

透了解系统调用助你成为Linux下编程高手
电子说
描述
什么是系统调用?
Linux内核中设置了一组用于实现各种系统功能的子程序,称为系统调用。用户可以通过系统调用命令在自己的应用程序中调用它们。从某种角度来看,系统调用和普通的函数调用非常相似。区别仅仅在于,系统调用由操作系统核心提供,运行于核心态;而普通的函数调用由函数库或用户自己提供,运行于用户态。
随Linux核心还提供了一些C语言函数库,这些库对系统调用进行了一些包装和扩展,因为这些库函数与系统调用的关系非常紧密,所以习惯上把这些函数也称为系统调用。
为什么要用系统调用?
实际上,很多已经被我们习以为常的C语言标准函数,在Linux平台上的实现都是靠系统调用完成的,所以如果想对系统底层的原理作深入的了解,掌握各种系统调用是初步的要求。进一步,若想成为一名Linux下编程高手,也就是我们常说的Hacker,其标志之一也是能对各种系统调用有透彻的了解。
即使除去上面的原因,在平常的编程中你也会发现,在很多情况下,系统调用是实现你的想法的简洁有效的途径,所以有可能的话应该尽量多掌握一些系统调用,这会对你的程序设计过程带来意想不到的帮助。
系统调用是怎么工作的?
一般的,进程是不能访问内核的。它不能访问内核所占内存空间也不能调用内核函数。CPU硬件决定了这些(这就是为什么它被称作"保护模式")。系统调用是这些规则的一个例外。其原理是进程先用适当的值填充寄存器,然后调用一个特殊的指令,这个指令会跳到一个事先定义的内核中的一个位置(当然,这个位置是用户进程可读但是不可写的)。在Intel CPU中,这个由中断0x80实现。硬件知道一旦你跳到这个位置,你就不是在限制模式下运行的用户,而是作为操作系统的内核--所以你就可以为所欲为。
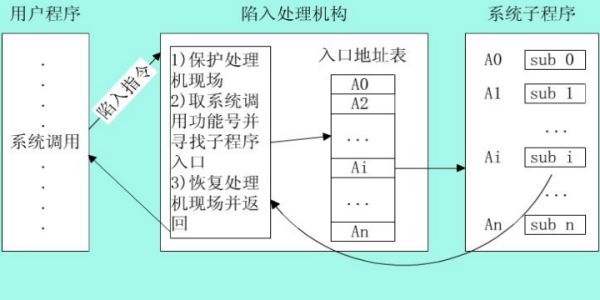
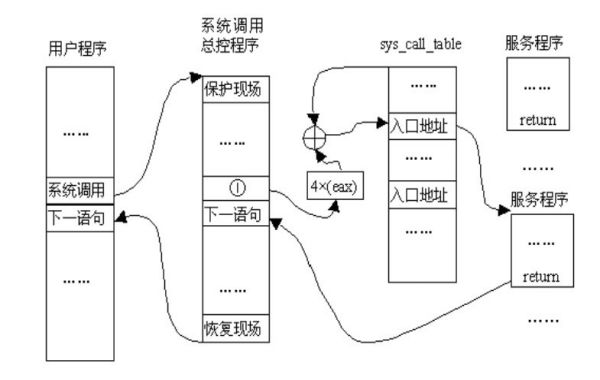
进程可以跳转到的内核位置叫做sysem_call。这个过程检查系统调用号,这个号码告诉内核进程请求哪种服务。然后,它查看系统调用表(sys_call_table)找到所调用的内核函数入口地址。接着,就调用函数,等返回后,做一些系统检查,最后返回到进程(或到其他进程,如果这个进程时间用尽)。
具体过程如下图所示:
如何使用系统调用?
先来看一个例子:
这是因为在time.h中实际上已经用库函数的形式实现了time这个系统调用,替我们省掉了调用_syscall1宏展开得到函数原型这一步。
大多数系统调用都在各种C语言函数库中有所实现,所以在一般情况下,我们都可以像调用普通的库函数那样调用系统调用,只在极个别的情况下,我们才有机会用到_syscall*()这几个宏。
调用性能问题
系统调用需要从用户空间陷入内核空间,处理完后,又需要返回用户空间。其中除了系统调用服务例程的实际耗时外,陷入/返回过程和系统调用处理程序(查系统调用表、存储\恢复用户现场)也需要花销一些时间,这些时间加起来就是一个系统调用的响应速度。系统调用不比别的用户程序,它对性能要求很苛刻,因为它需要陷入内核执行,所以和其他内核程序一样要求代码简洁、执行迅速。幸好Linux具有令人难以置信的上下文切换速度,使得其进出内核都被优化得简洁高效;同时所有Linux系统调用处理程序和每个系统调用本身也都非常简洁。
绝大多数情况下,Linux系统调用性能是可以接受的,但是对于一些对性能要求非常高的应用来说,它们虽然希望利用系统调用的服务,但却希望加快相应速度,避免陷入/返回和系统调用处理程序带来的花销,因此采用由内核直接调用系统调用服务例程,最好的例子就HTTPD——它为了避免上述开销,从内核调用socket等系统调用服务例程。
-
如何成为一名嵌入式C语言高手?2024-03-25 5164
-
Linux下C语言编程入门教程2023-09-22 542
-
Linux系统调用的具体实现原理2023-09-05 1767
-
【Linux+C语言】你真的了解system接口的调用吗?2022-09-12 5317
-
如何区分xenomai、linux系统调用/服务2022-05-10 2797
-
什么是Linux系统编程2021-12-23 901
-
需要了解Linux下的文件I/O编程2019-05-12 870
-
Linux下系统调用的技巧2019-04-02 590
-
LINUX系统教程之如何在Linux系统下进行编程2018-12-18 1507
-
Linux操作系统实用教程之如何进行Linux系统下的编程管理2018-11-01 1228
-
Linux操作系统下C语言编程入门.pdf2018-05-17 2291
-
了解各种系统调用助你成为一名Linux下编程高手2018-05-14 3585
-
基于Linux操作系统下C语言编程入门2017-10-27 1007
-
Linux系统调用及用户编程接口API分析2017-10-18 993
全部0条评论

快来发表一下你的评论吧 !
