

动态感知+智能决策,一文解读 AI 场景组网下的动态智能选路技术
描述
人工智能(AI),特别是大规模模型训练和推理,正以前所未有的方式重塑数据中心网络。传统的“尽力而为”网络架构,在处理海量、突发的AI数据洪流时捉襟见肘。AI模型对网络性能的严苛要求——高带宽、低延迟、零丢包——迫使网络必须进行一场深刻的智能进化,从被动的基础设施转变为理解业务、感知状态、智能决策的“AI感知网络”。
AI业务诉求:对传统网络架构的挑战
AI集群(如GPU/TPU服务器)间的通信呈现出典型的“大象流”特征,流量总量巨大、并发连接少、单条流带宽极高(可达数百Gbps)。这与传统数据中心中“数量多、带宽小”的“老鼠流”模式截然不同。传统均衡技术失效,逐流ECMP依赖Hash算法在少量大流上极易导致严重负载不均,特定路径拥塞而其他路径闲置。Flowlet 对路径时延差异敏感,配置参数(如Gap值)难以适应动态变化的网络环境,全局信息缺失导致效果打折。逐包ECMP乱序问题严重,严重影响GPU计算效率。AI训练任务(如AllReduce)具有全局同步特性。任何一条关键路径上的拥塞、丢包或高延迟,都会导致整个计算集群“空等”,显著拖慢任务完成时间(Job Completion Time, JCT),直接影响业务效率和资源成本。
RoCE交换机(SONiC-Based)选用的动态智能选路创新方案结合了逐流 ECMP 均衡和基于子流 flowlet 均衡提出动态WCMP(Weighted Cost Multipath)和基于flowlet 的 ALB(Auto Load Balancing),下面将介绍具体相关技术。
网络智能进化:为AI而生的核心技术
网络态势实时感知:高精度测量的基石
- ASIC硬件级统计(百毫秒级): 直接读取交换机芯片寄存器,获取端口/队列的带宽利用率、缓存占用等关键指标,通过SONiC控制面以亚秒级精度汇聚分析。
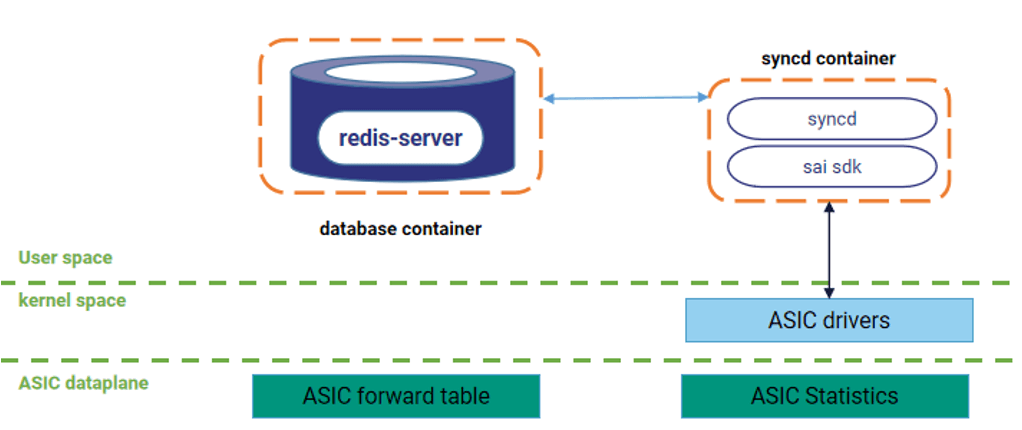
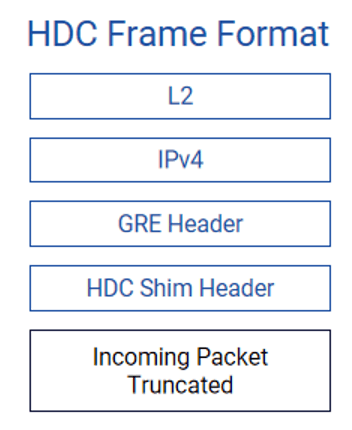
- 带内网络遥测INT(纳秒级): 采用HDC(高延迟捕获)技术。当数据包在交换机内部经历超过设定阈值的延迟时,该数据包的前150字节及关键元数据(入口/出口端口、精确时延)会被复制并发送给分析器(如交换机CPU)。这提供了前所未有的微突发流量和队列拥塞的洞察能力。
动态智能选路技术在星融元交换机上开启 HDC 功能,并将 CPU 作为 HDC 的收集分析器,通过分析 HDC 报文实现高精度测量交换机转发时延,并将时延信息作为路径质量评价因子,提高路径质量评价精度。
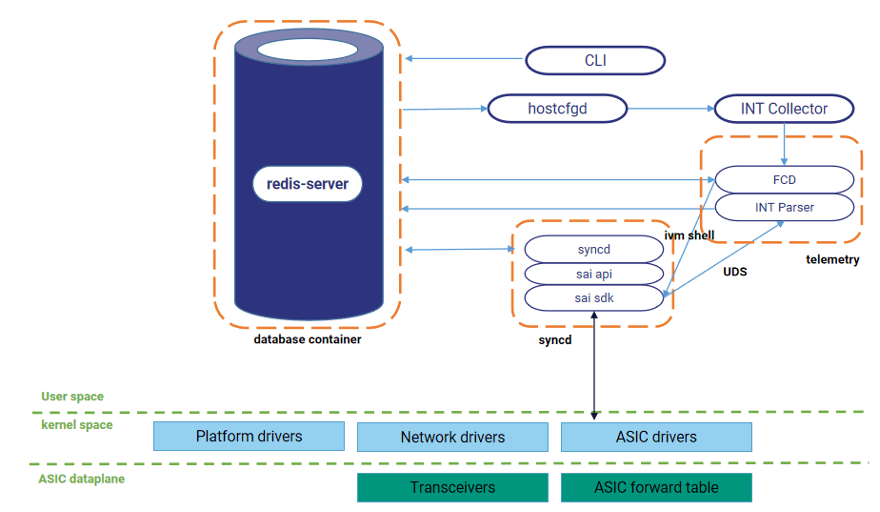
命令行配置 HDC 功能控制INT进程运行,之后通过 socket 连接进行收包循环,将收取到的报文进行解析并将关键信息(出入端口、转发时延等)写入数据库。
全局路径智能评估与同步
感知到的数据需要转化为对整网路径质量的统一认知。
- BGP扩展社区属性传递路径质量: 创新性地扩展BGP协议(数据中心广泛部署的底层路由协议),定义新的Path Bandwidth Extended Community属性。该属性携带一个综合评估路径质量的浮点数值(单位GB/s),通过BGP Update报文在整网扩散。
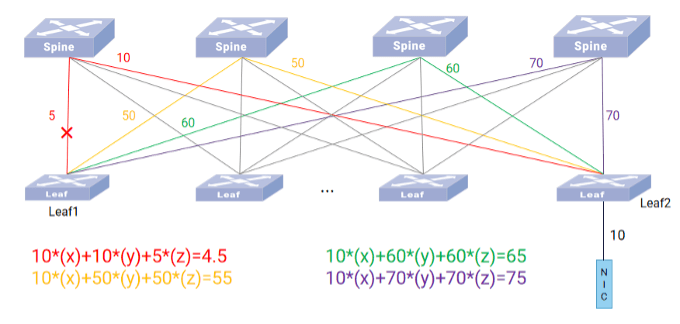
路径质量同步算法逻辑如下图所示:
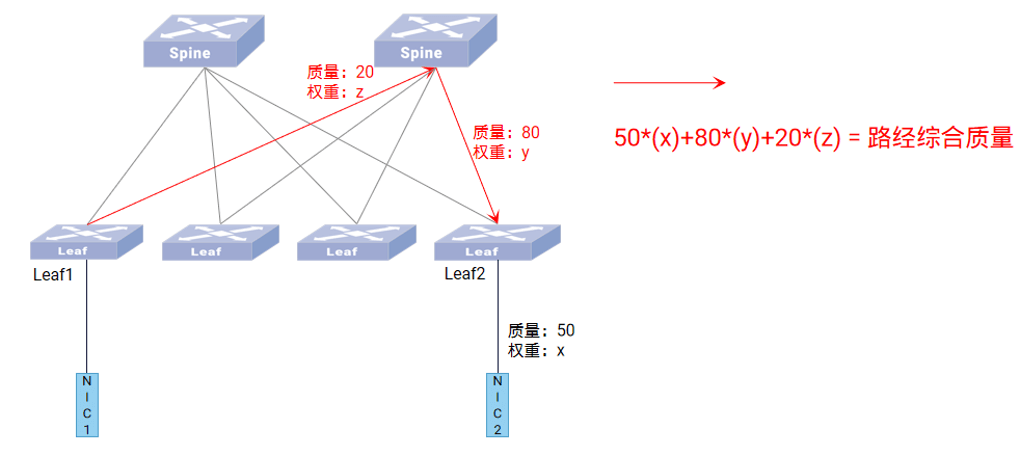
动态智能选路技术将两层 Leaf-Spine 组网中的交换机端口分为了三类:Leaf 上行口、Leaf 下行口和 Spine口,每种类型端口赋予不同的计算系数,且每种端口的计算系数可配。
- 异常路径主动剔除: 设定质量阈值。综合质量过低的路径(如拥塞严重、时延过高)被判定为“异常路径”并暂时剔除,避免其拖累整体性能,待其恢复后重新引入。
智能负载决策与执行:动态WCMP + Flowlet ALB
基于实时感知的全局路径视图,执行层实现精细化流量调度:
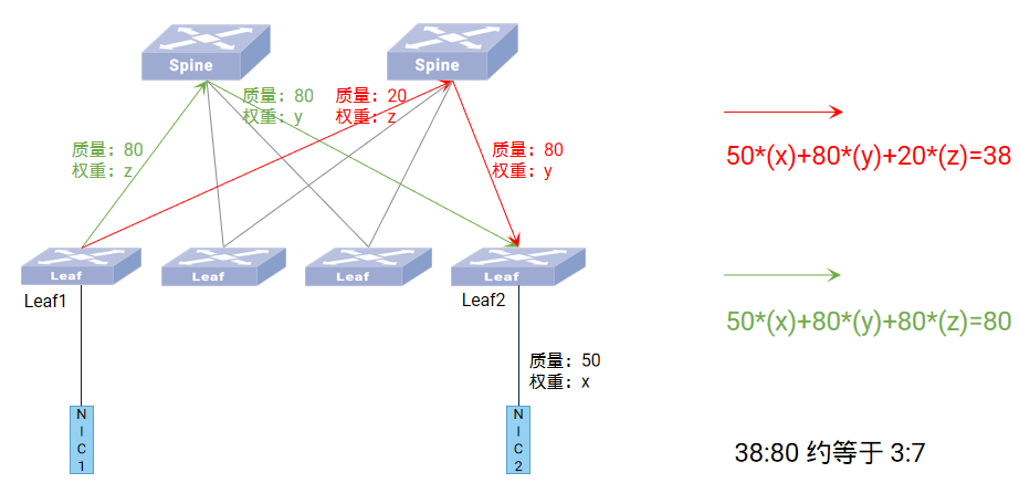
动态WCMP(加权多路径):
- 核心思想: 不再是ECMP的“平均主义”,而是根据每条路径的实时综合质量动态计算权重(如质量比38:80对应权重比3:7)。
- 效果: 将流量按比例引导到当前最优的路径上,最大化利用可用带宽,避免拥塞热点。权重随网络状态变化而动态调整。
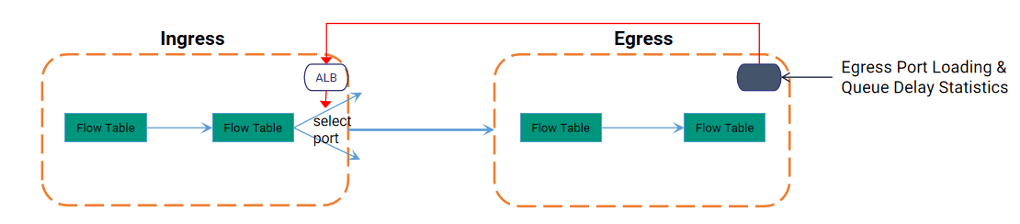
基于Flowlet的自动负载均衡(ALB):
- 作为ECMP的智能增强器: 在ECMP选定的下一跳组内,ASIC芯片实时监测组内各出端口的瞬时负载和队列时延。
- 微秒级智能调度: 当一个Flowlet(具有自然间隙的数据包子流)到达时,ALB将其动态分配到组内当前负载最轻或时延最低的物理端口上。高负载/高时延端口会被临时跳过。
- 故障自愈: 支持端口级Fail-over,链路故障时自动触发流量重分布。
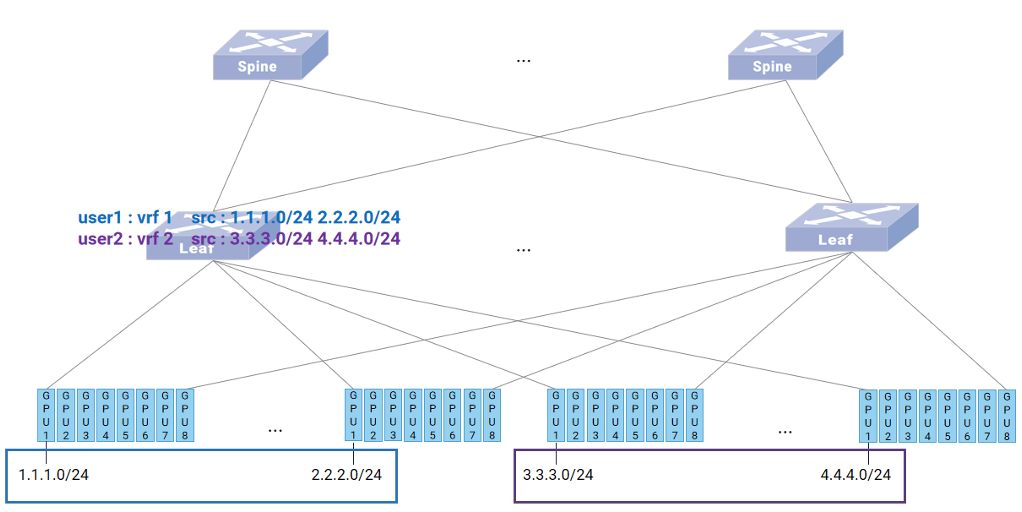
多租户支持:网络虚拟化(VRF)
AI云平台需要支持多租户隔离。
- VRF隔离: 为不同用户/租户分配独立VRF路由表。
- 基于源IP的流量分类: 利用ASIC的PRE-ACL能力,根据GPU网段源IP自动将流量划入对应的租户VRF进行查表转发,确保租户间严格隔离。
智能网络赋能AI业务场景
化解流量洪峰:动态WCMP的威力
- 场景: 256 x 400G GPU集群,1:1收敛比Leaf-Spine架构。Server1 GPU1 -> Server17 GPU1的大象流。
- 传统ECMP困境: Hash冲突可能导致所有大象流涌向同一Spine,造成Leaf1上行口拥塞丢包,拖慢整个训练任务
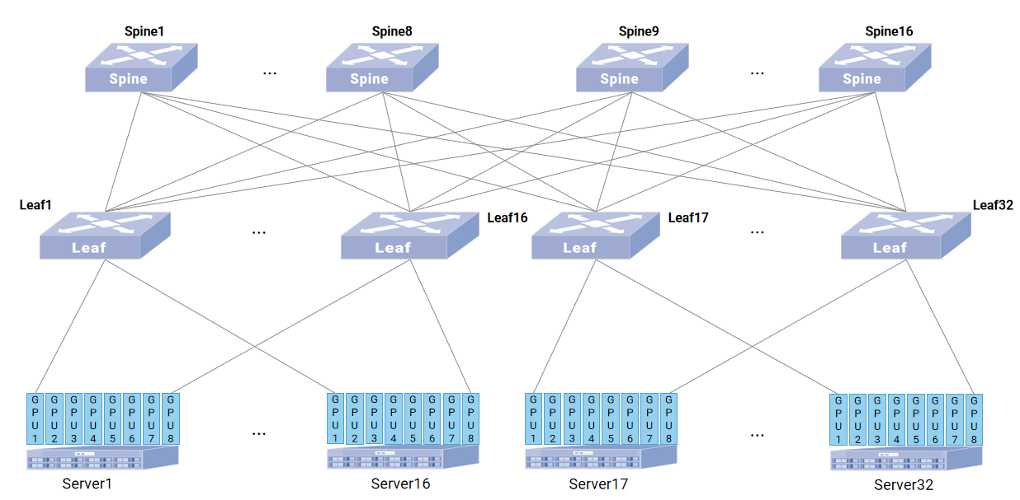
动态智能选路方案:
- Server17 GPU1的BGP路由携带Leaf17->GPU1质量宣告。
- Spine叠加自身->Leaf17质量后宣告给Leaf1。
- Leaf1叠加自身->Spine质量,汇总所有到GPU1路径的质量。
- Leaf1剔除劣质路径,基于剩余路径质量动态计算WCMP权重(如3:7)。
- 流量按最优比例分发到多条Spine路径,避免单点拥塞,保障大象流顺畅。
业务价值: 防止关键路径拥塞,稳定JCT,提升GPU集群整体利用率。
Flowlet ALB优化ECMP
- 场景: 在Leaf1到Spine的ECMP组内,某条链路突发微拥塞导致时延升高。
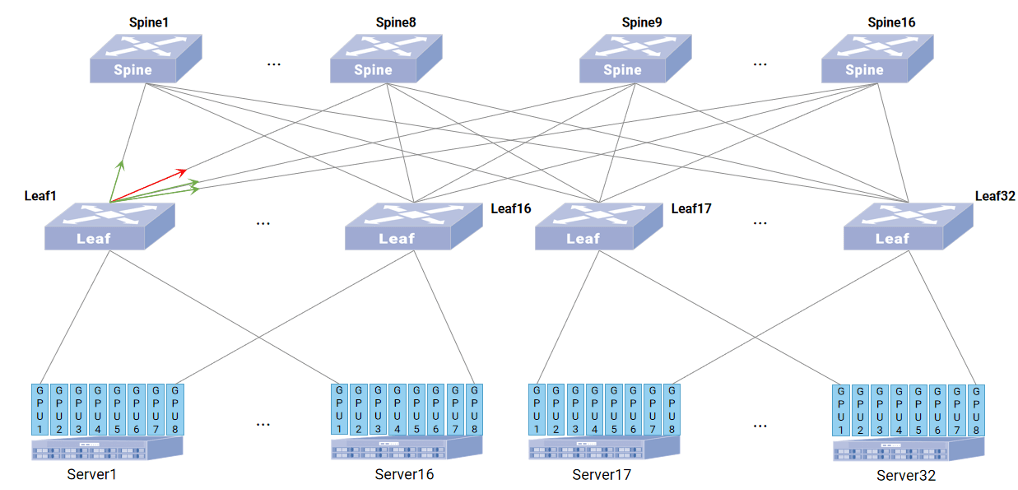
Flowlet ALB作用
- ASIC实时检测到该出端口负载/时延超标。
- 后续到达的Flowlet被自动引导至组内其他负载正常/时延低的端口。
- 拥塞端口被暂时“规避”,待其负载/时延恢复正常后,Flowlet将再次被分配至此端口。
业务价值: 消除微突发导致的局部拥塞和抖动,优化端到端时延,提升GPU计算效率。
AI时代的网络,已不再是简单的连通管道。星融元CX-N系列RoCE交换机所代表的动态感知 + 智能决策(动态WCMP) + 精准执行(Flowlet ALB) 架构,标志着网络向“AI感知网络”的深刻进化。这种进化以保障AI业务性能为核心目标,通过实时感知网络状态、智能评估路径质量、动态调整流量分布,有效化解了传统网络在AI负载下的性能瓶颈,为大规模AI训练和推理提供了稳定、高效、无损的网络基石,释放AI的真正潜力。
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 1652
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1524
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+具身智能芯片2025-09-18 3442
-
行业洞察篇__数字孪生与智能体融合:不同部署场景下技术选型的分水岭2026-05-14 177
-
人工智能在城市发展的应用及场景2018-12-21 3602
-
毫米波雷达感知技术搭建车路协同系统的可行性2020-07-01 9411
-
新一代AI ISP视频处理模组,对标Hi3559A、Hi3519A平台性能2022-06-07 3682
-
AI智能呼叫中心2023-09-20 25062
-
动态虚拟智能交通场景的研究与实现2009-04-06 517
-
基于SDWAN的智能选路技术实现2022-10-13 1761
-
多智能体协同感知 协同动态调度决策的系统2023-04-11 782
-
智算网络路径质量三要素:带宽/队列/时延在智能选路中的协同优化2025-06-13 893
-
AI智能体的技术应用与未来图景2025-07-24 1181
-
大模型驱动的星间链路动态组网分系统:功能特点与平台架构解析2025-12-23 404
全部0条评论

快来发表一下你的评论吧 !
