

深度学习:卷积神经网络在每一层提取到的特征以及训练的过程
人工智能
描述
前面几篇文章讲到了卷积神经网络CNN,但是对于它在每一层提取到的特征以及训练的过程可能还是不太明白,所以这节主要通过模型的可视化来神经网络在每一层中是如何训练的。我们知道,神经网络本身包含了一系列特征提取器,理想的feature map应该是稀疏的以及包含典型的局部信息。通过模型可视化能有一些直观的认识并帮助我们调试模型,比如:feature map与原图很接近,说明它没有学到什么特征;或者它几乎是一个纯色的图,说明它太过稀疏,可能是我们feature map数太多了(feature_map数太多也反映了卷积核太小)。可视化有很多种,比如:feature map可视化、权重可视化等等,我以feature map可视化为例。
模型可视化
因为我没有搜到用paddlepaddle在imagenet 1000分类的数据集上预训练好的googLeNet inception v3,所以用了keras做实验,以下图作为输入:
输入图片
北汽绅宝D50:
feature map可视化
取网络的前15层,每层取前3个feature map。
北汽绅宝D50 feature map:

从左往右看,可以看到整个特征提取的过程,有的分离背景、有的提取轮廓,有的提取色差,但也能发现10、11层中间两个feature map是纯色的,可能这一层feature map数有点多了,另外北汽绅宝D50的光晕对feature map中光晕的影响也能比较明显看到。
Hypercolumns 通常我们把神经网络最后一个fc全连接层作为整个图片的特征表示,但是这一表示可能过于粗糙(从上面的feature map可视化也能看出来),没法精确描述局部空间上的特征,而网络的第一层空间特征又太过精确,缺乏语义信息(比如后面的色差、轮廓等),于是论文《Hypercolumns for Object Segmentation and Fine-grained Localization》提出一种新的特征表示方法:Hypercolumns——将一个像素的 hypercolumn 定义为所有 cnn 单元对应该像素位置的激活输出值组成的向量),比较好的tradeoff了前面两个问题,直观地看如图:
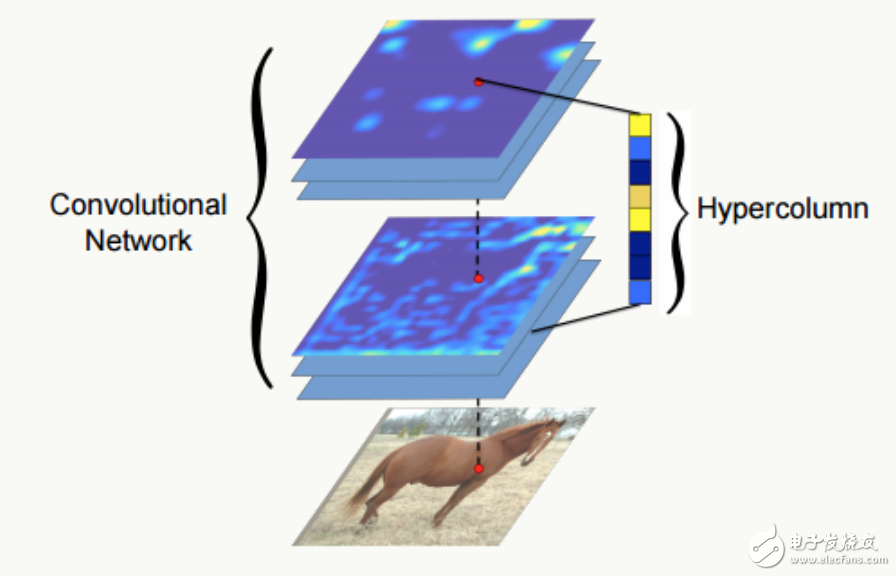
把北汽绅宝D50 第1、4、7层的feature map以及第1, 4, 7, 10, 11, 14, 17层的feature map分别做平均,可视化如下:

代码实践
# -*- coding: utf-8 -*-
from keras.applications import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.preprocessing import image
from keras.models import Model
from keras.applications.imagenet_utils import decode_predictions
import numpy as np
import cv2
from cv2 import *
import matplotlib.pyplot as plt
import scipy as sp
from scipy.misc import toimage
def test_opencv():
# 加载摄像头
cam = VideoCapture(0) # 0 -> 摄像头序号,如果有两个三个四个摄像头,要调用哪一个数字往上加嘛
# 抓拍 5 张小图片
for x in range(0, 5):
s, img = cam.read()
if s:
imwrite("o-" + str(x) + ".jpg", img)
def load_original(img_path):
# 把原始图片压缩为 299*299大小
im_original = cv2.resize(cv2.imread(img_path), (299, 299))
im_converted = cv2.cvtColor(im_original, cv2.COLOR_BGR2RGB)
plt.figure(0)
plt.subplot(211)
plt.imshow(im_converted)
return im_original
def load_fine_tune_googlenet_v3(img):
# 加载fine-tuning googlenet v3模型,并做预测
model = InceptionV3(include_top=True, weights='imagenet')
model.summary()
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
print('Predicted:', decode_predictions(preds))
plt.subplot(212)
plt.plot(preds.ravel())
plt.show()
return model, x
def extract_features(ins, layer_id, filters, layer_num):
'''
提取指定模型指定层指定数目的feature map并输出到一幅图上.
:param ins: 模型实例
:param layer_id: 提取指定层特征
:param filters: 每层提取的feature map数
:param layer_num: 一共提取多少层feature map
:return: None
'''
if len(ins) != 2:
print('parameter error:(model, instance)')
return None
model = ins[0]
x = ins[1]
if type(layer_id) == type(1):
model_extractfeatures = Model(input=model.input, output=model.get_layer(index=layer_id).output)
else:
model_extractfeatures = Model(input=model.input, output=model.get_layer(name=layer_id).output)
fc2_features = model_extractfeatures.predict(x)
if filters > len(fc2_features[0][0][0]):
print('layer number error.', len(fc2_features[0][0][0]),',',filters)
return None
for i in range(filters):
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)
plt.subplot(filters, layer_num, layer_id + 1 + i * layer_num)
plt.axis("off")
if i < len(fc2_features[0][0][0]):
plt.imshow(fc2_features[0, :, :, i])
# 层数、模型、卷积核数
def extract_features_batch(layer_num, model, filters):
'''
批量提取特征
:param layer_num: 层数
:param model: 模型
:param filters: feature map数
:return: None
'''
plt.figure(figsize=(filters, layer_num))
plt.subplot(filters, layer_num, 1)
for i in range(layer_num):
extract_features(model, i, filters, layer_num)
plt.savefig('sample.jpg')
plt.show()
def extract_features_with_layers(layers_extract):
'''
提取hypercolumn并可视化.
:param layers_extract: 指定层列表
:return: None
'''
hc = extract_hypercolumn(x[0], layers_extract, x[1])
ave = np.average(hc.transpose(1, 2, 0), axis=2)
plt.imshow(ave)
plt.show()
def extract_hypercolumn(model, layer_indexes, instance):
'''
提取指定模型指定层的hypercolumn向量
:param model: 模型
:param layer_indexes: 层id
:param instance: 模型
:return:
'''
feature_maps = []
for i in layer_indexes:
feature_maps.append(Model(input=model.input, output=model.get_layer(index=i).output).predict(instance))
hypercolumns = []
for convmap in feature_maps:
for i in convmap[0][0][0]:
upscaled = sp.misc.imresize(convmap[0, :, :, i], size=(299, 299), mode="F", interp='bilinear')
hypercolumns.append(upscaled)
return np.asarray(hypercolumns)
if __name__ == '__main__':
img_path = '~/auto1.jpg'
img = load_original(img_path)
x = load_fine_tune_googlenet_v3(img)
extract_features_batch(15, x, 3)
extract_features_with_layers([1, 4, 7])
extract_features_with_layers([1, 4, 7, 10, 11, 14, 17])
总结
还有一些网站做的关于CNN的可视化做的非常不错,譬如这个网站:http://shixialiu.com/publications/cnnvis/demo/,大家可以在训练的时候采取不同的卷积核尺寸和个数对照来看训练的中间过程。最近PaddlePaddle也开源了可视化工具VisaulDL,下篇文章我们讲讲paddlepaddle的visualDL和tesorflow的tensorboard。
-
卷积神经网络训练的是什么2024-07-03 2021
-
卷积神经网络的基本原理、结构及训练过程2024-07-02 5481
-
卷积神经网络层级结构 卷积神经网络的卷积层讲解2023-08-21 11216
-
卷积神经网络简介:什么是机器学习?2023-02-23 25565
-
卷积神经网络模型发展及应用2022-08-02 13393
-
为什么卷积神经网络可以做到不变性特征提取?2021-05-20 6224
-
卷积神经网络是怎样实现不变性特征提取的?2021-04-30 3570
-
一种用于图像分类的卷积神经网络2018-07-04 10646
-
从AlexNet到MobileNet,带你入门深度神经网络2018-05-08 2860
-
卷积神经网络的基本结构和运行原理2017-12-12 1889
全部0条评论

快来发表一下你的评论吧 !
