

ϊ╗Αϊ╣Ιόαψόε║ίβρίφοϊ╣ιΎ╝θόε║ίβρίφοϊ╣ιϋΔ╜ϋπμίΗ│ϊ╗Αϊ╣ΙώΩχώλαΎ╝θΎ╝ΙόκΙϊ╛ΜίΙΗόηΡΎ╝Κ
ϊ║║ί╖ξόβ║ϋΔ╜
όΠΠϋ┐░
ώγΠύζΑίνπόΧ░όΞχόΩ╢ϊ╗μύγΕίΙ░όζξΎ╝Νόε║ίβρίφοϊ╣ιόΙΡϊ╕║ϋπμίΗ│ώΩχώλαύγΕϊ╕ΑύπΞώΘΞϋοΒϊ╕ΦίΖ│ώΦχύγΕί╖ξίΖ╖ήΑΓϊ╕Ξύχκόαψί╖ξϊ╕γύΧΝϋ┐αόαψίφοόεψύΧΝΎ╝Νόε║ίβρίφοϊ╣ιώΔ╜όαψϊ╕Αϊ╕ςύΓβόΚΜίΠψύΔφύγΕόΨ╣ίΡΣΎ╝Νϊ╜ΗόαψίφοόεψύΧΝίΤΝί╖ξ ϊ╕γύΧΝίψ╣όε║ίβρίφοϊ╣ιύγΕύιΦύσ╢ίΡΕόεΚϊ╛πώΘΞΎ╝ΝίφοόεψύΧΝϊ╛πώΘΞϊ║Οίψ╣όε║ίβρίφοϊ╣ιύΡΗϋχ║ύγΕύιΦύσ╢Ύ╝Νί╖ξϊ╕γύΧΝϊ╛πώΘΞϊ║ΟίοΓϊ╜ΧύΦρόε║ίβρίφοϊ╣ιόζξϋπμίΗ│ίχηώβΖώΩχώλαήΑΓόΙΣϊ╗υύ╗ΥίΡΙύ╛Οίδλίερόε║ίβρίφοϊ╣ιϊ╕ΛύγΕίχηϋ╖╡Ύ╝Νϋ┐δϋκΝϊ╕Α ϊ╕ςίχηόΙαΎ╝ΙInActionΎ╝Κύ│╗ίΙΩύγΕϊ╗Μύ╗ΞΎ╝Ιί╕ο“όε║ίβρίφοϊ╣ιInActionύ│╗ίΙΩ”όιΘύφ╛ύγΕόΨΘύτιΎ╝ΚΎ╝Νϊ╗Μύ╗Ξόε║ίβρίφοϊ╣ιίερϋπμίΗ│ί╖ξϊ╕γύΧΝώΩχώλαύγΕίχηόΙαϊ╕φόΚΑώεΑύγΕίθ║όευόΛΑόεψήΑΒύ╗ΠώςΝίΤΝ όΛΑί╖πήΑΓόευόΨΘϊ╕╗ϋοΒύ╗ΥίΡΙίχηώβΖώΩχώλαΎ╝ΝόοΓϋοΒίε░ϊ╗Μύ╗Ξόε║ίβρίφοϊ╣ιϋπμίΗ│ίχηώβΖώΩχώλαύγΕόΧ┤ϊ╕ςό╡ΒύρΜΎ╝ΝίΝΖόΜυίψ╣ώΩχώλαί╗║όρκήΑΒίΘΗίνΘϋχφύ╗ΔόΧ░όΞχήΑΒόΛ╜ίΠΨύΚ╣ί╛ΒήΑΒϋχφύ╗ΔόρκίηΜίΤΝϊ╝αίΝΨόρκίηΜύφΚίΖ│ώΦχύΟψϋΛΓΎ╝δίΠοίνΨ ίΘιύψΘίΙβϊ╝γίψ╣ϋ┐βϊ║δίΖ│ώΦχύΟψϋΛΓϋ┐δϋκΝόδ┤ό╖▒ίΖξίε░ϊ╗Μύ╗ΞήΑΓ
ϊ╕ΜόΨΘίΙΗϊ╕║1Ύ╝Κόε║ίβρίφοϊ╣ιύγΕόοΓϋ┐░Ύ╝Ν2Ύ╝Κίψ╣ώΩχώλαί╗║όρκΎ╝Ν3Ύ╝ΚίΘΗίνΘϋχφύ╗ΔόΧ░όΞχΎ╝Ν4Ύ╝ΚόΛ╜ίΠΨύΚ╣ί╛ΒΎ╝Ν5Ύ╝Κϋχφύ╗ΔόρκίηΜΎ╝Ν6Ύ╝Κϊ╝αίΝΨόρκίηΜΎ╝Ν7Ύ╝ΚόΑ╗ύ╗Υ ίΖ▒7ϊ╕ςύτιϋΛΓϋ┐δϋκΝϊ╗Μύ╗ΞήΑΓ
όε║ίβρίφοϊ╣ιύγΕόοΓϋ┐░Ύ╝γϊ╗Αϊ╣Ιόαψόε║ίβρίφοϊ╣ιΎ╝θ
ώγΠύζΑόε║ίβρίφοϊ╣ιίερίχηώβΖί╖ξϊ╕γώλΗίθθϊ╕φϊ╕ΞόΨφϋΟ╖ί╛Ωί║ΦύΦρΎ╝Νϋ┐βϊ╕ςϋψΞί╖▓ύ╗Πϋλτϋ╡Μϊ║Ιϊ║ΗίΡΕύπΞϊ╕ΞίΡΝίΡτϊ╣ΚήΑΓίερόευόΨΘϊ╕φύγΕ“όε║ίβρίφοϊ╣ι”ίΡτϊ╣Κϊ╕Οwikipediaϊ╕ΛύγΕϋπμώΘΛόψΦϋ╛ΔίξΣ ίΡΙΎ╝ΝίοΓϊ╕ΜΎ╝γMachine learning is a scientific discipline that deals with the construction and study of algorithms that can learn from data.
όε║ίβρίφοϊ╣ιίΠψϊ╗ξίΙΗϊ╕║όΩιύδΣύζμίφοϊ╣ιΎ╝Ιunsupervised learningΎ╝ΚίΤΝόεΚύδΣύζμίφοϊ╣ιΎ╝Ιsupervised learningΎ╝ΚΎ╝Νίερί╖ξϊ╕γύΧΝϊ╕φΎ╝ΝόεΚύδΣύζμίφοϊ╣ιόαψόδ┤ί╕╕ϋπΒίΤΝόδ┤όεΚϊ╗╖ίΑ╝ύγΕόΨ╣ί╝ΠΎ╝Νϊ╕ΜόΨΘϊ╕φϊ╕╗ϋοΒϊ╗ξϋ┐βύπΞόΨ╣ί╝Πί▒Χί╝Αϊ╗Μύ╗ΞήΑΓίοΓϊ╕Μίδ╛ϊ╕φόΚΑύν║Ύ╝ΝόεΚύδΣύζμύγΕόε║ίβρίφοϊ╣ιίερϋπμίΗ│ίχηώβΖώΩχώλα όΩ╢Ύ╝ΝόεΚϊ╕νϊ╕ςό╡ΒύρΜΎ╝Νϊ╕Αϊ╕ςόαψύο╗ύ║┐ϋχφύ╗Δό╡ΒύρΜΎ╝ΙϋΥζϋΚ▓ύχφίν┤Ύ╝ΚΎ╝ΝίΝΖίΡτόΧ░όΞχύφδώΑΚίΤΝό╕Ζό┤ΩήΑΒύΚ╣ί╛ΒόΛ╜ίρ╢όρκίηΜϋχφύ╗ΔίΤΝϊ╝αίΝΨόρκίηΜύφΚύΟψϋΛΓΎ╝δίΠοϊ╕Αϊ╕ςό╡ΒύρΜίΙβόαψί║ΦύΦρό╡ΒύρΜΎ╝Ιύ╗┐ϋΚ▓ύχφίν┤Ύ╝ΚΎ╝Νίψ╣ώεΑ ϋοΒώλΕϊ╝░ύγΕόΧ░όΞχΎ╝ΝόΛ╜ίΠΨύΚ╣ί╛ΒΎ╝Νί║ΦύΦρύο╗ύ║┐ϋχφύ╗Δί╛ΩίΙ░ύγΕόρκίηΜϋ┐δϋκΝώλΕϊ╝░Ύ╝ΝϋΟ╖ί╛ΩώλΕϊ╝░ίΑ╝ϊ╜εύΦρίερίχηώβΖϊ║πίΥΒϊ╕φήΑΓίερϋ┐βϊ╕νϊ╕ςό╡ΒύρΜϊ╕φΎ╝Νύο╗ύ║┐ϋχφύ╗ΔόαψόεΑόεΚόΛΑόεψόΝΣόΙαύγΕί╖ξϊ╜εΎ╝Ιίερύ║┐ώλΕϊ╝░ό╡ΒύρΜί╛Ι ίνγί╖ξϊ╜είΠψϊ╗ξίνΞύΦρύο╗ύ║┐ϋχφύ╗Δό╡ΒύρΜύγΕί╖ξϊ╜εΎ╝ΚΎ╝ΝόΚΑϊ╗ξϊ╕ΜόΨΘϊ╕╗ϋοΒϊ╗Μύ╗Ξύο╗ύ║┐ϋχφύ╗Δό╡ΒύρΜήΑΓ
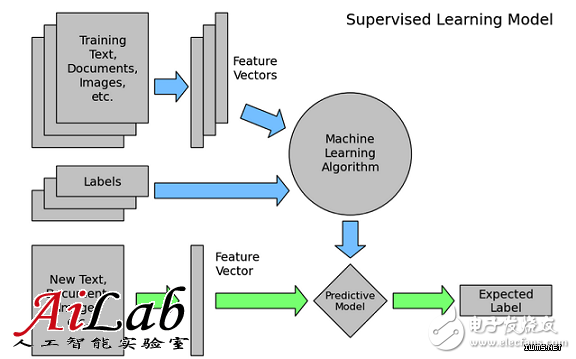
ϊ╗Αϊ╣ΙόαψόρκίηΜΎ╝ΙmodelΎ╝ΚΎ╝θ
όρκίηΜΎ╝Νόαψόε║ίβρίφοϊ╣ιϊ╕φύγΕϊ╕Αϊ╕ςώΘΞϋοΒόοΓί┐╡Ύ╝ΝύχΑίΞΧύγΕϋχ▓Ύ╝ΝόΝΘύΚ╣ί╛Βύσ║ώΩ┤ίΙ░ϋ╛ΥίΘ║ύσ║ώΩ┤ύγΕόαιί░ΕΎ╝δϊ╕ΑϋΙυύΦ▒όρκίηΜύγΕίΒΘϋχ╛ίΘ╜όΧ░ίΤΝίΠΓόΧ░wύ╗ΕόΙΡΎ╝Ιϊ╕ΜώζλίΖυί╝Πί░▒όαψLogistic RegressionόρκίηΜύγΕϊ╕ΑύπΞϋκρϋ╛╛Ύ╝Νίερϋχφύ╗ΔόρκίηΜύγΕύτιϋΛΓίΒγύρΞϋψού╗ΗύγΕϋπμώΘΛΎ╝ΚΎ╝δϊ╕Αϊ╕ςόρκίηΜύγΕίΒΘϋχ╛ύσ║ώΩ┤Ύ╝Ιhypothesis spaceΎ╝ΚΎ╝ΝόΝΘύ╗βίχγόρκίηΜόΚΑόεΚίΠψϋΔ╜wίψ╣ί║ΦύγΕϋ╛ΥίΘ║ύσ║ώΩ┤ύ╗ΕόΙΡύγΕώδΗίΡΙήΑΓί╖ξϊ╕γύΧΝί╕╕ύΦρύγΕόρκίηΜόεΚLogistic RegressionΎ╝ΙύχΑύπ░LRΎ╝ΚήΑΒGradient Boosting Decision TreeΎ╝ΙύχΑύπ░GBDTΎ╝ΚήΑΒSupport Vector MachineΎ╝ΙύχΑύπ░SVMΎ╝ΚήΑΒDeep Neural NetworkΎ╝ΙύχΑύπ░DNNΎ╝ΚύφΚήΑΓ
όρκίηΜϋχφύ╗Δί░▒όαψίθ║ϊ║Οϋχφύ╗ΔόΧ░όΞχΎ╝ΝϋΟ╖ί╛Ωϊ╕Αύ╗ΕίΠΓόΧ░wΎ╝Νϊ╜┐ί╛ΩύΚ╣ίχγύδχόιΘόεΑϊ╝αΎ╝ΝίΞ│ϋΟ╖ί╛Ωϊ║ΗύΚ╣ί╛Βύσ║ώΩ┤ίΙ░ϋ╛ΥίΘ║ύσ║ώΩ┤ύγΕόεΑϊ╝αόαιί░ΕΎ╝ΝίΖ╖ϊ╜ΥόΑΟϊ╣ΙίχηύΟ░Ύ╝ΝϋπΒϋχφύ╗ΔόρκίηΜύτιϋΛΓήΑΓ
ϊ╕║ϊ╗Αϊ╣ΙϋοΒύΦρόε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαΎ╝θ
ύδχίΚΞίνΕϊ║ΟίνπόΧ░όΞχόΩ╢ϊ╗μΎ╝ΝίΙ░ίνΕώΔ╜όεΚόΙΡTόΙΡPύγΕόΧ░όΞχΎ╝ΝύχΑίΞΧϋπΕίΙβίνΕύΡΗώγ╛ϊ╗ξίΠΣόΝξϋ┐βϊ║δόΧ░όΞχύγΕϊ╗╖ίΑ╝Ύ╝δ
ί╗Κϊ╗╖ύγΕώταόΑπϋΔ╜ϋχκύχΩΎ╝Νϊ╜┐ί╛Ωίθ║ϊ║ΟίνπϋπΕόρκόΧ░όΞχύγΕίφοϊ╣ιόΩ╢ώΩ┤ίΤΝϊ╗μϊ╗╖ώβΞϊ╜ΟΎ╝δ
ί╗Κϊ╗╖ύγΕίνπϋπΕόρκίφαίΓρΎ╝Νϊ╜┐ί╛ΩϋΔ╜ίνθόδ┤ί┐τίε░ίΤΝϊ╗μϊ╗╖όδ┤ί░Πίε░ίνΕύΡΗίνπϋπΕόρκόΧ░όΞχΎ╝δ
ίφαίερίνπώΘΠώταϊ╗╖ίΑ╝ύγΕώΩχώλαΎ╝Νϊ╜┐ί╛ΩϋΛ▒ίνπώΘΠύ▓╛ίΛδύΦρόε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαίΡΟΎ╝ΝϋΔ╜ϋΟ╖ί╛Ωϊ╕░ίΟγόΦ╢ύδΛήΑΓ
όε║ίβρίφοϊ╣ιί║ΦϋψξύΦρϊ║ΟϋπμίΗ│ϊ╗Αϊ╣ΙώΩχώλαΎ╝θ
ύδχόιΘώΩχώλαώεΑϋοΒϊ╗╖ίΑ╝ί╖ρίνπΎ╝Νίδιϊ╕║όε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαόεΚϊ╕ΑίχγύγΕϊ╗μϊ╗╖Ύ╝δ
ύδχόιΘώΩχώλαόεΚίνπώΘΠόΧ░όΞχίΠψύΦρΎ╝ΝόεΚίνπώΘΠόΧ░όΞχόΚΞϋΔ╜ϊ╜┐όε║ίβρίφοϊ╣ιόψΦϋ╛Δίξ╜ίε░ϋπμίΗ│ώΩχώλαΎ╝Ιύδ╕ίψ╣ϊ║ΟύχΑίΞΧϋπΕίΙβόΙΨϊ║║ί╖ξΎ╝ΚΎ╝δ
ύδχόιΘώΩχώλαύΦ▒ίνγύπΞίδιύ┤ιΎ╝ΙύΚ╣ί╛ΒΎ╝ΚίΗ│ίχγΎ╝Νόε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαύγΕϊ╝αίΛ┐όΚΞϋΔ╜ϊ╜ΥύΟ░Ύ╝Ιύδ╕ίψ╣ϊ║ΟύχΑίΞΧϋπΕίΙβόΙΨϊ║║ί╖ξΎ╝ΚΎ╝δ
ύδχόιΘώΩχώλαώεΑϋοΒόΝΒύ╗φϊ╝αίΝΨΎ╝Νίδιϊ╕║όε║ίβρίφοϊ╣ιίΠψϊ╗ξίθ║ϊ║ΟόΧ░όΞχϋΘςόΙΣίφοϊ╣ιίΤΝϋ┐φϊ╗μΎ╝ΝόΝΒύ╗φίε░ίΠΣόΝξϊ╗╖ίΑ╝ήΑΓ
ίψ╣ώΩχώλαί╗║όρκ
όευόΨΘϊ╗ξDEALΎ╝Ιίδλϋ┤φίΞΧΎ╝Κϊ║νόαΥώλζώλΕϊ╝░ώΩχώλαϊ╕║ϊ╛ΜΎ╝Ιί░▒όαψώλΕϊ╝░ϊ╕Αϊ╕ςύ╗βίχγDEALϊ╕Αόχ╡όΩ╢ώΩ┤ίΗΖίΞΨϊ║Ηίνγί░ΣώΤ▒Ύ╝ΚΎ╝Νϊ╗Μύ╗Ξϊ╜┐ύΦρόε║ίβρίφοϊ╣ιίοΓϊ╜ΧϋπμίΗ│ώΩχώλαήΑΓώοΨίΖΙώεΑϋοΒΎ╝γ
όΦ╢ώδΗώΩχώλαύγΕϋ╡ΕόΨβΎ╝ΝύΡΗϋπμώΩχώλαΎ╝ΝόΙΡϊ╕║ϋ┐βϊ╕ςώΩχώλαύγΕϊ╕Υίχ╢Ύ╝δ
όΜΗϋπμώΩχώλαΎ╝ΝύχΑίΝΨώΩχώλαΎ╝Νί░ΗώΩχώλαϋ╜υίΝΨόε║ίβρίΠψώλΕϊ╝░ύγΕώΩχώλαήΑΓ
ό╖▒ίΖξύΡΗϋπμίΤΝίΙΗόηΡDEALϊ║νόαΥώλζίΡΟΎ╝ΝίΠψϊ╗ξί░ΗίχΔίΙΗϋπμϊ╕║ίοΓϊ╕Μίδ╛ύγΕίΘιϊ╕ςώΩχώλαΎ╝γ
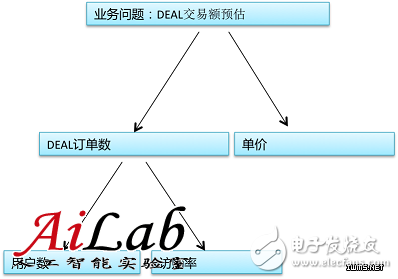
ίΞΧϊ╕ςόρκίηΜΎ╝θίνγϊ╕ςόρκίηΜΎ╝θίοΓϊ╜ΧόζξώΑΚόΜσΎ╝θ
όΝΚύΖπϊ╕Λίδ╛ϋ┐δϋκΝόΜΗϋπμίΡΟΎ╝ΝώλΕϊ╝░DEALϊ║νόαΥώλζί░▒όεΚ2ύπΞίΠψϋΔ╜όρκί╝ΠΎ╝Νϊ╕ΑύπΞόαψύδ┤όΟξώλΕϊ╝░ϊ║νόαΥώλζΎ╝δίΠοϊ╕ΑύπΞόαψώλΕϊ╝░ίΡΕίφΡώΩχώλαΎ╝ΝίοΓί╗║ύτΜϊ╕Αϊ╕ςύΦρόΙ╖όΧ░όρκίηΜίΤΝί╗║ύτΜϊ╕Αϊ╕ςϋχ┐ϋ┤φύΟΘόρκίηΜΎ╝Ιϋχ┐ώΩχϋ┐βϊ╕ςDEALύγΕύΦρόΙ╖ϊ╝γϋ┤φϊ╣░ύγΕίΞΧίφΡόΧ░Ύ╝ΚΎ╝ΝίΗΞίθ║ϊ║Οϋ┐βϊ║δίφΡώΩχώλαύγΕώλΕϊ╝░ίΑ╝ϋχκύχΩϊ║νόαΥώλζήΑΓ
ϊ╕ΞίΡΝόΨ╣ί╝ΠόεΚϊ╕ΞίΡΝϊ╝αύ╝║ύΓ╣Ύ╝ΝίΖ╖ϊ╜ΥίοΓϊ╕ΜΎ╝γ
όρκί╝Πύ╝║ύΓ╣ϊ╝αύΓ╣
ίΞΧόρκίηΜ 1. ώλΕϊ╝░ώγ╛ί║οίνπ2. ώμΟώβσόψΦϋ╛Δώτα 1. ύΡΗϋχ║ϊ╕ΛίΠψϊ╗ξϋΟ╖ί╛ΩόεΑϊ╝αώλΕϊ╝░Ύ╝ΙίχηώβΖϊ╕Λί╛Ιώγ╛Ύ╝Κ2. ϊ╕ΑόυκϋπμίΗ│ώΩχώλα
ίνγόρκίηΜ 1. ίΠψϋΔ╜ϊ║πύΦθύπψύ┤ψϋψψί╖χ2. ϋχφύ╗ΔίΤΝί║ΦύΦρόΙΡόευώτα 1. ίΞΧϊ╕ςίφΡόρκίηΜόδ┤ίχ╣όαΥίχηύΟ░όψΦϋ╛ΔίΘΗίε░ώλΕϊ╝░2. ίΠψϊ╗ξϋ░ΔόΧ┤ίφΡόρκίηΜύγΕϋηΞίΡΙόΨ╣ί╝ΠΎ╝Νϊ╗ξϋ╛╛ίΙ░όεΑϊ╜│όΧΙόηε
ώΑΚόΜσίΥςύπΞόρκί╝ΠΎ╝θ
1Ύ╝ΚώΩχώλαίΠψώλΕϊ╝░ύγΕώγ╛ί║οΎ╝Νώγ╛ί║οίνπΎ╝ΝίΙβϋΑΔϋβΣύΦρίνγόρκίηΜΎ╝δ
2Ύ╝ΚώΩχώλαόευϋ║τύγΕώΘΞϋοΒόΑπΎ╝ΝώΩχώλαί╛ΙώΘΞϋοΒΎ╝ΝίΙβϋΑΔϋβΣύΦρίνγόρκίηΜΎ╝δ
3Ύ╝Κίνγϊ╕ςόρκίηΜύγΕίΖ│ύ│╗όαψίΡοόαΟύκχΎ╝ΝίΖ│ύ│╗όαΟύκχΎ╝ΝίΙβίΠψϊ╗ξύΦρίνγόρκίηΜήΑΓ
ίοΓόηεώΘΘύΦρίνγόρκίηΜΎ╝ΝίοΓϊ╜ΧϋηΞίΡΙΎ╝θίΠψϊ╗ξόι╣όΞχώΩχώλαύγΕύΚ╣ύΓ╣ίΤΝϋοΒό▒Γϋ┐δϋκΝύ║┐όΑπϋηΞίΡΙΎ╝ΝόΙΨϋ┐δϋκΝίνΞόζΓύγΕϋηΞίΡΙήΑΓϊ╗ξόευόΨΘώΩχώλαϊ╕║ϊ╛ΜΎ╝ΝϋΘ│ί░ΣίΠψϊ╗ξόεΚίοΓϊ╕Μϊ╕νύπΞΎ╝γ
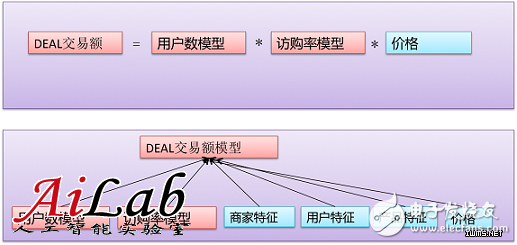
όρκίηΜώΑΚόΜσ
ίψ╣ϊ║ΟDEALϊ║νόαΥώλζϋ┐βϊ╕ςώΩχώλαΎ╝ΝόΙΣϊ╗υϋχνϊ╕║ύδ┤όΟξώλΕϊ╝░ώγ╛ί║οί╛ΙίνπΎ╝Νί╕ΝόεδόΜΗόΙΡίφΡώΩχώλαϋ┐δϋκΝώλΕϊ╝░Ύ╝ΝίΞ│ίνγόρκίηΜόρκί╝ΠήΑΓώΓμόι╖ί░▒ώεΑϋοΒί╗║ύτΜύΦρόΙ╖όΧ░όρκίηΜίΤΝϋχ┐ϋ┤φύΟΘόρκίηΜΎ╝Νίδιϊ╕║όε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαύγΕόΨ╣ί╝Πύ▒╗ϊ╝╝Ύ╝Νϊ╕ΜόΨΘίΠςϊ╗ξϋχ┐ϋ┤φύΟΘόρκίηΜϊ╕║ϊ╛ΜήΑΓϋοΒϋπμίΗ│ϋχ┐ϋ┤φύΟΘώΩχώλαΎ╝ΝώοΨίΖΙϋοΒώΑΚόΜσόρκίηΜΎ╝ΝόΙΣϊ╗υόεΚίοΓϊ╕ΜύγΕϊ╕Αϊ║δϋΑΔϋβΣΎ╝γ
ϊ╕╗ϋοΒϋΑΔϋβΣ
1Ύ╝ΚώΑΚόΜσϊ╕Οϊ╕γίΛκύδχόιΘϊ╕ΑϋΘ┤ύγΕόρκίηΜΎ╝δ
2Ύ╝ΚώΑΚόΜσϊ╕Οϋχφύ╗ΔόΧ░όΞχίΤΝύΚ╣ί╛Βύδ╕ύυούγΕόρκίηΜήΑΓ
ϋχφύ╗ΔόΧ░όΞχί░ΣΎ╝ΝHigh LevelύΚ╣ί╛ΒίνγΎ╝ΝίΙβϊ╜┐ύΦρ“ίνΞόζΓ”ύγΕώζηύ║┐όΑπόρκίηΜΎ╝Ιό╡ΒϋκΝύγΕGBDTήΑΒRandom ForestύφΚΎ╝ΚΎ╝δϋχφύ╗ΔόΧ░όΞχί╛ΙίνπώΘΠΎ╝ΝLow LevelύΚ╣ί╛ΒίνγΎ╝ΝίΙβϊ╜┐ύΦρ“ύχΑίΞΧ”ύγΕύ║┐όΑπόρκίηΜΎ╝Ιό╡ΒϋκΝύγΕLRήΑΒLinear-SVMύφΚΎ╝ΚήΑΓ
ϋκξίΖΖϋΑΔϋβΣ
1Ύ╝Κί╜ΥίΚΞόρκίηΜόαψίΡοϋλτί╖ξϊ╕γύΧΝί╣┐ό│δϊ╜┐ύΦρΎ╝δ
2Ύ╝Κί╜ΥίΚΞόρκίηΜόαψίΡοόεΚόψΦϋ╛ΔόΙΡύΗθύγΕί╝Αό║Ρί╖ξίΖ╖ίΝΖΎ╝ΙίΖυίΠ╕ίΗΖόΙΨίΖυίΠ╕ίνΨΎ╝ΚΎ╝δ
3Ύ╝Κί╜ΥίΚΞί╖ξίΖ╖ίΝΖϋΔ╜ίνθύγΕίνΕύΡΗόΧ░όΞχώΘΠϋΔ╜ίΡοό╗κϋ╢│ϋοΒό▒ΓΎ╝δ
4Ύ╝ΚϋΘςί╖▒ίψ╣ί╜ΥίΚΞόρκίηΜύΡΗϋχ║όαψίΡοϊ║ΗϋπμΎ╝ΝόαψίΡοϊ╣ΜίΚΞύΦρϋ┐ΘϋψξόρκίηΜϋπμίΗ│ώΩχώλαήΑΓ
ϊ╕║ίχηώβΖώΩχώλαώΑΚόΜσόρκίηΜΎ╝ΝώεΑϋοΒϋ╜υίΝΨώΩχώλαύγΕϊ╕γίΛκύδχόιΘϊ╕║όρκίηΜϋψΕϊ╗╖ύδχόιΘΎ╝Νϋ╜υίΝΨόρκίηΜϋψΕϊ╗╖ύδχόιΘϊ╕║όρκίηΜϊ╝αίΝΨύδχόιΘΎ╝δόι╣όΞχϊ╕γίΛκύγΕϊ╕ΞίΡΝύδχόιΘΎ╝ΝώΑΚόΜσίΡΙώΑΓύγΕόρκίηΜΎ╝ΝίΖ╖ϊ╜ΥίΖ│ύ│╗ίοΓϊ╕ΜΎ╝γ
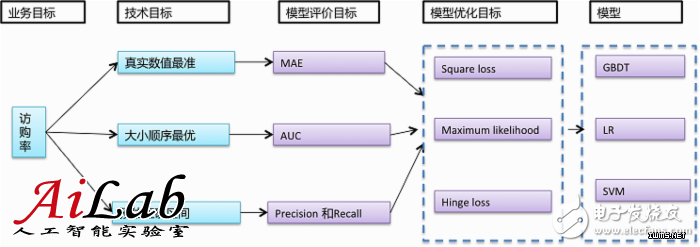
ώΑγί╕╕όζξϋχ▓Ύ╝ΝώλΕϊ╝░ύεθίχηόΧ░ίΑ╝Ύ╝Ιίδηί╜ΤΎ╝ΚήΑΒίνπί░Πώκ║ί║ΠΎ╝ΙόΟΤί║ΠΎ╝ΚήΑΒύδχόιΘόΚΑίερύγΕόφμύκχίΝ║ώΩ┤Ύ╝ΙίΙΗύ▒╗Ύ╝ΚύγΕώγ╛ί║οϊ╗ΟίνπίΙ░ί░ΠΎ╝Νόι╣όΞχί║ΦύΦρόΚΑώεΑΎ╝Νί░╜ίΠψϋΔ╜ώΑΚόΜσώγ╛ί║οί░ΠύγΕύδχόιΘϋ┐δϋκΝήΑΓ ίψ╣ϊ║Οϋχ┐ϋ┤φύΟΘώλΕϊ╝░ύγΕί║ΦύΦρύδχόιΘόζξϋψ┤Ύ╝ΝόΙΣϊ╗υϋΘ│ί░ΣώεΑϋοΒύθξώΒΥίνπί░Πώκ║ί║ΠόΙΨύεθίχηόΧ░ίΑ╝Ύ╝ΝόΚΑϊ╗ξόΙΣϊ╗υίΠψϊ╗ξώΑΚόΜσArea Under CurveΎ╝ΙAUCΎ╝ΚόΙΨMean Absolute ErrorΎ╝ΙMAEΎ╝Κϊ╜εϊ╕║ϋψΕϊ╝░ύδχόιΘΎ╝Νϊ╗ξMaximum likelihoodϊ╕║όρκίηΜόΞθίν▒ίΘ╜όΧ░Ύ╝ΙίΞ│ϊ╝αίΝΨύδχόιΘΎ╝ΚήΑΓύ╗╝ϊ╕ΛόΚΑϋ┐░Ύ╝ΝόΙΣϊ╗υώΑΚόΜσsparkύΚΙόευ GBDTόΙΨLRΎ╝Νϊ╕╗ϋοΒίθ║ϊ║ΟίοΓϊ╕ΜϋΑΔϋβΣΎ╝γ
1Ύ╝ΚίΠψϊ╗ξϋπμίΗ│όΟΤί║ΠόΙΨίδηί╜ΤώΩχώλαΎ╝δ
2Ύ╝ΚόΙΣϊ╗υϋΘςί╖▒ίχηύΟ░ϊ║ΗύχΩό│ΧΎ╝Νύ╗Πί╕╕ϊ╜┐ύΦρΎ╝ΝόΧΙόηεί╛Ιίξ╜Ύ╝δ
3Ύ╝ΚόΦψόΝΒό╡╖ώΘΠόΧ░όΞχΎ╝δ
4Ύ╝Κί╖ξϊ╕γύΧΝί╣┐ό│δϊ╜┐ύΦρήΑΓ
ίΘΗίνΘϋχφύ╗ΔόΧ░όΞχ
ό╖▒ίΖξύΡΗϋπμώΩχώλαΎ╝ΝώΤΙίψ╣ώΩχώλαώΑΚόΜσϊ║Ηύδ╕ί║ΦύγΕόρκίηΜίΡΟΎ╝ΝόΟξϊ╕ΜόζξίΙβώεΑϋοΒίΘΗίνΘόΧ░όΞχΎ╝δόΧ░όΞχόαψόε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαύγΕόι╣όευΎ╝ΝόΧ░όΞχώΑΚόΜσϊ╕Ξίψ╣Ύ╝ΝίΙβώΩχώλαϊ╕ΞίΠψϋΔ╜ϋλτϋπμίΗ│Ύ╝ΝόΚΑϊ╗ξίΘΗίνΘϋχφύ╗ΔόΧ░όΞχώεΑϋοΒόι╝ίνΨύγΕί░Πί┐ΔίΤΝό│ρόΕΠΎ╝γ
ό│ρόΕΠύΓ╣Ύ╝γ
ί╛ΖϋπμίΗ│ώΩχώλαύγΕόΧ░όΞχόευϋ║τύγΕίΙΗί╕Δί░╜ώΘΠϊ╕ΑϋΘ┤Ύ╝δ
ϋχφύ╗ΔώδΗ/ό╡ΜϋψΧώδΗίΙΗί╕Δϊ╕Ού║┐ϊ╕ΛώλΕό╡ΜύΟψίλΔύγΕόΧ░όΞχίΙΗί╕Δί░╜ίΠψϋΔ╜ϊ╕ΑϋΘ┤Ύ╝Νϋ┐βώΘΝύγΕίΙΗί╕ΔόαψόΝΘΎ╝Ιx,yΎ╝ΚύγΕίΙΗί╕ΔΎ╝Νϊ╕Ξϊ╗Ζϊ╗ΖόαψyύγΕίΙΗί╕ΔΎ╝δ
yόΧ░όΞχίβςώθ│ί░╜ίΠψϋΔ╜ί░ΠΎ╝Νί░╜ώΘΠίΚΦώβνyόεΚίβςώθ│ύγΕόΧ░όΞχΎ╝δ
ώζηί┐ΖϋοΒϊ╕ΞίΒγώΘΘόι╖Ύ╝ΝώΘΘόι╖ί╕╕ί╕╕ίΠψϋΔ╜ϊ╜┐ίχηώβΖόΧ░όΞχίΙΗί╕ΔίΠΣύΦθίΠαίΝΨΎ╝Νϊ╜ΗόαψίοΓόηεόΧ░όΞχίνςίνπόΩιό│Χϋχφύ╗ΔόΙΨϋΑΖόφμϋ┤θόψΦϊ╛Μϊ╕ξώΘΞίν▒ϋ░ΔΎ╝ΙίοΓϋ╢Ζϋ┐Θ100:1Ύ╝Κ,ίΙβώεΑϋοΒώΘΘόι╖ϋπμίΗ│ήΑΓ
ί╕╕ϋπΒώΩχώλαίΠΛϋπμίΗ│ίΛηό│Χ
ί╛ΖϋπμίΗ│ώΩχώλαύγΕόΧ░όΞχίΙΗί╕Δϊ╕Ξϊ╕ΑϋΘ┤Ύ╝γ
1Ύ╝Κϋχ┐ϋ┤φύΟΘώΩχώλαϊ╕φDEALόΧ░όΞχίΠψϋΔ╜ί╖χί╝Γί╛ΙίνπΎ╝ΝίοΓύ╛ΟώμθDEALίΤΝώΖΤί║ΩDEALύγΕί╜▒ίΥΞίδιύ┤ιόΙΨϋκρύΟ░ί╛Ιϊ╕Ξϊ╕ΑϋΘ┤Ύ╝ΝώεΑϋοΒίΒγύΚ╣ίΙτίνΕύΡΗΎ╝δϋοΒϊ╣Ιίψ╣όΧ░όΞχόΠΡίΚΞί╜Τϊ╕ΑίΝΨΎ╝ΝϋοΒϊ╣Ιί░ΗίΙΗί╕Δϊ╕Ξϊ╕ΑϋΘ┤ίδιύ┤ιϊ╜εϊ╕║ύΚ╣ί╛ΒΎ╝ΝϋοΒϊ╣Ιίψ╣ίΡΕύ▒╗ίΙτDEALίΞΧύΜυϋχφύ╗ΔόρκίηΜήΑΓ
όΧ░όΞχίΙΗί╕ΔίΠαίΝΨϊ║ΗΎ╝γ
1Ύ╝ΚύΦρίΞΛί╣┤ίΚΞύγΕόΧ░όΞχϋχφύ╗ΔόρκίηΜΎ╝ΝύΦρόζξώλΕό╡Μί╜ΥίΚΞόΧ░όΞχΎ╝Νίδιϊ╕║όΧ░όΞχίΙΗί╕ΔώγΠύζΑόΩ╢ώΩ┤ίΠψϋΔ╜ίΠαίΝΨϊ║ΗΎ╝ΝόΧΙόηείΠψϋΔ╜ί╛Ιί╖χήΑΓί░╜ώΘΠύΦρϋ┐ΣόεθύγΕόΧ░όΞχϋχφύ╗ΔΎ╝ΝόζξώλΕό╡Μί╜ΥίΚΞόΧ░όΞχΎ╝ΝίΟΗίΠ▓ύγΕόΧ░όΞχίΠψϊ╗ξίΒγώβΞόζΔύΦρίΙ░όρκίηΜΎ╝ΝόΙΨίΒγtransfer learningήΑΓ
yόΧ░όΞχόεΚίβςώθ│Ύ╝γ
1Ύ╝Κίερί╗║ύτΜCTRόρκίηΜόΩ╢Ύ╝Νί░ΗύΦρόΙ╖ό▓κόεΚύεΜίΙ░ύγΕItemϊ╜εϊ╕║ϋ┤θϊ╛ΜΎ╝Νϋ┐βϊ║δItemόαψίδιϊ╕║ύΦρόΙ╖ό▓κόεΚύεΜίΙ░όΚΞό▓κόεΚϋλτύΓ╣ίΘ╗Ύ╝Νϊ╕Ξϊ╕ΑίχγόαψύΦρόΙ╖ϊ╕ΞίΨεόυλϋΑΝό▓κόεΚϋλτύΓ╣ίΘ╗Ύ╝ΝόΚΑϊ╗ξϋ┐βϊ║δ ItemόαψόεΚίβςώθ│ύγΕήΑΓίΠψϊ╗ξώΘΘύΦρϊ╕Αϊ║δύχΑίΞΧϋπΕίΙβΎ╝ΝίΚΦώβνϋ┐βϊ║δίβςώθ│ϋ┤θϊ╛ΜΎ╝ΝίοΓώΘΘύΦρskip-aboveόΑζόΔ│Ύ╝ΝίΞ│ύΦρόΙ╖ύΓ╣ϋ┐ΘύγΕItemϊ╣Μϊ╕ΛΎ╝Νό▓κόεΚύΓ╣ϋ┐ΘύγΕItemϊ╜εϊ╕║ϋ┤θϊ╛Μ Ύ╝ΙίΒΘϋχ╛ύΦρόΙ╖όαψϊ╗Οϊ╕Λί╛Αϊ╕Μό╡ΠϋπΙItemΎ╝ΚήΑΓ
ώΘΘόι╖όΨ╣ό│ΧόεΚίΒΠΎ╝Νό▓κόεΚϋοΗύδΨόΧ┤ϊ╕ςώδΗίΡΙΎ╝γ
1Ύ╝Κϋχ┐ϋ┤φύΟΘώΩχώλαϊ╕φΎ╝ΝίοΓόηείΠςίΠΨίΠςόεΚϊ╕Αϊ╕ςώΩρί║ΩύγΕDEALϋ┐δϋκΝώλΕϊ╝░Ύ╝ΝίΙβίψ╣ϊ║ΟίνγώΩρί║ΩύγΕDEALόΩιό│Χί╛Ιίξ╜ώλΕϊ╝░ήΑΓί║Φϋψξϊ┐ζϋψΒϊ╕Αϊ╕ςώΩρί║ΩύγΕίΤΝίνγϊ╕ςώΩρί║ΩύγΕDEALόΧ░όΞχώΔ╜όεΚΎ╝δ
2Ύ╝ΚόΩιίχλϋπΓόΧ░όΞχύγΕϊ║ΝίΙΗύ▒╗ώΩχώλαΎ╝ΝύΦρϋπΕίΙβόζξϋΟ╖ί╛Ωόφμ/ϋ┤θϊ╛ΜΎ╝ΝϋπΕίΙβίψ╣όφμ/ϋ┤θϊ╛ΜύγΕϋοΗύδΨϊ╕ΞίΖρώζλήΑΓί║ΦϋψξώγΠόε║όΛ╜όι╖όΧ░όΞχΎ╝Νϋ┐δϋκΝϊ║║ί╖ξόιΘό│ρΎ╝Νϊ╗ξύκχϊ┐ζόΛ╜όι╖όΧ░όΞχίΤΝίχηώβΖόΧ░όΞχίΙΗί╕Δϊ╕ΑϋΘ┤ήΑΓ
ϋχ┐ϋ┤φύΟΘώΩχώλαύγΕϋχφύ╗ΔόΧ░όΞχ
όΦ╢ώδΗNϊ╕ςόεΙύγΕDEALόΧ░όΞχΎ╝ΙxΎ╝ΚίΠΛύδ╕ί║Φϋχ┐ϋ┤φύΟΘΎ╝ΙyΎ╝ΚΎ╝δ
όΦ╢ώδΗόεΑϋ┐ΣNϊ╕ςόεΙΎ╝ΝίΚΦώβνϋΛΓίΒΘόΩξύφΚώζηί╕╕ϋπΕόΩ╢ώΩ┤ Ύ╝Ιϊ┐ζόΝΒίΙΗί╕Δϊ╕ΑϋΘ┤Ύ╝ΚΎ╝δ
ίΠςόΦ╢ώδΗίερύ║┐όΩ╢ώΧ┐>T ϊ╕Φ ϋχ┐ώΩχύΦρόΙ╖όΧ░ > UύγΕDEAL Ύ╝ΙίΘΠί░ΣyύγΕίβςώθ│Ύ╝ΚΎ╝δ
ϋΑΔϋβΣDEALώΦΑώΘΠύΦθίΣ╜ίΣρόεθ Ύ╝Ιϊ┐ζόΝΒίΙΗί╕Δϊ╕ΑϋΘ┤Ύ╝ΚΎ╝δ
ϋΑΔϋβΣϊ╕ΞίΡΝίθΟί╕ΓήΑΒϊ╕ΞίΡΝίΧΗίεΙήΑΒϊ╕ΞίΡΝίΥΒύ▒╗ύγΕί╖χίΙτ Ύ╝Ιϊ┐ζόΝΒίΙΗί╕Δϊ╕ΑϋΘ┤Ύ╝ΚήΑΓ
όΛ╜ίΠΨύΚ╣ί╛Β
ίχΝόΙΡόΧ░όΞχύφδώΑΚίΤΝό╕Ζό┤ΩίΡΟΎ╝Νί░▒ώεΑϋοΒίψ╣όΧ░όΞχόΛ╜ίΠΨύΚ╣ί╛ΒΎ╝Νί░▒όαψίχΝόΙΡϋ╛ΥίΖξύσ║ώΩ┤ίΙ░ύΚ╣ί╛Βύσ║ώΩ┤ύγΕϋ╜υόΞλΎ╝ΙϋπΒϊ╕Μίδ╛Ύ╝ΚήΑΓώΤΙίψ╣ύ║┐όΑπόρκίηΜόΙΨώζηύ║┐όΑπόρκίηΜώεΑϋοΒϋ┐δϋκΝϊ╕ΞίΡΝύΚ╣ί╛ΒόΛ╜ίΠΨΎ╝Νύ║┐όΑπόρκίηΜώεΑϋοΒόδ┤ίνγύΚ╣ί╛ΒόΛ╜ίΠΨί╖ξϊ╜είΤΝόΛΑί╖πΎ╝ΝϋΑΝώζηύ║┐όΑπόρκίηΜίψ╣ύΚ╣ί╛ΒόΛ╜ίΠΨϋοΒό▒Γύδ╕ίψ╣ϋ╛Δϊ╜ΟήΑΓ
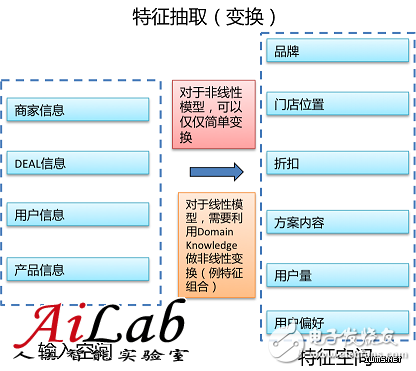
ώΑγί╕╕Ύ╝ΝύΚ╣ί╛ΒίΠψϊ╗ξίΙΗϊ╕║High Levelϊ╕ΟLow LevelΎ╝ΝHigh LevelόΝΘίΡτϊ╣ΚόψΦϋ╛Δό│δύγΕύΚ╣ί╛ΒΎ╝ΝLow LevelόΝΘίΡτϊ╣ΚόψΦϋ╛ΔύΚ╣ίχγύγΕύΚ╣ί╛ΒΎ╝Νϊ╕╛ϊ╛Μόζξϋψ┤Ύ╝γ
DEAL A1ί▒ηϊ║ΟPOIAΎ╝Νϊ║║ίζΘ50ϊ╗ξϊ╕ΜΎ╝Νϋχ┐ϋ┤φύΟΘώταΎ╝δDEAL A2ί▒ηϊ║ΟPOIAΎ╝Νϊ║║ίζΘ50ϊ╗ξϊ╕ΛΎ╝Νϋχ┐ϋ┤φύΟΘώταΎ╝δDEAL B1ί▒ηϊ║ΟPOIBΎ╝Νϊ║║ίζΘ50ϊ╗ξϊ╕ΜΎ╝Νϋχ┐ϋ┤φύΟΘώταΎ╝δDEAL B2ί▒ηϊ║ΟPOIBΎ╝Νϊ║║ίζΘ50ϊ╗ξϊ╕ΛΎ╝Νϋχ┐ϋ┤φύΟΘί║ΧΎ╝δ
ίθ║ϊ║Οϊ╕ΛώζλύγΕόΧ░όΞχΎ╝ΝίΠψϊ╗ξόΛ╜ίΙ░ϊ╕νύπΞύΚ╣ί╛ΒΎ╝ΝPOIΎ╝ΙώΩρί║ΩΎ╝ΚόΙΨϊ║║ίζΘό╢Ιϋ┤╣Ύ╝δPOIύΚ╣ί╛ΒίΙβόαψLow LevelύΚ╣ί╛ΒΎ╝Νϊ║║ίζΘό╢Ιϋ┤╣ίΙβόαψHigh LevelύΚ╣ί╛ΒΎ╝δίΒΘϋχ╛όρκίηΜώΑγϋ┐Θίφοϊ╣ιΎ╝ΝϋΟ╖ί╛ΩίοΓϊ╕ΜώλΕϊ╝░Ύ╝γ
ίοΓόηεDEALx ί▒ηϊ║ΟPOIAΎ╝ΙLow Level featureΎ╝ΚΎ╝Νϋχ┐ϋ┤φύΟΘώταΎ╝δίοΓόηεDEALx ϊ║║ίζΘ50ϊ╗ξϊ╕ΜΎ╝ΙHigh Level featureΎ╝ΚΎ╝Νϋχ┐ϋ┤φύΟΘώταήΑΓ
όΚΑϊ╗ξΎ╝ΝόΑ╗ϊ╜Υϊ╕ΛΎ╝ΝLow Level όψΦϋ╛ΔόεΚώΤΙίψ╣όΑπΎ╝ΝίΞΧϊ╕ςύΚ╣ί╛ΒϋοΗύδΨώζλί░ΠΎ╝ΙίΡτόεΚϋ┐βϊ╕ςύΚ╣ί╛ΒύγΕόΧ░όΞχϊ╕ΞίνγΎ╝ΚΎ╝ΝύΚ╣ί╛ΒόΧ░ώΘΠΎ╝Ιύ╗┤ί║οΎ╝Κί╛ΙίνπήΑΓHigh LevelόψΦϋ╛Δό│δίΝΨΎ╝ΝίΞΧϊ╕ςύΚ╣ί╛ΒϋοΗύδΨώζλίνπΎ╝ΙίΡτόεΚϋ┐βϊ╕ςύΚ╣ί╛ΒύγΕόΧ░όΞχί╛ΙίνγΎ╝ΚΎ╝ΝύΚ╣ί╛ΒόΧ░ώΘΠΎ╝Ιύ╗┤ί║οΎ╝Κϊ╕ΞίνπήΑΓώΧ┐ί░╛όι╖όευύγΕώλΕό╡ΜίΑ╝ϊ╕╗ϋοΒίΠΩHigh LevelύΚ╣ί╛Βί╜▒ίΥΞήΑΓώταώλΣόι╖όευύγΕώλΕό╡ΜίΑ╝ϊ╕╗ϋοΒίΠΩLow LevelύΚ╣ί╛Βί╜▒ίΥΞήΑΓ
ίψ╣ϊ║Οϋχ┐ϋ┤φύΟΘώΩχώλαΎ╝ΝόεΚίνπώΘΠύγΕHigh LevelόΙΨLow LevelύγΕύΚ╣ί╛ΒΎ╝ΝίΖ╢ϊ╕φϊ╕Αϊ║δί▒Χύν║ίερϊ╕Μίδ╛Ύ╝γ
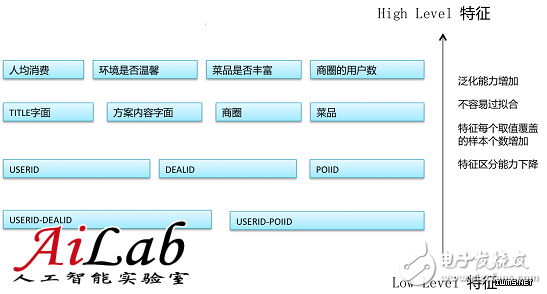
ώζηύ║┐όΑπόρκίηΜύγΕύΚ╣ί╛Β
1Ύ╝ΚίΠψϊ╗ξϊ╕╗ϋοΒϊ╜┐ύΦρHigh LevelύΚ╣ί╛ΒΎ╝Νίδιϊ╕║ϋχκύχΩίνΞόζΓί║οίνπΎ╝ΝόΚΑϊ╗ξύΚ╣ί╛Βύ╗┤ί║οϊ╕ΞίχείνςώταΎ╝δ
2Ύ╝ΚώΑγϋ┐ΘHigh Levelώζηύ║┐όΑπόαιί░ΕίΠψϊ╗ξόψΦϋ╛Δίξ╜ίε░όΜθίΡΙύδχόιΘήΑΓ
ύ║┐όΑπόρκίηΜύγΕύΚ╣ί╛Β
1Ύ╝ΚύΚ╣ί╛Βϊ╜Υύ│╗ϋοΒί░╜ίΠψϋΔ╜ίΖρώζλΎ╝ΝHigh LevelίΤΝLow LevelώΔ╜ϋοΒόεΚΎ╝δ
2Ύ╝ΚίΠψϊ╗ξί░ΗHigh Levelϋ╜υόΞλLow LevelΎ╝Νϊ╗ξόΠΡίΞΘόρκίηΜύγΕόΜθίΡΙϋΔ╜ίΛδήΑΓ
ύΚ╣ί╛Βί╜Τϊ╕ΑίΝΨ
ύΚ╣ί╛ΒόΛ╜ίΠΨίΡΟΎ╝ΝίοΓόηεϊ╕ΞίΡΝύΚ╣ί╛ΒύγΕίΠΨίΑ╝ϋΝΔίδ┤ύδ╕ί╖χί╛ΙίνπΎ╝ΝόεΑίξ╜ίψ╣ύΚ╣ί╛Βϋ┐δϋκΝί╜Τϊ╕ΑίΝΨΎ╝Νϊ╗ξίΠΨί╛Ωόδ┤ίξ╜ύγΕόΧΙόηεΎ╝Νί╕╕ϋπΒύγΕί╜Τϊ╕ΑίΝΨόΨ╣ί╝ΠίοΓϊ╕ΜΎ╝γ
RescalingΎ╝γ
ί╜Τϊ╕ΑίΝΨίΙ░[0,1] όΙΨ [-1Ύ╝Ν1]Ύ╝ΝύΦρύ▒╗ϊ╝╝όΨ╣ί╝ΠΎ╝γ
StandardizationΎ╝γ
ϋχ╛ϊ╕║xίΙΗί╕ΔύγΕίζΘίΑ╝Ύ╝Ν
ϊ╕║xίΙΗί╕ΔύγΕόιΘίΘΗί╖χΎ╝δ
Scaling to unit lengthΎ╝γ
ί╜Τϊ╕ΑίΝΨίΙ░ίΞΧϊ╜ΞώΧ┐ί║οίΡΣώΘΠ
ύΚ╣ί╛ΒώΑΚόΜσ
ύΚ╣ί╛ΒόΛ╜ίΠΨίΤΝί╜Τϊ╕ΑίΝΨϊ╣ΜίΡΟΎ╝ΝίοΓόηείΠΣύΟ░ύΚ╣ί╛ΒίνςίνγΎ╝Νίψ╝ϋΘ┤όρκίηΜόΩιό│Χϋχφύ╗ΔΎ╝ΝόΙΨί╛Ιίχ╣όαΥίψ╝ϋΘ┤όρκίηΜϋ┐ΘόΜθίΡΙΎ╝ΝίΙβώεΑϋοΒίψ╣ύΚ╣ί╛Βϋ┐δϋκΝώΑΚόΜσΎ╝ΝόΝΣώΑΚόεΚϊ╗╖ίΑ╝ύγΕύΚ╣ί╛ΒήΑΓ
FilterΎ╝γίΒΘϋχ╛ύΚ╣ί╛ΒίφΡώδΗίψ╣όρκίηΜώλΕϊ╝░ύγΕί╜▒ίΥΞϊ║Τύδ╕ύΜυύτΜΎ╝ΝώΑΚόΜσϊ╕Αϊ╕ςύΚ╣ί╛ΒίφΡώδΗΎ╝ΝίΙΗόηΡϋψξίφΡώδΗίΤΝόΧ░όΞχLabelύγΕίΖ│ύ│╗Ύ╝ΝίοΓόηείφαίερόθΡύπΞόφμύδ╕ίΖ│Ύ╝ΝίΙβϋχνϊ╕║ϋψξύΚ╣ί╛ΒίφΡώδΗόεΚόΧΙήΑΓϋκκώΘΠύΚ╣ί╛ΒίφΡώδΗίΤΝόΧ░όΞχLabelίΖ│ύ│╗ύγΕύχΩό│ΧόεΚί╛ΙίνγΎ╝ΝίοΓChi-squareΎ╝ΝInformation GainήΑΓ
WrapperΎ╝γώΑΚόΜσϊ╕Αϊ╕ςύΚ╣ί╛ΒίφΡώδΗίΛιίΖξίΟθόεΚύΚ╣ί╛ΒώδΗίΡΙΎ╝ΝύΦρόρκίηΜϋ┐δϋκΝϋχφύ╗ΔΎ╝ΝόψΦϋ╛ΔίφΡώδΗίΛιίΖξίΚΞίΡΟύγΕόΧΙόηεΎ╝ΝίοΓόηεόΧΙόηείΠαίξ╜Ύ╝ΝίΙβϋχνϊ╕║ϋψξύΚ╣ί╛ΒίφΡώδΗόεΚόΧΙΎ╝ΝίΡοίΙβϋχνϊ╕║όΩιόΧΙήΑΓ
EmbeddedΎ╝γί░ΗύΚ╣ί╛ΒώΑΚόΜσίΤΝόρκίηΜϋχφύ╗Δύ╗ΥίΡΙϋ╡╖όζξΎ╝ΝίοΓίερόΞθίν▒ίΘ╜όΧ░ϊ╕φίΛιίΖξL1 Norm Ύ╝ΝL2 NormήΑΓ
ϋχφύ╗ΔόρκίηΜ
ίχΝόΙΡύΚ╣ί╛ΒόΛ╜ίΠΨίΤΝίνΕύΡΗίΡΟΎ╝Νί░▒ίΠψϊ╗ξί╝ΑίπΜόρκίηΜϋχφύ╗Δϊ║ΗΎ╝Νϊ╕ΜόΨΘϊ╗ξύχΑίΞΧϊ╕Φί╕╕ύΦρύγΕLogistic RegressionόρκίηΜΎ╝Ιϊ╕Μύπ░LRόρκίηΜΎ╝Κϊ╕║ϊ╛ΜΎ╝Νϋ┐δϋκΝύχΑίΞΧϊ╗Μύ╗ΞήΑΓ
ϋχ╛όεΚmϊ╕ςΎ╝Ιx,yΎ╝Κϋχφύ╗ΔόΧ░όΞχΎ╝ΝίΖ╢ϊ╕φxϊ╕║ύΚ╣ί╛ΒίΡΣώΘΠΎ╝Νyϊ╕║labelΎ╝ΝΎ╝δwϊ╕║όρκίηΜϊ╕φίΠΓόΧ░ίΡΣώΘΠΎ╝ΝίΞ│όρκίηΜϋχφύ╗Δϊ╕φώεΑϋοΒίφοϊ╣ιύγΕίψ╣ϋ▒κήΑΓ
όΚΑϋ░Υϋχφύ╗ΔόρκίηΜΎ╝Νί░▒όαψώΑΚίχγίΒΘϋψ┤ίΘ╜όΧ░ίΤΝόΞθίν▒ίΘ╜όΧ░Ύ╝Νίθ║ϊ║Οί╖▓όεΚϋχφύ╗ΔόΧ░όΞχΎ╝Ιx,yΎ╝ΚΎ╝Νϊ╕ΞόΨφϋ░ΔόΧ┤wΎ╝Νϊ╜┐ί╛ΩόΞθίν▒ίΘ╜όΧ░όεΑϊ╝αΎ╝Νύδ╕ί║ΦύγΕwί░▒όαψόεΑύ╗Ιίφοϊ╣ιύ╗ΥόηεΎ╝Νϊ╣θί░▒ί╛ΩίΙ░ύδ╕ί║ΦύγΕόρκίηΜήΑΓ
όρκίηΜίΘ╜όΧ░ 1Ύ╝ΚίΒΘϋψ┤ίΘ╜όΧ░Ύ╝ΝίΞ│ίΒΘϋχ╛xίΤΝyίφαίερϊ╕ΑύπΞίΘ╜όΧ░ίΖ│ύ│╗Ύ╝γ
2Ύ╝ΚόΞθίν▒ίΘ╜όΧ░Ύ╝Νίθ║ϊ║Οϊ╕Λϋ┐░ίΒΘϋχ╛ίΘ╜όΧ░Ύ╝ΝόηΕί╗║όρκίηΜόΞθίν▒ίΘ╜όΧ░Ύ╝Ιϊ╝αίΝΨύδχόιΘΎ╝ΚΎ╝ΝίερLRϊ╕φώΑγί╕╕ϊ╗ξΎ╝Ιx,yΎ╝ΚύγΕόεΑίνπϊ╝╝ύΕ╢ϊ╝░ϋχκϊ╕║ύδχόιΘΎ╝γ
ϊ╝αίΝΨύχΩό│Χ
όλψί║οϊ╕ΜώβΞΎ╝ΙGradient DescentΎ╝Κ
ίΞ│wό▓┐ύζΑόΞθίν▒ίΘ╜όΧ░ύγΕϋ┤θόλψί║οόΨ╣ίΡΣϋ┐δϋκΝϋ░ΔόΧ┤Ύ╝Νύν║όΕΠίδ╛ϋπΒϊ╕Μίδ╛Ύ╝Ν
ύγΕόλψί║οίΞ│ϊ╕Αώα╢ίψ╝όΧ░Ύ╝ΙϋπΒϊ╕Μί╝ΠΎ╝ΚΎ╝Νόλψί║οϊ╕ΜώβΞόεΚίνγύπΞύ▒╗ίηΜΎ╝ΝίοΓώγΠόε║όλψί║οϊ╕ΜώβΞόΙΨόΚ╣ώΘΠόλψί║οϊ╕ΜώβΞήΑΓ
ώγΠόε║όλψί║οϊ╕ΜώβΞΎ╝ΙStochastic Gradient DescentΎ╝ΚΎ╝ΝόψΠϊ╕ΑόφξώγΠόε║ώΑΚόΜσϊ╕Αϊ╕ςόι╖όευ
Ύ╝ΝϋχκύχΩύδ╕ί║ΦύγΕόλψί║οΎ╝Νί╣╢ίχΝόΙΡwύγΕόδ┤όΨ░Ύ╝ΝίοΓϊ╕Μί╝ΠΎ╝Ν
όΚ╣ώΘΠόλψί║οϊ╕ΜώβΞΎ╝ΙBatch Gradient DescentΎ╝Κ,όψΠϊ╕ΑόφξώΔ╜ϋχκύχΩϋχφύ╗ΔόΧ░όΞχϊ╕φύγΕόΚΑόεΚόι╖όευίψ╣ί║ΦύγΕόλψί║οΎ╝Νwό▓┐ύζΑϋ┐βϊ╕ςόλψί║οόΨ╣ίΡΣϋ┐φϊ╗μΎ╝ΝίΞ│

ύΚδώκ┐ό│ΧΎ╝ΙNewton’s MethodΎ╝Κ
ύΚδώκ┐ό│ΧύγΕίθ║όευόΑζόΔ│όαψίερόηΒί░ΠύΓ╣ώβΕϋ┐ΣώΑγϋ┐Θίψ╣ύδχόιΘίΘ╜όΧ░ίΒγϊ║Νώα╢Taylorί▒Χί╝ΑΎ╝Νϋ┐δϋΑΝόΚ╛ίΙ░L(w)ύγΕόηΒί░ΠύΓ╣ύγΕϊ╝░ϋχκίΑ╝ήΑΓί╜λϋ▒κίε░ϋχ▓Ύ╝ΝίερwkίνΕίΒγίΙΘύ║┐Ύ╝ΝϋψξίΙΘύ║┐ϊ╕ΟL(w)=0ύγΕϊ║νύΓ╣ίΞ│ϊ╕║ϊ╕Μϊ╕Αϊ╕ςϋ┐φϊ╗μύΓ╣wk+1Ύ╝Ιύν║όΕΠίδ╛ίοΓϊ╕ΜΎ╝ΚήΑΓwύγΕόδ┤όΨ░ίΖυί╝ΠίοΓϊ╕ΜΎ╝ΝίΖ╢ϊ╕φύδχόιΘίΘ╜όΧ░ύγΕϊ║Νώα╢ίΒΠίψ╝όΧ░Ύ╝ΝίΞ│ϊ╕║ίνπίΡΞώ╝Οώ╝ΟύγΕHessianύθσώα╡ήΑΓ
όΜθύΚδώκ┐ό│ΧΎ╝ΙQuasi-Newton MethodsΎ╝ΚΎ╝γϋχκύχΩύδχόιΘίΘ╜όΧ░ύγΕϊ║Νώα╢ίΒΠίψ╝όΧ░Ύ╝Νώγ╛ί║οϋ╛ΔίνπΎ╝Νόδ┤ϊ╕║ίνΞόζΓύγΕόαψύδχόιΘίΘ╜όΧ░ύγΕHessianύθσώα╡όΩιό│Χϊ┐ζόΝΒόφμίχγΎ╝δϊ╕ΞύΦρϊ║Νώα╢ίΒΠίψ╝όΧ░ϋΑΝόηΕώΑιίΘ║ίΠψϊ╗ξϋ┐Σϊ╝╝Hessianύθσώα╡ύγΕώΑΗύγΕόφμίχγίψ╣ύπ░ώα╡Ύ╝Νϊ╗ΟϋΑΝίερ"όΜθύΚδώκ┐"ύγΕόζκϊ╗╢ϊ╕Μϊ╝αίΝΨύδχόιΘίΘ╜όΧ░ήΑΓ
BFGSΎ╝γ ϊ╜┐ύΦρBFGSίΖυί╝Πίψ╣H(w)ϋ┐δϋκΝϋ┐Σϊ╝╝Ύ╝ΝίΗΖίφαϊ╕φώεΑϋοΒόΦ╛H(w),ίΗΖίφαώεΑϋοΒO(m2)ύ║πίΙτΎ╝δ
L-BFGSΎ╝γίφαίΓρόεΚώβΡόυκόΧ░Ύ╝ΙίοΓkόυκΎ╝ΚύγΕόδ┤όΨ░ύθσώα╡
Ύ╝ΝύΦρϋ┐βϊ║δόδ┤όΨ░ύθσώα╡ύΦθόΙΡόΨ░ύγΕH(w),ίΗΖίφαώβΞϋΘ│O(m)ύ║πίΙτΎ╝δ
OWLQN: ίοΓόηείερύδχόιΘίΘ╜όΧ░ϊ╕φί╝ΧίΖξL1όφμίΙβίΝΨΎ╝ΝώεΑϋοΒί╝ΧίΖξϋβγόλψί║οόζξϋπμίΗ│ύδχόιΘίΘ╜όΧ░ϊ╕ΞίΠψίψ╝ώΩχώλαΎ╝ΝOWLQNί░▒όαψύΦρόζξϋπμίΗ│ϋ┐βϊ╕ςώΩχώλαήΑΓ
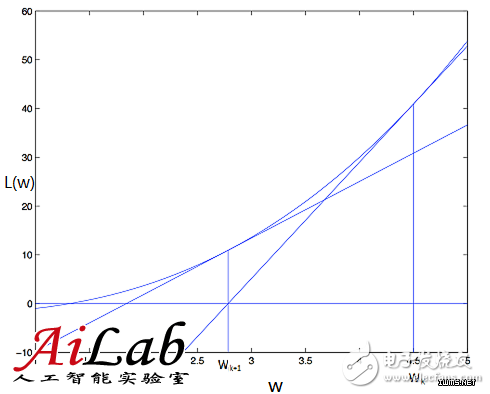
Coordinate Descent
ίψ╣ϊ║ΟwΎ╝ΝόψΠόυκϋ┐φϊ╗μΎ╝Νίδ║ίχγίΖ╢ϊ╗Ψύ╗┤ί║οϊ╕ΞίΠαΎ╝ΝίΠςίψ╣ίΖ╢ϊ╕Αϊ╕ςύ╗┤ί║οϋ┐δϋκΝόΡεύ┤λΎ╝ΝύκχίχγόεΑϊ╝αϊ╕ΜώβΞόΨ╣ίΡΣΎ╝Ιύν║όΕΠίδ╛ίοΓϊ╕ΜΎ╝ΚΎ╝ΝίΖυί╝Πϋκρϋ╛╛ίοΓϊ╕ΜΎ╝γ
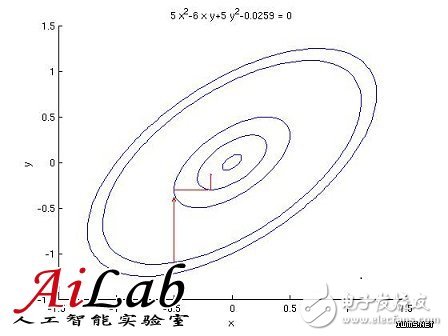
ϊ╝αίΝΨόρκίηΜ
ύ╗Πϋ┐Θϊ╕ΛόΨΘόΠΡίΙ░ύγΕόΧ░όΞχύφδώΑΚίΤΝό╕Ζό┤ΩήΑΒύΚ╣ί╛Βϋχ╛ϋχκίΤΝώΑΚόΜσήΑΒόρκίηΜϋχφύ╗ΔΎ╝Νί░▒ί╛ΩίΙ░ϊ║Ηϊ╕Αϊ╕ςόρκίηΜΎ╝Νϊ╜ΗόαψίοΓόηείΠΣύΟ░όΧΙόηεϊ╕Ξίξ╜Ύ╝θόΑΟϊ╣ΙίΛηΎ╝θ
ήΑΡώοΨίΖΙήΑΣ
ίΠΞόΑζύδχόιΘόαψίΡοίΠψώλΕϊ╝░Ύ╝ΝόΧ░όΞχίΤΝύΚ╣ί╛ΒόαψίΡοίφαίερbugήΑΓ
ήΑΡύΕ╢ίΡΟήΑΣ
ίΙΗόηΡϊ╕Αϊ╕ΜόρκίηΜόαψOverfittingϋ┐αόαψUnderfittingΎ╝Νϊ╗ΟόΧ░όΞχήΑΒύΚ╣ί╛ΒίΤΝόρκίηΜύφΚύΟψϋΛΓίΒγώΤΙίψ╣όΑπϊ╝αίΝΨήΑΓ
Underfitting & Overfitting
όΚΑϋ░ΥUnderfittingΎ╝ΝίΞ│όρκίηΜό▓κόεΚίφοίΙ░όΧ░όΞχίΗΖίερίΖ│ύ│╗Ύ╝ΝίοΓϊ╕Μίδ╛ί╖οϊ╕ΑόΚΑύν║Ύ╝Νϊ║πύΦθίΙΗύ▒╗ώζλϊ╕ΞϋΔ╜ί╛Ιίξ╜ύγΕίΝ║ίΙΗXίΤΝOϊ╕νύ▒╗όΧ░όΞχΎ╝δϊ║πύΦθύγΕό╖▒ί▒ΓίΟθίδιΎ╝Νί░▒όαψόρκ ίηΜίΒΘϋχ╛ύσ║ώΩ┤ίνςί░ΠόΙΨϋΑΖόρκίηΜίΒΘϋχ╛ύσ║ώΩ┤ίΒΠύο╗ήΑΓόΚΑϋ░ΥOverfittingΎ╝ΝίΞ│όρκίηΜϋ┐Θό╕κόΜθίΡΙϊ║Ηϋχφύ╗ΔόΧ░όΞχύγΕίΗΖίερίΖ│ύ│╗Ύ╝ΝίοΓϊ╕Μίδ╛ίΠ│ϊ╕ΑόΚΑύν║Ύ╝Νϊ║πύΦθίΙΗύ▒╗ώζλϋ┐Θίξ╜ίε░ίΝ║ίΙΗXίΤΝOϊ╕ν ύ▒╗όΧ░όΞχΎ╝ΝϋΑΝύεθίχηίΙΗύ▒╗ώζλίΠψϋΔ╜ί╣╢ϊ╕Ξόαψϋ┐βόι╖Ύ╝Νϊ╗ξϋΘ│ϊ║Οίερώζηϋχφύ╗ΔόΧ░όΞχϊ╕ΛϋκρύΟ░ϊ╕Ξίξ╜Ύ╝δϊ║πύΦθύγΕό╖▒ί▒ΓίΟθίδιΎ╝Νόαψί╖ρίνπύγΕόρκίηΜίΒΘϋχ╛ύσ║ώΩ┤ϊ╕ΟύρΑύΨΠύγΕόΧ░όΞχϊ╣ΜώΩ┤ύγΕύθδύδ╛ήΑΓ
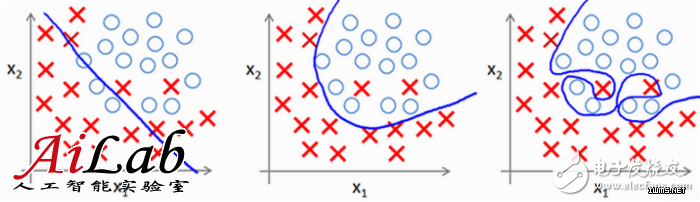
ίερίχηόΙαϊ╕φΎ╝ΝίΠψϊ╗ξίθ║ϊ║ΟόρκίηΜίερϋχφύ╗ΔώδΗίΤΝό╡ΜϋψΧώδΗϊ╕ΛύγΕϋκρύΟ░όζξύκχίχγί╜ΥίΚΞόρκίηΜίΙ░ί║ΧόαψUnderfittingϋ┐αόαψOverfittingΎ╝ΝίΙνόΨφόΨ╣ί╝ΠίοΓϊ╕ΜϋκρΎ╝γ
ϋχφύ╗ΔώδΗϋκρύΟ░ό╡ΜϋψΧώδΗϋκρύΟ░ώΩχώλα
< όεθόεδύδχόιΘίΑ╝ < όεθόεδύδχόιΘίΑ╝ Underfitting
> όεθόεδύδχόιΘίΑ╝ όΟξϋ┐ΣόΙΨύΧξώΑΛϊ║Οϋχφύ╗ΔώδΗ ίΡΙώΑΓ
> όεθόεδύδχόιΘίΑ╝ ϋ┐εί╖χϊ║Οϋχφύ╗ΔώδΗ Overfitting
όΑΟϊ╣ΙϋπμίΗ│UnderfittingίΤΝOverfittingώΩχώλαΎ╝θώΩχώλαόΧ░όΞχύΚ╣ί╛ΒόρκίηΜ
Underfitting ό╕Ζό┤ΩόΧ░όΞχ 1. ίληίΛιύΚ╣ί╛Β2. ίΙιώβνίβςώθ│ύΚ╣ί╛Β 1. ϋ░Δϊ╜ΟόφμίΙβώκ╣ύγΕόΔσύ╜γίΠΓόΧ░
2. όΞλόδ┤“ίνΞόζΓ”ύγΕόρκίηΜΎ╝ΙίοΓόΛΛύ║┐όΑπόρκίηΜόΞλϊ╕║ώζηύ║┐όΑπόρκίηΜΎ╝Κ
3. ίνγϊ╕ςόρκίηΜύ║πϋΒΦόΙΨύ╗ΕίΡΙ
Overfitting ίληίΛιόΧ░όΞχ 1. ϋ┐δϋκΝύΚ╣ί╛ΒώΑΚόΜσ
2. ώβΞύ╗┤Ύ╝ΙίοΓίψ╣ύΚ╣ί╛Βϋ┐δϋκΝϋΒγύ▒╗ήΑΒϊ╕╗ώλαόρκίηΜϋ┐δϋκΝίνΕύΡΗύφΚΎ╝Κ 1. όΠΡώταόφμίΙβώκ╣ύγΕόΔσύ╜γίΠΓόΧ░
2. ίΘΠί░Σϋχφύ╗Δϋ┐φϊ╗μόυκόΧ░
3. όΞλόδ┤“ύχΑίΞΧ”ύγΕόρκίηΜΎ╝ΙίοΓόΛΛώζηύ║┐όΑπόρκίηΜόΞλϊ╕║ύ║┐όΑπόρκίηΜΎ╝Κ
όΑ╗ύ╗Υ
ύ╗╝ϊ╕ΛόΚΑϋ┐░Ύ╝Νόε║ίβρίφοϊ╣ιϋπμίΗ│ώΩχώλαό╢ΚίΠΛίΙ░ώΩχώλαί╗║όρκήΑΒίΘΗίνΘϋχφύ╗ΔόΧ░όΞχήΑΒόΛ╜ίΠΨύΚ╣ί╛ΒήΑΒϋχφύ╗ΔόρκίηΜίΤΝϊ╝αίΝΨόρκίηΜύφΚίΖ│ώΦχύΟψϋΛΓΎ╝ΝόεΚίοΓϊ╕ΜϋοΒύΓ╣Ύ╝γ
ύΡΗϋπμϊ╕γίΛκΎ╝ΝίΙΗϋπμϊ╕γίΛκύδχόιΘΎ╝ΝϋπΕίΙΤόρκίηΜίΠψώλΕϊ╝░ύγΕϋ╖ψύ║┐ίδ╛ήΑΓ
όΧ░όΞχΎ╝γ
yόΧ░όΞχί░╜ίΠψϋΔ╜ύεθίχηίχλϋπΓΎ╝δ
ϋχφύ╗ΔώδΗ/ό╡ΜϋψΧώδΗίΙΗί╕Δϊ╕Ού║┐ϊ╕Λί║ΦύΦρύΟψίλΔύγΕόΧ░όΞχίΙΗί╕Δί░╜ίΠψϋΔ╜ϊ╕ΑϋΘ┤ήΑΓ
ύΚ╣ί╛ΒΎ╝γ
ίΙσύΦρDomain Knowledgeϋ┐δϋκΝύΚ╣ί╛ΒόΛ╜ίΠΨίΤΝώΑΚόΜσΎ╝δ
ώΤΙίψ╣ϊ╕ΞίΡΝύ▒╗ίηΜύγΕόρκίηΜϋχ╛ϋχκϊ╕ΞίΡΝύγΕύΚ╣ί╛ΒήΑΓ
όρκίηΜΎ╝γ
ώΤΙίψ╣ϊ╕ΞίΡΝϊ╕γίΛκύδχόιΘήΑΒϊ╕ΞίΡΝόΧ░όΞχίΤΝύΚ╣ί╛ΒΎ╝ΝώΑΚόΜσϊ╕ΞίΡΝύγΕόρκίηΜΎ╝δ
ίοΓόηεόρκίηΜϊ╕ΞύυοίΡΙώλΕόεθΎ╝Νϊ╕ΑίχγόμΑόθξϊ╕Αϊ╕ΜόΧ░όΞχήΑΒύΚ╣ί╛ΒήΑΒόρκίηΜύφΚίνΕύΡΗύΟψϋΛΓόαψίΡοόεΚbugΎ╝δ
ϋΑΔϋβΣόρκίηΜUnderfittingίΤΝQverfittingΎ╝ΝώΤΙίψ╣όΑπίε░ϊ╝αίΝΨήΑΓ
- ύδ╕ίΖ│όΟρϋΞΡ
- ύΔφύΓ╣όΟρϋΞΡ
- ό
-
ϊ╗Αϊ╣Ιόαψόε║ίβρίφοϊ╣ιΎ╝θώΑγϋ┐Θόε║ίβρίφοϊ╣ιόΨ╣ό│ΧϋΔ╜ϋπμίΗ│ίΥςϊ║δώΩχώλαΎ╝θ2024-11-16 1906
-
όε║ίβρίφοϊ╣ιίΤΝό╖▒ί║οίφοϊ╣ιύγΕίΝ║ίΙτ2023-08-17 5804
-
όε║ίβρίφοϊ╣ιϊ╣ΜίΙΗύ▒╗ίΙΗόηΡϊ╕ΟϋΒγύ▒╗ίΙΗόηΡ2023-03-27 6950
-
όε║ίβρίφοϊ╣ιϊ╣ΜίΖ│ϋΒΦίΙΗόηΡϊ╗Μύ╗Ξ2023-03-25 2910
-
ϊ╗Αϊ╣Ιόαψόε║ίβρίφοϊ╣ι? όε║ίβρίφοϊ╣ιίθ║ύκΑίΖξώΩρ2022-06-21 3035
-
όε║ίβρίφοϊ╣ιύγΕίθ║ύκΑίΗΖίχ╣ό▒ΘόΑ╗2022-02-28 1662
-
όε║ίβρίφοϊ╣ιύγΕίθ║ύκΑίΗΖίχ╣ϊ╗Μύ╗Ξ2022-01-12 1493
-
ίψ╣όε║ίβρίφοϊ╣ιίν▒ϋ┤ξύγΕίΟθίδιύγΕίΙΗόηΡϊ╕ΟϋπμίΗ│όΨ╣όκΙ2021-03-08 2818
-
ϊ╗Αϊ╣Ιόαψό╖▒ί║οίφοϊ╣ιΎ╝Νό╖▒ί║οίφοϊ╣ιϋΔ╜ϋπμίΗ│ϊ╗Αϊ╣ΙώΩχώλα2020-11-05 5483
-
όΟρϋΞΡίΘιόευόε║ίβρίφοϊ╣ιίΤΝό╖▒ί║οίφοϊ╣ιί┐Ζϋψ╗ϊ╣ού▒Ξ+όε║ίβρίφοϊ╣ιίχηόΙαϋπΗώλΣPPT+ίνπόΧ░όΞχίΙΗόηΡϊ╣ού▒Ξ2019-07-22 2503
-
ήΑΡϊ╕Μϋ╜╜ήΑΣήΑΛόε║ίβρίφοϊ╣ιήΑΜ+ήΑΛόε║ίβρίφοϊ╣ιίχηόΙαήΑΜ2017-06-01 198058
ίΖρώΔρ0όζκϋψΕϋχ║

ί┐τόζξίΠΣϋκρϊ╕Αϊ╕Μϊ╜ιύγΕϋψΕϋχ║ίΡπ !
