

调研公司Compass Intelligence出了一份扎“芯”的报告,中国大陆企业无缘前十
电子说
描述
Compass Intelligence对全球100多家AI芯片企业进行了排名,结果显示,前十名中中国大陆没有一家企业上榜,华为(海思)进入第12,寒武纪和地平线分别为第22和24位。
最近,调研公司Compass Intelligence出了一份扎“芯”的报告。这份报告对全球100多家AI芯片企业进行了排名(AI Chipset Index),结果显示:前十名中,没有一家中国大陆企业上榜。不过,有一点欣慰的是,华为(海思)进入到榜单第12名,寒武纪排第22名,地平线排第24,这是中国大陆仅有的三家上榜企业。
排名的依据是什么?
AI Chipset Index的A-list包括提供AI芯片组的软件和硬件公司。AI芯片组包括中央处理器(CPU),图形处理器(GPU),神经网络处理器(NNP),专用集成电路(ASIC),现场可编程门阵列(FPGA),精简指令集计算机(RISC)处理器, 加速器等。有些芯片组针对边缘处理或设备,有些针对云计算中使用的服务器,以及一些针对机器视觉和自动驾驶平台等。
该榜单的评分标准包括:
供应商指标(30分):公司收入和AI收入(或范围);并购可能性;员工或资源;增长潜力;商业化年份
产品和客户指标(30分):产品组合实力;功能实力;创新水平;客户成功案例;市场覆盖率;品牌实力
经济指标(25分):市场宽度;潜在市场;可获得市场;弹性水平;市场份额
其他(共15分):领导力;近期新闻和活动;Google Mentions和AI
根据上述指标,Compass Intelligence给出的AI芯片公司排名(前15名)如下图:
前十五名分别是:
英伟达、英特尔、恩智浦(NXP)、IBM、AMD、谷歌、ARM/软银、苹果、高通、三星电子、华为(海思)、Imagination、新思科技(Synopsys)和联发科
遗憾的是,中国大陆的AI 芯片公司未能进入前十,排名最高的华为(海思)进入第12,寒武纪和地平线分别排第22、24位。
认识一下中外比较突出的AI芯片公司
英伟达:一马当先
英伟达针对自动驾驶汽车领域的全新人工智能超级计算器 Xavier,是一款完整的片上系统 (SoC),集成了Volta的全新 GPU 架构、定制 8 核 CPU 架构以及新的计算机视觉加速器。
该处理器提供 20 TOPS(万亿次运算 / 秒)的高性能,而功耗仅为 20 瓦。单个 Xavier 人工智能处理器包含 70 亿个晶体管,采用最前沿的 16nm FinFET 加工技术进行制造,能够取代目前配置了两个移动 SoC 和两个独立 GPU 的 DRIVE PX 2,而功耗仅仅是它的一小部分。
在今年的GTC大会上,英伟达推出新版 Tesla V100 ,将内存提升2倍,支持更多人工智能的工作负载;此外,英伟达还发布了“世界上最大的GPU”DGX-2,由 16 块 32GB 内存的 Tesla V100 通过 NVSwitch 连接组成,成为首款能够提供每秒两千万亿次浮点运算能力的单点服务器。
同样在GTC 2018上,英伟达宣布打造下一代名为 DRIVE Orin 的自动驾驶芯片,但除了代号外没有透露更多信息。
英特尔:搅局计算机视觉芯片
英特尔子公司 Movidius 在 2017 年推出视觉处理器(VPU,vision processing unit)Myriad X ,是全球第一个配备专用神经网络计算引擎的片上系统芯片(SoC),用于加速设备端的深度学习推理计算。
该神经网络计算引擎是芯片上集成的硬件模块,专为高速、低功耗且不牺牲精确度地运行基于深度学习的神经网络而设计,让设备能够实时地看到、理解和响应周围环境。引入该神经计算引擎之后,Myriad X 架构能够为基于深度学习的神经网络推理提供 1TOPS 的计算性能。
IBM:另辟蹊径,不用冯诺依曼结构
IBM 在 2014 年推出 TrueNorth 芯片,该芯片包括 4096 个核心和 540 万个晶体管,功耗 70mW,模拟了一百万个神经元和 2.56 亿个突触。TrueNorth 芯片模仿人类大脑神经元,不同于通常的冯诺依曼结构。
谷歌:集大成者
谷歌2017 年发布第二代 TPU 芯片,其针对机器学习的训练速度能比现在市场上的图形芯片(GPU)节省一半时间;第二代 TPU 包括了四个芯片,每秒可处理 180 万亿次浮点运算;如果将 64 个 TPU 组合到一起,升级为所谓的 TPU Pods,则可提供大约 11500 万亿次浮点运算能力。
苹果:逐渐自研,功力不必多说
苹果自研的A11 Bionic(仿生)芯片,搭载了64位ARMv8-A架构的6核CPU,同时搭载苹果自研的3核GPU。每秒运算次数最高可达6000亿次,相当于0.6TFlops。
再来看看上榜的三家大陆企业。
华为:第二代AI芯片海思麒麟 980在本季度量产?
2017年9月,华为在德国柏林国际电子消费品展览会(IFA)上正式推出其最新 AI 芯片 “麒麟 970”(Kirin 970)。麒麟 970 采用行业高标准的 TSMC 10nm 工艺,在指甲大小的芯片上,集成了 55 亿个晶体管,功耗降低了 20%,并实现了 1.2Gbps 峰值下载速率。麒麟 970集成 NPU 专用硬件处理单元(寒武纪IP),创新设计了 HiAI 移动计算架构,其 AI 性能密度大幅优于 CPU 和 GPU。相较于四个 Cortex-A73 核心,处理相同 AI 任务,新的异构计算架构拥有约 50 倍能效和 25 倍性能优势。
此外,据业内消息,华为第二代AI芯片海思麒麟 980也将在本季度正式量产,采用台积电 7nm 制程工艺。这款处理器将配置第二代 NPU,在前代的基础上,支持更多的场景应用,NPU 的性能提升 2 倍以上。
寒武纪:最新一代云端 AI 芯片 MLU100问世
昨天,寒武纪重磅发布第三代 IP 产品 Cambricon 1M 和最新一代云端 AI 芯片 MLU100 和板卡产品。MLU100 采用寒武纪最新的 MLUv01 架构和 TSMC 16nm 的先进工艺,平衡模式下的等效理论峰值速度达每秒 128 万亿次定点运算,高性能模式下的等效理论峰值速度更可达每秒 166.4 万亿次定点运算。
MLU100 云端芯片
MLU100 云端芯片不仅可独立完成各种复杂的云端智能任务,更可以与寒武纪 1A/1H/1M 系列终端处理器完美适配,让终端和云端在统一的智能生态基础上协同完成复杂的智能处理任务。
寒武纪去年11月发布了三款智能处理器 IP 产品:面向低功耗场景视觉应用的寒武纪 1H8、拥有更广泛通用性和更高性能的寒武纪 1H16,以及面向智能驾驶领域的寒武纪 1M。
地平线:发布新一代自动驾驶处理器征程 2.0 架构
地平线在去年12月发布了两款AI处理器征程(Journey)和旭日(Sunrise),都属于嵌入式人工智能视觉芯片,分别面向智能驾驶和智能摄像头。这两款芯片,性能可达到 1Tops,实时处理 1080P@30 帧,每帧可同时对 200 个目标进行检测、跟踪、识别,典型功耗只有1.5w。
地平线搭载征程2.0处理器架构的Matrix平台
4月26日,地平线在北京车展上发布了新一代自动驾驶处理器征程 2.0 架构,目前正在研发中,即将流片,而未来在软硬件的进一步协同优化后,征程 2.0 处理器将可实现更强大的自动驾驶性能。
对于此次地平线进入榜单,地平线联合创始人兼算法VP黄畅认为:
人工智能算法的发展会在接下来的十年间引导处理器架构的设计。而继感知和建模之后,预测未来的能力会成为自主机器人的关键技术。这是一个将抽象的算法与具象的电路联合起来激烈碰撞高速迭代的黄金年代。
地平线生逢其时,位列其中定要将那技术乃至人文的边界,推向下一个如今看来难以企及的极限。
再来谈谈问题:核心部件国产化率极低;AI芯片过份地追求完全独立是一个怪圈
新智元从中国某高校微电子所获取的一份集成电路产业报告显示,虽然在国家IC产业政策持续带动下,中国IC产业呈现良好的增长势头,但核心部件处理器和操作系统产业与国外先进国家差距大,保障国家信息安全和产业安全能力不足,CPU和操作系统国产化率极低,难以达到自主可控的要求。
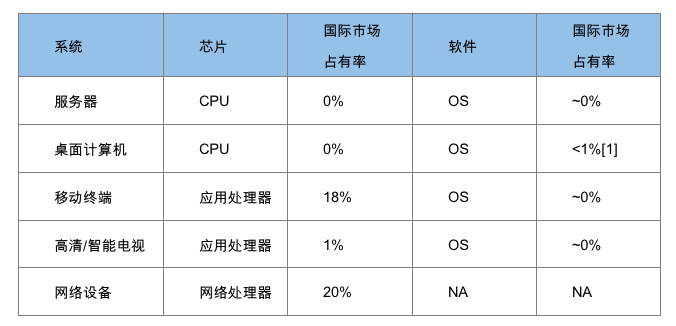
各类软硬件系统中CPU和OS市场占有率
服务器中CPU和操作系统的国际市场占有率为0;
桌面计算机的CPU占有率为0,国产Linux操作系统也小于1%;
移动终端应用处理器国际市场占有率达到18%,但操作系统则为Google垄断;
智能电视应用处理器占有率小于1%,其操作系统也为Google垄断;
网络处理器在华为和中兴等国内企业的努力下,市场占有率达到20%左右。
同时,相关产业基础能力不足,核心技术创新能力不强。
随着系统芯片和IP复用技术的兴起,越来越多的设计企业依赖于IP复用、商业EDA工具和先进工艺,甚至于滥用的倾向,导致研发的芯片同质化严重,缺乏核心竞争力,难以达到世界一流。
到2020年之前,可以预见的是国内先进工艺和世界领先水平相比差距两代,甚至更大是一个大概率事件。
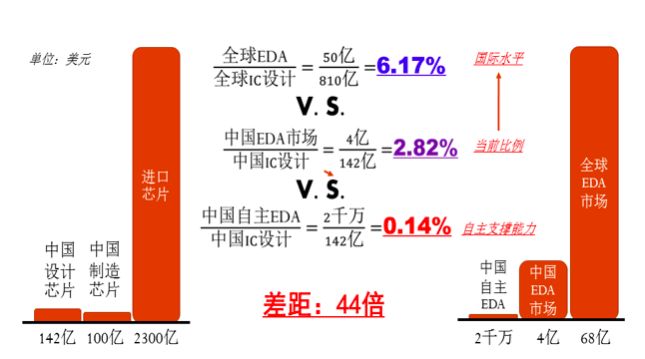
国产EDA的产业能力与设计需求关系
国内EDA(电子设计自动化)市场发展较为迅速,但本土EDA工具的市场严重落后。从国际上看,EDA与IC设计产值的比例大概在6%,而国内EDA/IC设计的比值只有不到3%,本土EDA的比值更低,只有0.14%,相差40多倍。本土EDA工具需要更快更高效的发展,才能有效支撑我国整个集成电路设计的发展。
至于国内AI芯片行业,出现百家争鸣、各自为政的格局,特别是每个初创企业的人工智能芯片都具有自己独特的体系结构和软件开发套件,既无法融入英伟达和谷歌建立的生态圈,又不具备与之抗衡的实力。
中科院自动化所集成中心吴军宁曾发文认为,国产人工智能芯片的发展,一如早年间国产通用处理器和操作系统的发展,过份地追求完全独立、自主可控的怪圈,势必会如众多国产芯片一样逐渐退出历史舞台。
另外,目前大多数国产人工智能处理器都针对于神经网络计算进行加速,而能够提供单芯片解决方案的很少;微控制器领域的发展,ARM 的 Cortex-A 系列和 Cortex-M 系列占据主角,但是新兴的开源指令集架构 RISC-V 也不容小觑,完全值得众多国产芯片厂商关注。
-
中国大陆最具发展潜力的10家IC设计公司2008-05-28 0
-
2022年中国大陆集成电路设计人才需求报告2022-08-17 0
-
Compass Intelligence发布扎“芯”的报告,华为、寒武纪、地平线值得关注!2018-05-09 3628
-
台资企业为何扎堆登陆中国大陆资本市场2018-08-01 7178
-
中国大陆半导体指数报告2019-03-01 11748
-
中国大陆半导体产业有机会挑战美国、南韩和台湾IC设计厂2019-03-16 3350
-
中国大陆成为半导体设备主要投资地区之一 北方华创发展迅速2019-04-24 3541
-
中国大陆乘用车衰退 丽清全力抢攻合资品牌2019-08-19 1673
-
7家传感器企业进入中国大陆半导体TOP25榜单2023-04-10 1554
-
台积电获更多中国大陆AI芯片供应商订单;全球5G专利排名:华为第一 小米进入前十2023-07-10 1243
-
中国大陆制程产能预计将达39%,中芯国际等积极扩产2023-12-14 852
-
索尼手机将退出中国大陆市场?2024-03-08 1358
-
美国苹果公司将增加在中国大陆的投资2024-03-12 1623
-
万年芯解读台积电与ASML报告,中国大陆半导体需求强劲2024-08-05 502
-
中国大陆芯片设备支出领跑全球2024-09-04 664
全部0条评论

快来发表一下你的评论吧 !
