该设置Slurm的计算节点守护进程(slurmd)。slurmd守护进程必须在每个计算节点上执行。它监控计算节点上运行的所有任务,接受作业,启动任务,并在请求时终止正在运行的任务。此守护进程读取slurmd.conf以及两个额外的文件:cgroup.conf和cgroup_allowed_devices_file.conf。使用以下命令创建所需的两个控制组(cgroup)文件:
$ sudo bash -c "cat > /etc/slurm/cgroup.conf << EOFConstrainCores=yes ConstrainDevices=yesConstrainRAMSpace=yesEOF"
$ sudo bash -c "cat > /etc/slurm/cgroup_allowed_devices_file.conf << EOF/dev/null/dev/urandom/dev/zero/dev/sda*/dev/cpu/*/*/dev/pts/*/dev/nvidia*EOF"
然后,我们必须再次创建systemd.service文件以将slurmd作为服务运行。
$ sudo bash -c "cat > /etc/systemd/system/slurmd.service << EOF[Unit]Description=Slurm node daemonAfter=network.target munge.serviceConditionPathExists=/etc/slurm/slurm.conf
[Service]Type=forkingEnvironmentFile=-/etc/sysconfig/slurmdExecStart=/usr/sbin/slurmd -d /usr/sbin/slurmstepd $SLURMD_OPTIONSExecReload=/bin/kill -HUP $MAINPIDPIDFile=/run/slurmd.pidKillMode=processLimitNOFILE=51200LimitMEMLOCK=infinityLimitSTACK=infinityRestart=on-failureRestartSec=5s
[Install]WantedBy=multi-user.targetEOF"
最后,使用以下命令启用并启动slurmd服务:
$ sudo systemctl enable slurmd.service$ sudo systemctl start slurmd.service
$ sudo systemctl | grep slurmd slurmd.service loaded active running Slurm node daemon
在这一步,我们已经准备就绪,可以使用Slurm的sinfo命令查看有关我们的Slurm节点和分区的信息:
$ sinfoPARTITION AVAIL TIMELIMIT NODES STATE NODELISTbatch* up 30-000 1 idle rpnode01
如果你看到此输出,则表示你已经成功安装并配置了Slurm。干得好!
Slurm 账户记录
Slurm为每个执行的作业和作业步骤收集账户信息。它还支持将账户记录直接写入数据库。出于测试目的,我们在Slurm数据库中定义了一个集群“raspi-hpc-cluster”和一个账户“compute”,如下所示:
$ sudo sacctmgr add cluster raspi-hpc-cluster$ sudo sacctmgr add account compute description="Compute account" Organization=home
$ sudo sacctmgr show account Account Descr Org ---------- -------------------- -------------------- compute Compute account home root default root account root
并将用户pi与常规Slurm账户关联:
$ sudo sacctmgr add user pi account=compute$ sudo sacctmgr modify user pi set GrpTRES=cpu=4,mem=1gb$ sudo sacctmgr show user User Def Acct Admin ---------- ---------- --------- pi compute None root root Administ+
如果一切顺利,我们的单节点Slurm集群现在应该已经准备好提交作业了。让我们首先显示有关可用节点当前状态的信息:
$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELISTbatch* up 30-000 1 idle rpnode[01]
现在,让我们执行一个简单的Slurm srun命令并检查输出。
$ srun hostnamerpnode01
这表明我们的作业作为Slurm作业成功运行,并返回了计算节点的主机名,在这种情况下是rpnode01。
计算节点
将我们的Slurm集群扩展以包含额外的计算节点涉及以下几个关键步骤:
1.安装先决条件库和头文件。
2.从主节点将/etc/munge/munge.key复制到计算节点,将所有者更改为munge用户,并重启munge.service。
3.安装slurm-23.11_1.0_arm64.deb。
4.创建slurm用户和所需的Slurm目录。
5.将slurm.conf、cgroup.conf和cgroup_allowed_devices_file.conf文件复制到/etc/slurm/。
6.启用并启动slurmd.service。
测试
让我们首先使用以下命令将新节点rpnode02的状态更新为idle:
$ scontrol update nodename=rpnode02 state=idle
$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELISTbatch* up 30-000 2 idle rpnode[01-02]
再次在新节点上使用以下命令运行主机名作业:
$ srun -w rpnode02 hostnamerpnode02
如你所见,此作业在第二个计算节点上执行,因此这次返回了主机名rpnode02。
示例
集群信息
Slurm中的分区是将集群划分为逻辑节点集的一种方式,可用于更有效地管理和分配资源。在这里,我们显示有关Slurm中配置的batch分区的详细信息:
$ scontrol show partitionPartitionName=batch AllowGroups=ALL AllowAccounts=ALL AllowQos=ALL AllocNodes=ALL Default=YES QoS=N/A DefaultTime=1-00:00:00 DisableRootJobs=NO ExclusiveUser=NO GraceTime=0 Hidden=NO MaxNodes=UNLIMITED MaxTime=30-00:00:00 MinNodes=0 LLN=NO MaxCPUsPerNode=UNLIMITED MaxCPUsPerSocket=UNLIMITED Nodes=rpnode[01-02] PriorityJobFactor=1 PriorityTier=1 RootOnly=NO ReqResv=NO OverSubscribe=NO OverTimeLimit=NONE PreemptMode=OFF State=UP TotalCPUs=8 TotalNodes=2 SelectTypeParameters=NONE JobDefaults=DefCpuPerGPU=1 DefMemPerCPU=200 MaxMemPerNode=UNLIMITED TRES=cpu=8,mem=3600M,node=2,billing=8
并显示rpnode01的状态:
$ scontrol show nodesNodeName=rpnode01 Arch=aarch64 CoresPerSocket=4 CPUAlloc=0 CPUEfctv=4 CPUTot=4 CPULoad=0.01 AvailableFeatures=(null) ActiveFeatures=(null) Gres=(null) NodeAddr=rpnode01 NodeHostName=rpnode01 Version=23.11.6 OS=Linux 6.6.28+rpt-rpi-v8 #1 SMP PREEMPT Debian 1:6.6.28-1+rpt1 (2024-04-22) RealMemory=1800 AllocMem=0 FreeMem=297 Sockets=1 Boards=1 State=IDLE ThreadsPerCore=1 TmpDisk=0 Weight=1 Owner=N/A MCS_label=N/A Partitions=batch BootTime=2024-05-19T13:58:15 SlurmdStartTime=2024-05-19T14:20:03 LastBusyTime=2024-05-19T14:26:11 ResumeAfterTime=None CfgTRES=cpu=4,mem=1800M,billing=4 AllocTRES= CapWatts=n/a CurrentWatts=0 AveWatts=0 ExtSensorsJoules=n/a ExtSensorsWatts=0 ExtSensorsTemp=n/a
提交作业
让我们在主目录中创建一个简单的Slurm批处理文件:
$ cat > ~/submit.sh << EOF#!/usr/bin/sh
#SBATCH --job-name=testjob#SBATCH --mem=10mb#SBATCH --ntasks=1#SBATCH --cpus-per-task=2#SBATCH --time=0000
srun sleep 10EOF
现在我们可以提交此作业:
$ sbatch submit.sh Submitted batch job 8
你可以在默认批处理队列中查看提交作业的状态:
$ squeue -alSun May 19 14:26:03 2024JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON) 8 batch testjob pi RUNNING 0:03 1:00 1 rpnode01
此作业正在rpnode01上运行,并具有1分钟的时间限制。
总结
如前所述,此高性能计算集群用作测试环境。它目前配备了基本的Slurm和集中存储功能,但具有未来扩展和增强的潜力。我计划撰写后续文章,涵盖与高性能计算集群系统设置相关的其他主题,包括用户会计、磁盘配额、使用环境模块和Conda包管理器设置软件栈、MPI实现以及设置Jupyterhub服务。
随时查看我的GitHub仓库,了解我几年前创建的有关设置高性能计算集群的指南。在该仓库中,我涵盖了所提到的高性能计算集群功能的设置过程。请记住,这些信息有些过时,可能需要进行一些调整才能与当前版本一起使用。
-
解锁树莓派集群:一步步打造你的超级计算阵列!2025-04-25 3250
-
Raspberry Pi树莓派新手指南2024-12-23 735
-
树莓派4B的性能特点及应用2024-08-30 8076
-
高性能计算集群的能耗优化2024-05-25 1589
-
树莓派Python编程指南分享2023-10-07 688
-
等待已久,新品上市 | RevPi Connect 4系列:基于树莓派CM4计算模块的全新工业树莓派2023-08-01 2192
-
树莓派机器人船构建2023-07-10 932
-
树莓派-搭建边缘计算云平台2022-12-03 2711
-
树莓派镜像构建指导、使用方法和特性介绍2022-06-08 4604
-
树莓派MCU来了!2021-10-25 1135
-
树莓派4的计算模组终于上线!2020-10-29 5309
-
树莓派(Raspberry Pi)实战指南.pdf2018-05-07 3606
-
120个树莓派的集群2016-01-20 29739
-
树莓派权威用户指南2014-07-01 117330
全部0条评论

快来发表一下你的评论吧 !
