

利用强化学习探索多巴胺对学习的作用
电子说
描述
继上周在 Nature 发表极受关注的“网格细胞”研究后,DeepMind今天又在《自然-神经科学》发表一篇重磅论文:利用强化学习探索多巴胺对学习的作用,发现AI的学习方式与神经科学实验中动物的学习方式类似。该研究提出的理论可以解释神经科学和心理学中的许多神秘发现。
AI系统已经掌握了多种电子游戏,如雅达利经典的“突出重围”(Breakout)和“乒乓球”(Pong)游戏。但尽管AI在玩游戏方便的表现令人印象深刻,它们仍然是依靠相当于数千小时的游戏时间训练,才达到或超越人类的水平。相比之下,我们人类通常只花几分钟就能掌握一款我们从未玩过的电子游戏的基础知识。
为什么只有这么少的先验知识,人类的大脑却能做这么多的事情呢?这就引出了“元学习”(meta-learning)的理论,或者说“学习如何学习”(learning to learn)。人们认为,人是在两个时间尺度上学习的——在短期,我们专注于学习具体的例子;而在较长的时间尺度,我们学习完成一项任务所需的抽象技能或规则。正是这种组合被认为有助于人高效地学习,并将这些知识快速灵活地应用于新任务。
在 AI 系统中重建这种元学习结构——称为元强化学习(meta-reinforcement learning)——已经被证明能够促进智能体(agents)快速、one-shot的学习。这方面的研究已经有很多,例如DeepMind的论文“Learning to reinforcement learn”和OpenAI的“RL²: Fast Reinforcement Learning via Slow Reinforcement Learning”。然而,促使这个过程在大脑中发生的具体机制是怎样的,这在神经科学中大部分仍未得到解释。
今天,DeepMind在《自然-神经科学》(Nature Neuroscience)发表的新论文中,研究人员使用AI研究中开发的元强化学习框架来探索多巴胺在大脑中帮助我们学习时所起的作用。论文题为:Prefrontal cortex as a meta-reinforcement learning system。

多巴胺——通常被称为大脑的愉悦因子——被认为与AI强化学习算法中使用的奖励预测误差信号类似。AI系统通过奖励(reward)指引的试错来学习如何行动。研究者认为,多巴胺的作用不仅仅是利用奖励来学习过去行为的价值,而且,多巴胺在大脑的前额叶皮层区扮演者不可或缺的角色,使我们能够高效、快速、灵活地学习新任务。
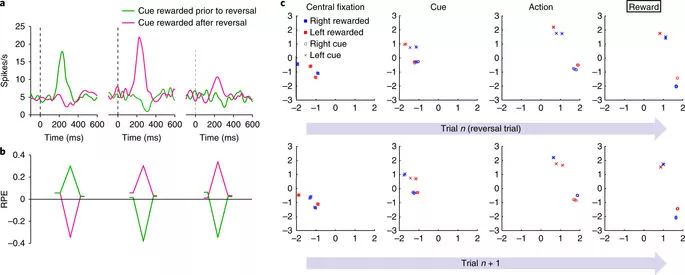
模拟agent的奖励预测误差反映了推断值,而不仅仅是经验值,类似于在猴子中观察到的。
DeepMind的研究人员通过模拟重建神经科学领域的6个元学习实验来测试他们的理论——每个实验都要求一个agent执行任务,这些任务使用相同的基础原则(或同一套技能),但在某些方面有所不同。
我们使用标准深度强化学习技术(代表多巴胺的作用)训练了一个循环神经网络(代表前额叶皮质),然后将这个循环网络的活动状态与之前在神经科学实验中得到的实际数据进行比较。对于元学习来说,循环网络是一个很好的代理,因为它们能够将过去的行为和观察内在化,然后在训练各种各样的任务时借鉴这些经验。
我们重建的一个实验叫做Harlow实验,这是20世纪40年代的一个心理学实验,用于探索元学习的概念。在原版的测试中,一组猴子被展示两个不熟悉的物体,只有其中一个会给他们食物奖励。两个物体一共被展示了6次,每次的左右放置都是随机的,所以猴子必须要知道哪个会给它们食物奖励。然后,他们再次被展示另外两个新的物体,同样,只有其中一个会给它们食物。
在这个训练过程中,猴子发展出一种策略来选择能得到奖励的物体:它学会了在第一次的时候随机选择,然后,下一次根据奖励的反馈选择特定的对象,而不是从左到右选择。这个实验表明,猴子可以将任务的基本原理内化,学会一种抽象的规则结构——实际上就是学会了如何学习。
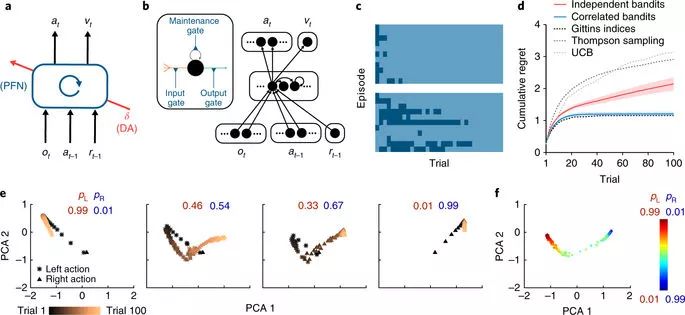
meta-RL 的架构
当我们使用虚拟的计算机屏幕和随机选择的图像来模拟一个非常相似的测试时,我们发现,我们的“元强化学习智能体”(meta-RL agent)似乎是以类似于Harlow实验中的动物的方式在学习,甚至在被显示以前从未见过的全新图像时也是如此。
在模拟的Harlow实验中,agent必须将它的视线转向它认为能得到奖励的对象
实际上,我们发现meta-RL agent可以学习如何快速适应规则和结构不同的各种任务。而且,由于网络学会了如何适应各种任务,它也学会了关于如何有效学习的一般原则。
很重要的一点是,我们发现大部分的学习发生在循环网络中,这支持了我们的观点,即多巴胺在元学习过程中的作用比以前人们认为的更为重要。传统上,多巴胺被认为能够加强前额叶系统的突触连接,从而强化特定的行为。
在AI中,这意味着类多巴胺的奖励信号在神经网络中调整人工突触的权重,因为它学会了解决任务的正确方法。然而,在我们的实验中,神经网络的权重被冻结,这意味着在学习过程中权重不能被调整。但是,meta-RL agent仍然能够解决并适应新的任务。这表明,类多巴胺的奖励不仅用于调整权重,而且还能传递和编码有关抽象任务和规则结构的重要信息,从而加快对新任务的适应。
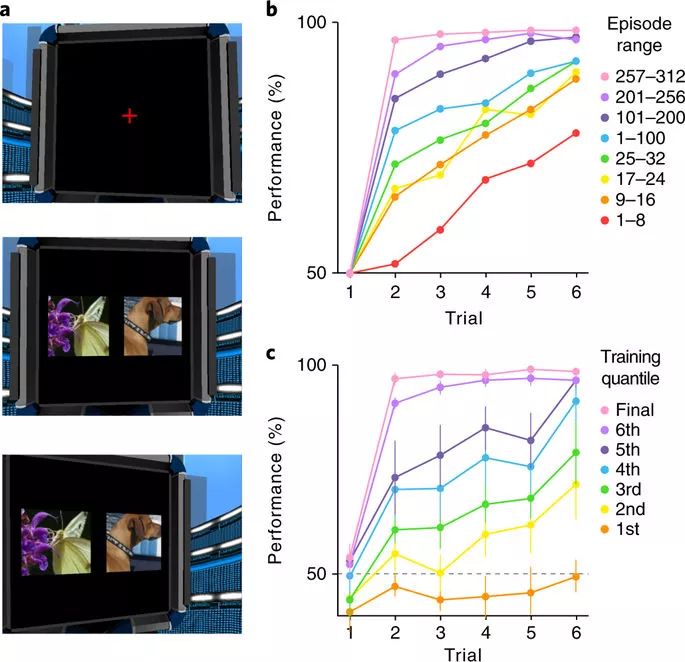
Meta-RL在视觉丰富的3D环境中学习抽象结构和新的刺激
长期以来,神经科学家在大脑的前额叶皮质中观察到类似的神经活动模式,这种模式能够快速适应,而且很灵活,但一直以来科学家难以找到能够解释为什么会这样的充分理由。前额叶皮层不依赖突触重量的缓慢变化来学习规则结构,而是使用直接编码在多巴胺上的、抽象的基于模式的信息,这一观点提供了一个更令人信服的解释。
为了证明AI中存在的引起元强化学习的关键因素也存在于大脑中,我们提出了一个理论,该理论不仅与已知的关于多巴胺和前额叶皮层的了解相符,而且可以解释神经科学和心理学中的许多神秘发现。特别是,该理论对了解大脑中结构化的、基于模式的学习是如何出现的,为什么多巴胺本身包含有基于模式的信息,以及前额叶皮质中的神经元是如何调整为与学习相关的信号等问题提出了新的启发。
来自AI研究的见解可以用于解释神经科学和心理学的发现,这强调了,一个研究领域的价值可以提供给另一个领域。展望未来,我们期望能从反过来的方向得到更多益处,通过在为强化学习智能体的学习设计新的模型时,从特定脑回路组织得到启发。
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28261
-
反向强化学习的思路2019-04-03 0
-
深度强化学习实战2021-01-10 0
-
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向2017-12-27 11411
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4335
-
人工智能机器学习之强化学习2018-05-30 1471
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 17877
-
基于强化学习的MADDPG算法原理及实现2018-11-02 22036
-
深度强化学习到底是什么?它的工作原理是怎么样的2020-06-13 6398
-
DeepMind发布强化学习库RLax2020-12-10 834
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1008
-
模型化深度强化学习应用研究综述2021-04-12 984
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 1743
-
什么是强化学习2023-10-30 4579
-
如何使用 PyTorch 进行强化学习2024-11-05 717
全部0条评论

快来发表一下你的评论吧 !
