

消息总线和消息队列的区别是什么?
接口/总线/驱动
描述
谈谈消息总线跟消息队列的区别,以及对于企业级应用需要将消息队列封装成消息总线的必要性。
消息总线跟消息队列有何区别?如果有人问你这个问题,你的答案是什么?如果你的消息总线是基于一个已经相当成熟的消息队列或者消息系统做二次封装。为什么需要用你的客户端,而不直接用原始的(这是一个大家都相信权威的时代,请注意这里用的是相信,而不是迷信,你确实应该相信权威,至少比相信一个新手来得靠谱,当然我这里指的权威,是正面的意思)?
那么我从以下几点来谈谈我对这个问题的思考:
消息队列clientAPI权限太大,clientAPI信任级别太高
消息队列clientAPI面向技术,消息总线clientAPI面向技术+业务
消息队列无法隐藏通信细节
消息队列无法实施实时管控
总线的优势:统一入口,简化拦截成本
这里为了理解简单,你就暂且先把RabbitMQ当做是个消息队列,其实它不只是个消息队列,其他的一些基于JMS的消息队列对于回答这个问题而言,也能成立。
(1)消息队列clientAPI权限太大,信任级别太高
这一点不仅仅是哪一个服务端组件的客户端driver的实现是这样,绝大部分其实都是这样的,它们的client其实是对服务端组件(或者称之为服务器)协议的翻译。这些服务器大都带有commandline interface(这几乎是标配)。其实,CLI跟在程序中使用的各种语言的client库没有区别本质区别,它们相对于server而言都是client——都是对server实现的protocol的翻译或者转换,而这些API都是对这些包装过的协议的调用。因此它们都存在一些“management”形式的接口:比如create,delete,remove某个component之类的。没错,你去看所有带client的组件的实现,它们都包含了这些API(这不是对错的问题,这些client本身就没有也不应该假设你的使用场景)。比如你看看redis的client:jedis——它甚至具备了flushAll,flushDB的功能(清空所有redis数据),除了能关闭server还有什么事它不能做?而就RabbitMQ而言,它的officialnative java client,可以创建/删除其通信的核心组件:exchange,queue。你能直接将这些client散布到各个业务系统里去而不加阻拦?你当然有必要做二次封装以移除这些高危的managementAPI。
(2)消息队列clientAPI面向技术而消息总线clientAPI面向技术+业务
消息队列的clientAPI大都面向协议、通信实现,面向可用性以及高性能,如果归类一下那就是面向技术,除了通信场景它不会去模拟业务场景。而消息总线需要带着业务场景去实现需要支持的机制。
当你去搜索任何一个消息队列的时候,它的advantage里都有一条:生产者与消费者解耦,就像下面这样:
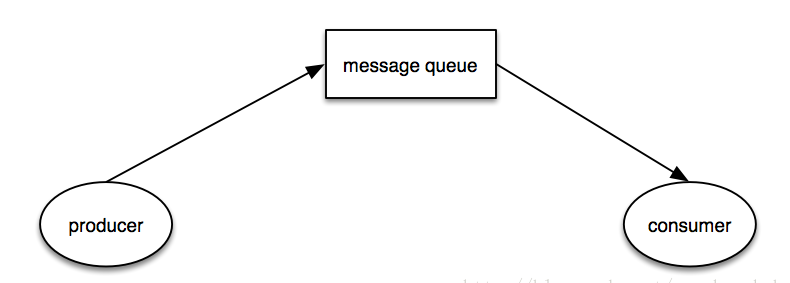
就生产者跟消费者模型而言,这确实是消息队列的优势。不过这种优势也被限制在一些特定的使用场景下,比如:单一业务的消息排队处理。因此通用消息队列的场景更适用于单一职责的生产者跟消费者模型;而我们期待的消息总线却是企业里各个系统中消息的通信,侧重点在于通信上。消息队列只是提供了一种非常适合于消息通信的实现机制(消息有序,消息缓存等),因此消息总线是在消息队列提供的技术支撑上封装出适合消息交互的业务场景。
(3)消息队列无法隐藏通信细节
对于企业内的系统交互,我们希望它尽可能保证数据的安全性。而数据通常都暂存在队列中,因此保证数据的安全性就顺其自然得转变成保证消息队列访问的安全性:你总是不应该让没有经过授权的客户端去访问本不应该访问到的队列。可惜的是RabbitMQ官方的客户端达不到这种要求,它要访问一个队列,需要知道真实队列的名称,需要知道其路由路径。而就连接一个队列而言,我们认为它提供了太多的信息,但这是没办法的事情,因为它的exchange以及queue的混搭机制非常灵活,所以你得提供一个称之为routingkey的路由路径。而不管怎样,如果你把这个信息开放给调用端去填写,几乎肯定会暴露你服务端exchange以及queue的路由机制以及拓扑结构。因此我们需要做什么?我们需要找到一种通信机制,让它对外只需要知道有个proxy节点,而不需要去关注真实的queue的名称;然后想一个办法把其routingkey隐藏在消息总线内部。
(4)消息队列无法实施实时管控
如果你在企业内各个系统之间引入消息总线,很显然访问控制是必须提供的。比如对某个队列实施消息大小限制,激活/禁用某个队列等。
之前我们提到过消息队列不是面向业务的,它自身没有过多得考虑数据的安全性以及对访问的安全控制机制。而且我们也几乎很难去改造一个消息队列的服务端实现,除非它是基于拦截器/插件模式的。即便RabbitMQ是支持插件的,但对于erlang这样一个受众不是特别广泛的语言,你去给它写插件一不小心就会走到坑里去,并且RabbitMQ官方也已经申明了它们十分不建议你自己去编写插件。考虑到诸多不便,我们只能在客户端上做文章。毫无疑问,我们的实时管控信息还是必须存储在服务端(只是它是一个独立的服务端),但原生的client很显然是不支持这种机制的,因此我们需要在原生client外部封装订阅实时管控信息以及实施访问控制的逻辑代码。
(5)总线的优势:统一入口,简化拦截成本
无论是消息总线还是服务总线,其实所谓的总线就是进行先收拢再发散的过程。先收拢,从统一的入口进去,完成必要的统一处理逻辑;再发散,按照路由规则,路由到各个组件去处理。事实上这就是代理的作用:屏蔽内部细节,对外统一入口。在基于代理的基础上,我们可以对消息总线上所有的消息做日志记录(因为所有消息的通信都必须经过代理),并且还是在不切断RabbitMQ自身Channel的基础上,而如果想在路由上实现一个Proxy,那基本上离不开一个树形拓扑结构。
写在最后
这篇主要谈了消息总线跟消息队列的区别。其实市面上已经有一些成熟的消息队列可以开箱即用,如果你针对消息队列来封装出一个消息总线,总有人会认为是否有这个必要性。如果没有这些开源的消息队列,那么完全有你自己来实现消息总线的话,你还是需要实现出一个跟市面上类似的MQ或者MessageBroker(见POSA卷4),因此消息队列只是实现消息总线的基础,或者是它的消息通信方式;而选择基于一些成熟的MessageBroker来进行开发,既能省去很多的工作量,又能享有它们提供的稳定性以及社区的贡献。
-
一文看懂PCI总线与PXI总线有什么区别2018-05-24 15475
-
全局变量和队列的区别在哪里?2018-03-28 7781
-
请问UCOS消息队列FIFO与LIFO有什么区别?2019-10-16 2679
-
GPU和CPU的区别是什么2021-01-05 2903
-
单片机和嵌入式的区别是什么2021-03-11 1927
-
高速串行总线与并行总线的差别是什么?2021-05-12 1535
-
RS232与RS485的主要区别是什么2021-09-28 3018
-
rt-thread邮箱-队列区别是什么?2023-10-31 660
-
数据总线和地址总线区别是什么?作用分别是什么2017-11-16 62447
-
消防多线控制与总线控制的区别是什么2020-05-22 14604
-
cob光源和led的区别是什么2020-12-24 11391
-
LED和OLED的区别是什么2022-01-14 18760
-
简述Labview使用队列与栈的区别2022-01-19 1167
-
并行总线和串行总线的区别2023-12-07 6460
-
CAN FD与传统CAN的区别是什么2024-10-22 3004
全部0条评论

快来发表一下你的评论吧 !
