

在树莓派5上使用YOLO进行物体和动物识别-入门指南
描述
大家好,接下来会为大家开一个树莓派5和YOLO的专题。
内容包括四个部分:
在树莓派5上使用YOLO进行物体和动物识别-入门指南
在树莓派5上开启YOLO人体姿态估计识别之旅
YOLO物体检测在树莓派AI Hat+上 | 如何编写自定义Python代码
YOLO姿态估计在树莓派AI Hat+上 | 编写自定义Python代码
今天是第一部分:在树莓派5上使用YOLO进行物体和动物识别-入门指南
如果大家对这个专题有兴趣,记得关注树莓派开发者,这样你将会第一时间收到我们的内容更新通知。
你是否曾想涉足计算机视觉领域?比如在树莓派这样的低功耗便携式硬件上尝试如何?
在本指南中,我们将在树莓派5上配置YOLO视觉模型系列、OpenCV和COCO对象库。我们将探讨一些可用的不同YOLO模型,如何针对处理能力和速度优化它们,如何使用检测结果控制硬件,还将介绍YOLO World——一个非常令人兴奋的开放词汇模型,它能够根据提示而非预训练项目列表来检测对象。
如今,由于我们能够在树莓派等硬件上运行高性能视觉模型,计算机视觉变得比以往任何时候都更简单、高效。这得益于我们将在本指南中利用的出色开源项目:COCO库、OpenCV和YOLO。不过,在我们深入探讨这些之前,我们会经常提到它们,因此先通过一个简单的类比来解释它们的作用。
OpenCV就像我们计算机视觉“厨师”的厨房。它为我们准备了制作食物所需的工具和框架。YOLO则是厨房里的“厨师”。它是系统中实际工作、“思考”并尝试识别物体的部分。最后,我们有COCO库。这是YOLO附带的训练数据——就像YOLO要遵循的食谱或烹饪书。如果COCO库中有识别汽车的指令,那么YOLO这位“厨师”就能识别汽车;如果没有这些指令,YOLO就无法识别。因此,在OpenCV这个厨房里,YOLO这位“厨师”根据COCO库这本烹饪书来工作。
希望这个解释能让你明白,让我们开始吧!你可以选择观看视频演示
目录
所需物品
硬件组装
安装树莓派操作系统
设置虚拟环境并安装YOLO
运行YOLOv8
运行其他YOLO模型
提高处理速度(NCNN转换和分辨率)
控制硬件
深入了解YOLO World
后续方向
致谢
附录:使用网络摄像头
所需物品
要跟随本指南进行操作,你需要准备以下物品:
树莓派5 - 4GB或8GB型号均可。虽然理论上也可以在树莓派4上完成,但速度远慢于树莓派5,体验不佳,因此我们未在树莓派4上进行测试。
树莓派摄像头 - 我们使用的是摄像头模块V3
转接线 - 树莓派5配备的是不同尺寸的CSI摄像头线,而你的摄像头可能配备的是较旧的较粗线,因此请仔细检查。摄像头模块V3肯定需要转接线
散热方案 - 我们使用的是主动散热器(计算机视觉会让你的树莓派达到性能极限)
电源
Micro SD卡 - 容量至少为16GB
显示器和Micro-HDMI转HDMI线
鼠标和键盘
*所需物品可以直接联系我们进行购买。
硬件组装
硬件组装过程相对简单。将线缆较粗的一端连接到摄像头,较细的一端连接到树莓派5。这些连接器上有一个标签 - 将其抬起,然后将线缆插入插槽。确保线缆插入整齐后,将标签压回原位以固定线缆。

注意,这些连接器只能以一个方向插入,且较为脆弱,因此请避免过度弯曲(稍微弯曲一点没问题)。
安装树莓派操作系统
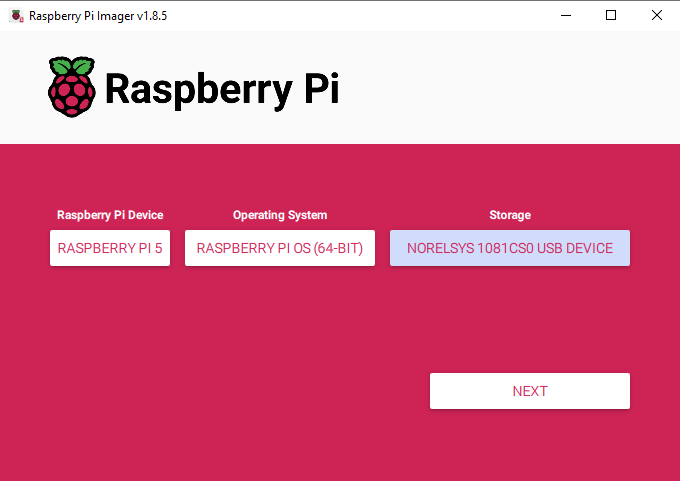
首先,我们需要将树莓派操作系统安装到Micro SD卡上。使用树莓派成像工具,选择树莓派5作为设备,树莓派操作系统(64位)作为操作系统,以及你的MicroSD卡作为存储设备。
下载树莓派操作系统:https://www.raspberrypi.com/software/
注意:将树莓派操作系统安装到MicroSD卡上会清除卡上的所有数据。
此过程可能需要几分钟时间来下载操作系统并安装。安装完成后,将其插入树莓派并启动。树莓派将进行首次安装设置,请确保将其连接到互联网。
你还需要记住在此创建的用户名,因为本指南中涉及的文件位置会用到它。为简单起见,你可以直接将其命名为“pi”。
设置虚拟环境并安装YOLO
随着2023年Bookworm操作系统的推出,我们现在需要使用虚拟环境(或venv)。虚拟环境是隔离的虚拟空间,我们可以在其中运行项目,而不会破坏树莓派操作系统的其余部分和软件包——换句话说,我们可以在这里随心所欲地操作,而不会损坏树莓派操作系统的其余部分。这是一个需要学习的额外部分,但非常简单。
要创建虚拟环境,请打开一个新的终端窗口并输入:
python3 -m venv --system-site-packages yolo_object
这将创建一个名为“yolo_object”的新虚拟环境。你可以在home/pi下找到此虚拟环境的文件夹,它将被称为“yolo_object”。
创建venv后,通过输入以下命令进入:
source yolo_object/bin/activate
执行上述操作后,你会在绿色文本的左侧看到虚拟环境的名称 - 这意味着我们正在其中正确工作。如果你需要重新进入此环境(例如,如果你关闭了终端窗口,你将退出环境),只需再次输入上述source命令即可。
现在,我们处于虚拟环境中,可以开始安装所需的软件包。首先,通过输入以下三行命令确保PIP(Python软件包管理器)是最新的:
sudo apt updatesudo apt install python3-pip -ypip install -U pip
然后,使用以下命令安装Ultralytics软件包:
pip install ultralytics[export]
Ultralytics的优秀团队是最新YOLO模型的主要开发者和维护者之一。他们的这个软件包将承担大部分繁重的工作,并安装OpenCV以及我们运行YOLO所需的所有基础设施。
此过程还将安装大量其他软件包,因此可能会失败。如果你的安装失败(会显示一大片红色文本),只需再次输入Ultralytics安装命令,它应该会继续。在极少数情况下,安装命令可能需要重复几次。
安装完成后,重启树莓派。如果你想成为高级用户,可以在shell中输入:
reboot
我们还有一件事要做,那就是设置Thonny以使用我们刚刚创建的虚拟环境。Thonny是我们将运行所有代码的程序,我们需要让它从同一个venv中运行,以便它可以访问我们安装的库。
首次打开Thonny时,它可能处于简化模式,你会在右上角看到“切换到常规模式”。如果存在此选项,请点击它并关闭Thonny以重新启动。
现在,通过选择“运行”>“配置解释器”进入解释器选项菜单。在“Python可执行文件”选项下,有一个带三个点的按钮。选择它并导航到我们刚刚创建的虚拟环境中的Python可执行文件。
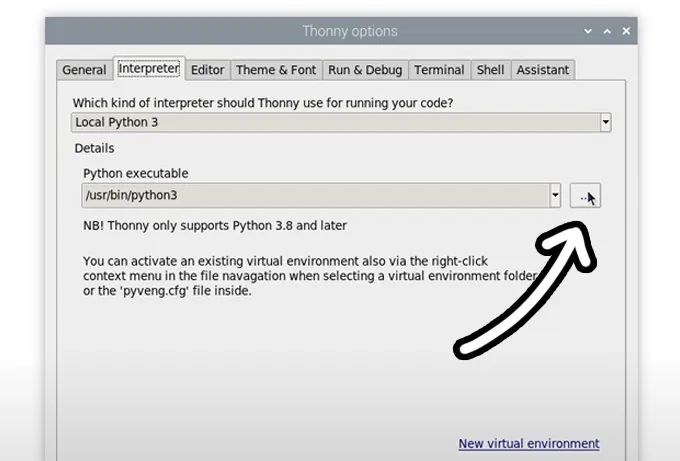
该文件位于home/pi/yolo_object/bin下,在此文件中,你需要选择名为“python3”的文件。点击确定,你现在将在此venv中工作。
无论何时打开Thonny,它都将自动在此环境中运行。你可以通过从同一解释器选项菜单中“Python可执行文件”下的下拉菜单中选择它来更改工作环境。如果你想退出虚拟环境,请选择bin/python3选项。

运行YOLOv8
在Thonny中创建一个新脚本,并粘贴以下代码:
import cv2from picamera2 import Picamera2from ultralytics import YOLO# Set up the camera with Picampicam2 = Picamera2()picam2.preview_configuration.main.size = (1280, 1280)picam2.preview_configuration.main.format = "RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load YOLOv8model = YOLO("yolov8n.pt")while True: # Capture a frame from the camera frame = picam2.capture_array() # Run YOLO model on the captured frame and store the results results = model(frame) # Output the visual detection data, we will draw this on our camera preview window annotated_frame = results[0].plot() # Get inference time inference_time = results[0].speed['inference'] fps = 1000 / inference_time # Convert to milliseconds text = f'FPS: {fps:.1f}' # Define font and position font = cv2.FONT_HERSHEY_SIMPLEX text_size = cv2.getTextSize(text, font, 1, 2)[0] text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right text_y = text_size[1] + 10 # 10 pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Exit the program if q is pressed if cv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
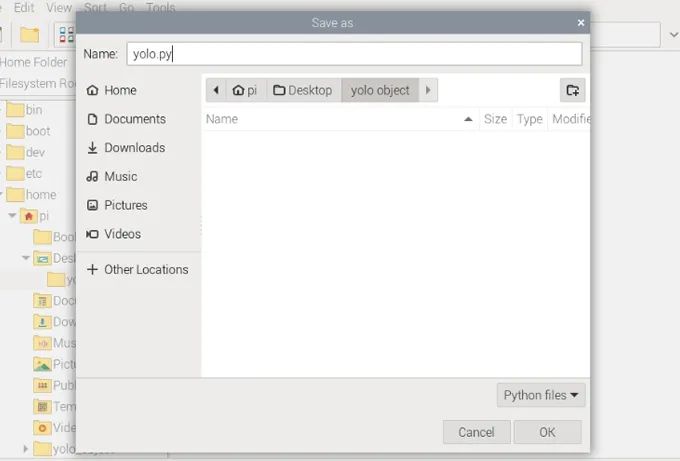
运行YOLO代码通常涉及下载模型,这些模型将保存到脚本所在的位置,因此,创建一个文件夹并将脚本保存在其中以保持整洁可能是个明智的选择。我们只是在桌面上创建了一个文件夹并将所有内容保存到了那里。保存YOLO代码时,请确保将其保存为“.py”Python文件。
现在,点击绿色播放按钮运行代码,下载模型后,应该会弹出一个窗口显示摄像头画面以及YOLO检测到的任何物体。
它会自动在检测到的物体周围绘制一个框,标注物体名称,并给出检测置信度评分(1.0为最高)。
这就是我们基础级别的YOLO模型在工作!虽然现在的FPS可能不高(约为1.5 FPS),但我们很快将探讨如何改进。
要停止此脚本,只需按下Q键。

让我们快速了解一下这段代码的工作原理,以便我们大致了解其内部机制。
首先,我们导入所需的库;cv2是OpenCV,Picamera2是我们用来将摄像头的视频流导入代码的库,Ultralytics是我们的YOLO模型来源。
import cv2from picamera2 import Picamera2from ultralytics import YOLO
然后,我们通过使用Picamera2初始化摄像头并加载YOLOv8模型来结束设置阶段。
# Set up the camera with Picampicam2 = Picamera2()picam2.preview_configuration.main.size = (1280, 1280)picam2.preview_configuration.main.format = "RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load YOLOv8model = YOLO("yolov8n.pt")
接下来,我们进入一个循环的While True循环,该循环从摄像头获取图像,将其输入到YOLOv8模型中,然后获取模型输出的数据。
while True: # Capture a frame from the camera frame = picam2.capture_array() # Run YOLO model on the captured frame and store the results results = model(frame) # Output the visual detection data, we will draw this on our camera preview window annotated_frame = results[0].plot()
接下来的这段代码是一些计算我们正在处理的FPS的数学运算,然后是一些OpenCV相关的代码,用于将FPS附加到模型的输出数据上。
# Get inference timeinference_time = results[0].speed['inference']fps = 1000 / inference_time # Convert to millisecondstext = f'FPS: {fps:.1f}'
# Define font and positionfont = cv2.FONT_HERSHEY_SIMPLEXtext_size = cv2.getTextSize(text, font, 1, 2)[0]text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the righttext_y = text_size[1] + 10 # 10 pixels from the top
# Draw the text on the annotated framecv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
然后,我们最终在摄像头画面窗口上叠加输出数据和FPS计数器。
# Display the resulting framecv2.imshow("Camera", annotated_frame)
最后,我们通过按下“q”键退出。如果按下该键,则脚本将跳出当前的while True循环并关闭所有窗口。
# Exit the program if q is pressed if cv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
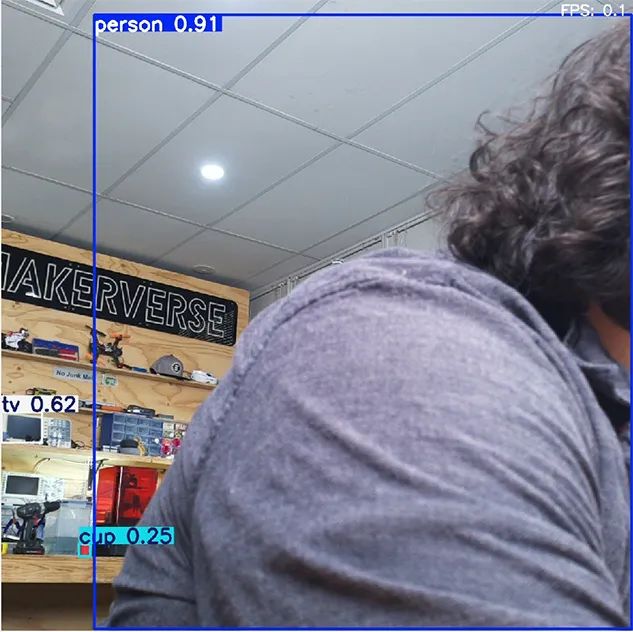
在继续改进YOLO之前,有一个限制值得指出。现在,你的树莓派可能能够检测到坐在它前面的人,以及椅子、电视和杯子等常见物品。然而,它无法检测到所有物品。在右侧的图片中,有许多物品未被检测到,这是由于COCO库的限制。

YOLOv8是在COCO库上进行训练的,该库将对象分类为大约88个不同的类别——这意味着你只能检测到88种不同类型的物品。这听起来可能不多,但当你考虑到其中一些类别非常常见且广泛,如“汽车”或“运动球”时,它能检测到的物品就相当多了。然而,如果某个对象不是其训练库的一部分(如眼镜),它将无法识别。这预示着YOLO World将让我们克服这一限制。
运行其他YOLO模型
到目前为止,我们一直在运行YOLOv8,而这个ultralytics软件包的美妙之处在于,我们只需在代码中替换一行即可完全更改模型,我们可以使用它来运行更高级的v8模型,甚至是旧模型。你只需要更改设置中的这一行:
# Load YOLOv8model = YOLO("yolov8n.pt")
此行当前使用的是nano模型,它是YOLOv8中最小、功能最弱但速度最快的模型。我们可以通过更改“v8”后面的单个字母来更改此行以运行此模型的不同尺寸版本,如下所示。如果你更改此行并运行它,脚本将自动下载新模型(对于较大的模型,可能达到数百MB)。

正如你所猜到的,图像处理性能和FPS之间存在权衡。如果你运行超大模型,FPS应低于0.1(我们很快将改进这一点),但你也应该注意到检测性能有了显著提升。这些较大的模型更擅长识别远离摄像头的物品,如右侧图像所示,并且能够更可靠地以更高的准确度识别物体。如果你手里拿着一个杯子,nano模型可能会在识别为手机和杯子之间跳跃,但超大模型将更一致地识别为杯子。
在我们的厨房类比中,这就像告诉“厨师”(YOLOv8)应该花多长时间准备一道菜,nano是花费时间最少的,可能会产生一些粗糙的结果,而超大则是“不惜一切代价”的情况。
我们还可以使用这些尺寸之间的不同模型,它们在处理性能和FPS之间存在不同程度的权衡,因此你可以尝试一下,看看哪个既准确又足够快,满足你的需求。
我们可以更改的另一件事是模型版本。YOLO从v1开始,现在已经发展到v10(我们使用的是v8,因为在撰写本文时,它与v10一样快,并且可以针对树莓派进行更好的优化)。这些版本提高了模型的速度和功能,在我们的厨房类比中,就像使用更熟练和经验丰富的“厨师”。
更改此版本同样简单,例如,如果我们出于遗留原因想使用v5,我们只需将同一行修改为:
# Load YOLOv8model = YOLO("yolov5n.pt")
如果你想尝试v10,只需写:
# Load YOLOv8model = YOLO("yolov10n.pt")
本指南最终会过时,但如果在本指南发布后发布了v11或v12或其他版本,你很有可能只需简单地更改那一行即可使用最新模型运行此代码。
更新:在我们发布本指南的当天,Ultralytics发布了YOLO11。要使用新模型,只需将该行更改为以下内容。请注意,他们似乎已经放弃了“V”命名方案。
# Load our YOLO11 modelmodel = YOLO("yolo11n.pt")
提高处理速度
我们可以通过两种方法来提高树莓派上的FPS,而最有效的方法是将模型转换为称为NCNN的格式。这是一种更优化以在基于ARM的处理器(如树莓派的处理器)上运行的模型格式。打开名为“ncnn conversion.py”的脚本,你将找到以下内容:
from ultralytics import YOLO# Load a YOLOv8n PyTorch modelmodel = YOLO("yolov8n.pt")# Export the model to NCNN formatmodel.export(format="ncnn", imgsz=640) # creates 'yolov8n_ncnn_model'
要使用此脚本,首先指定你要转换的模型。这使用我们在上一节中讨论的相同命名约定。然后,指定模型格式“ncnn”作为输出格式以及分辨率。目前,请保持默认的640。首次运行此脚本时,它将下载更多所需的内容,但实际转换应该只需几秒钟。
完成后,在脚本所在的文件夹中,你将找到一个名为“yolov8n_ncnn_model”之类的新文件夹。复制此文件名并返回到我们之前的演示脚本。
现在,你需要通过将模型行更改为它刚刚创建的文件夹的名称来告诉脚本使用我们创建的模型。它应该如下所示:
# Load our YOLOv8 modelmodel = YOLO("yolov8n_ncnn_model")
如果你运行脚本,它应该与之前完全一样地工作,但由于NCNN转换,FPS提高了4倍。
我们可以做的另一件事来提高FPS是降低处理分辨率。这是我们将运行YOLO模型的分辨率,像素越少意味着处理每帧所需的时间越少。
虽然转换为NCNN是免费的FPS提升,但降低分辨率确实会牺牲一些能力。较低的分辨率会略微降低姿态估计的准确性(虽然不太明显),并且最大的影响是它会降低可以估计姿态的距离。默认分辨率为640时,范围相当远,因此我们可以适当降低一点。
为此,请打开我们刚刚使用的NCNN转换脚本并在以下行中指定你想要的分辨率:
# Export the model to NCNN formatmodel.export(format="ncnn", imgsz=320) # creates 'yolov8_ncnn_model'
注意:这必须是32的倍数。因此,你不能将其设置为300,但可以设置为320。
我们发现,160到320范围内的分辨率在性能和速度之间取得了良好的平衡。
运行转换代码,它将导出具有所需分辨率的模型。这样做也会覆盖任何之前导出的同名模型。
在演示脚本中,确保你像之前一样指定了NCNN模型。还有一件重要的事情我们必须做,那就是告诉脚本要向模型输入什么分辨率。在while true循环中,你将找到以下行。确保它与模型的分辨率匹配,对于此示例,我们导出的是320:
# Run YOLO model on the captured frame and store the results results = model.predict(frame, imgsz = 320)
如果一切顺利,你应该会看到FPS再次显著提高。根据需要调整此分辨率,但请记住:
它必须是32的倍数
你必须更改主脚本中的名称以使用导出的模型
你必须设置主脚本中的分辨率以匹配模型

控制硬件
现在,我们可以识别物体并根据需要优化此过程,但如何使用它呢?我们只有一个摄像头预览窗口,上面叠加了检测结果。
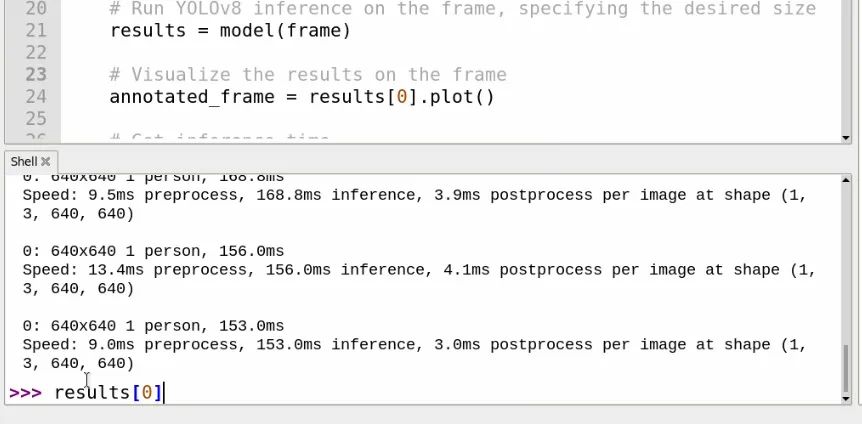
所有这些数据都是从results变量中检索的。如果你运行脚本几秒钟,然后按“q”停止它,以便在shell中显示几个条目(如右侧图像所示),你可以在shell中输入:
results[0]
你将能够看到检测结果的内部信息。“[0]”在末尾表示你正在获取最新分析帧的结果。如果你滚动查看此内容,应该能够看到一个名为names的部分,其中包含COCO库可以检测到的所有对象的名称以及与这些对象关联的ID(例如,人为0,自行车为1,汽车为2等)。如果你想手动获取此列表,可以输入:
results[0].names
在results[0]中,我们还可以获取屏幕上检测到的所有内容的列表。如果你输入:
results[0].boxes.cls
你将获得正在检测的对象的所有ID列表。在我右侧的示例中,我们只检测到了一个人,其ID为0。这将成为我们利用检测结果的主要方法。
使用这个“results[0].boxes.cls”,我们可以编写代码来使用树莓派控制硬件。以下是一些实现此功能的演示代码:
import cv2from picamera2 import Picamera2from ultralytics import YOLOfrom gpiozero import LED# Initialize the camerapicam2 = Picamera2()picam2.preview_configuration.main.size = (1280, 1280)picam2.preview_configuration.main.format = "RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# initialise output pinoutput = LED(14)# Load the YOLO modelmodel = YOLO("yolov8n.pt")# List of class IDs we want to detectobjects_to_detect = [0, 73] # You can modify this listwhile True: # Capture a frame from the camera frame = picam2.capture_array() # Run object detection on the frame results = model(frame, imgsz = 160) # Get the classes of detected objects detected_objects = results[0].boxes.cls.tolist() # Check if any of our specified objects are detected object_found = False for obj_id in objects_to_detect: if obj_id in detected_objects: object_found = True print(f"Detected object with ID {obj_id}!") # Control the Pin based on detection if object_found: output.on() # Turn on Pin print("Pin turned on!") else: output.off() # Turn off Pin print("Pi turned off!") # Display the frame with detection results annotated_frame = results[0].plot() cv2.imshow("Object Detection", annotated_frame) # Break the loop if 'q' is pressed if cv2.waitKey(1) == ord("q"): break# Clean upcv2.destroyAllWindows()
这段代码与我们之前的脚本类似,但有一些添加。首先,我们导入控制树莓派引脚所需的库,并使用以下行设置引脚14:
from gpiozero import LED# initialise output pinoutput = LED(14)
然后,我们定义要控制引脚的对象ID。如果其中任何一个出现,则引脚将打开。现在它有0 - 人和73 - 书。你可以将其更改为任何你想要的ID,或者通过简单地用逗号分隔添加另一个ID来添加更多:
# List of class IDs we want to detectobjects_to_detect = [0, 73] # You can modify this list
然后,我们获取检测到的对象列表,并查看上一行中指定的任何ID是否与当前帧中检测到的内容匹配:
# Get the classes of detected objects detected_objects = results[0].boxes.cls.tolist() # Check if any of our specified objects are detected object_found = False for obj_id in objects_to_detect: if obj_id in detected_objects: object_found = True print(f"Detected object with ID {obj_id}!")
最后,我们控制14号引脚,如果检测到物体,就将其打开或关闭:
# Control the Pin based on detection if object_found: output.on() # Turn on Pin print("Pin turned on!") else: output.off() # Turn off Pin print("Pi turned off!")
至此,我们就可以随心所欲地操作了。你可以像视频指南中那样控制电磁阀,也可以控制伺服电机或普通电机。
深入了解YOLO World
YOLO World是一个功能极其强大的物体识别模型,值得为其单独开辟一个章节来介绍。通常,模型都是基于训练数据库构建的。YOLOv8使用的COCO库经过训练可以识别猫,因此它能够识别猫。但它没有经过识别眼镜的训练,所以无论你多么清晰地将眼镜展示给摄像头,它都无法识别。要让YOLOv8识别眼镜,通常的方法是重新训练它,这涉及到一个漫长且处理密集的过程(对于我们的小树莓派来说负担过重),你需要给眼镜贴上标签并输入眼镜图像。只有经过整个过程,YOOLOv8才能检测到眼镜。
而YOLO World的卓越之处在于,它是一个开放词汇模型,这意味着你可以描述或提示它要寻找什么,它会尽力去找到它。所以,你只需告诉它寻找眼镜,正如你在右边图像中看到的,即使无需重新训练,它也能够检测到眼镜。
不过,这并不是一个能识别所有物体的神奇法宝,它仍然有一套有限的训练数据可供使用,但简而言之,它从整张图像中学习,而不仅仅是学习识别图像中的某一个物体。因此,如果某个物体是照片中常见的物体,比如相机、眼镜、笔、电池等,它很有可能能够检测到它们。对于不常见、不常被拍照的物体,比如算盘和盖革计数器,它可能就无法识别了。

此外,它在检测常见物体时也可能存在一些问题,例如,我们无法让它检测到画笔或钥匙。
要使用YOLO World,我们需要稍微修改一下脚本,以下是示例代码:
import cv2from picamera2 import Picamera2from ultralytics import YOLO# Set up the camera with Picampicam2 = Picamera2()picam2.preview_configuration.main.size = (1280, 1280)picam2.preview_configuration.main.format = "RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load our YOLOv8 modelmodel = YOLO("yolov8s-world.pt")# Define custom classesmodel.set_classes(["person", "glasses"])while True: # Capture a frame from the camera frame = picam2.capture_array() # Run YOLO model on the captured frame and store the results results = model(frame, imgsz = 640) # Output the visual detection data, we will draw this on our camera preview window annotated_frame = results[0].plot() # Get inference time inference_time = results[0].speed['inference'] fps = 1000 / inference_time # Convert to milliseconds text = f'FPS: {fps:.1f}' # Define font and position font = cv2.FONT_HERSHEY_SIMPLEX text_size = cv2.getTextSize(text, font, 1,2)[0] text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right text_y = text_size[1] + 10 # 10 pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Exit the program if q is pressed if cv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
注意:首次运行此脚本时,可能需要几分钟时间,因为YOLO World模型较大,并且需要下载额外的所需软件包,总计约400 Mb。
目前,此脚本正在查找“眼镜”和“人”这两个词,但我们可以通过修改这一行来立即更改查找内容。你所需要做的就是将你要查找的物体放在引号内,并用逗号分隔:
# Define custom classesmodel.set_classes(["person", "glasses", "yellow lego man head"])
在上面的这行代码中,我们使用了YOLO World的另一个很酷的功能,即通过描述而非单个单词来提示它。正如你在右边看到的,它正在检测我们的黄色乐高人偶头部。检测结果有点时灵时不灵,它可能更多地识别黄色,但这是一个很酷的示例,展示了YOLO World可以实现的功能。
不过,关于YOLO World,有几点需要注意。首先,它只会检测你在上面那行代码中指定的内容。如果列表中没有描述某个物体,它将无法识别。如果你删除整行代码,它会查找所有能查找的物体,行为更类似于YOLOv8。

YOLO World也只有三种尺寸——小、中和大。上面的示例脚本使用的是小尺寸,你可以通过将“s”替换为“m”或“l”来替换为中等或大型模型。如果你想要大型模型,可以这样写:
# Load our YOLOv8 modelmodel = YOLO("yolov8l-world.pt")
此外,YOLO World不能转换为NCNN格式。这有点遗憾,但我们至少仍然可以降低分辨率来提高性能。而且你可能需要这样做,因为它的运行速度会比默认的YOLOv8模型慢很多。
总而言之,在你的项目中尝试一下YOLO World吧。根据提示检测自定义物体或物体的功能提供了很大的灵活性和定制性。即便只是为了好玩,也值得一试。
后续方向?
至此,我们应该已经在树莓派上运行了YOLO物体检测,无论是YOLOv8、v5还是YOLO World。不过,本指南只是一个起点,我们希望你能够开始将计算机视觉添加到你的项目中。但最重要的是,我们希望你学到了新知识,并在这个过程中获得了乐趣。
如果你正在寻找一些扩展工作或探索方向,可以看看results变量内部,你可以找到很多很酷的东西,比如正在绘制的方框的xy坐标。很有可能从中找到被检测物体的中心,并连接伺服电机来跟踪该物体。
如果你希望长时间运行此系统,它将在MicroSD卡上进行大量读写操作,因此设置NVME SDD以提高耐用性可能是一个有益的举措。我们有一篇很棒的初学者指南,介绍了如何操作!
https://core-electronics.com.au/guides/how-to-add-an-ssd-to-your-raspberry-pi-5-with-the-m.2-hat/
如果你想深入了解YOLO,可以查看Ultralytics文档页面。他们有一系列其他很酷的模型可供探索,而且因为我们已经设置了使用其模型所需的基础架构,所以只需复制粘贴你在那里找到的演示代码即可!
https://docs.ultralytics.com/zh/
致谢
首先,我们要感谢OpenCV和COCO库的众多贡献者、开发者和维护者。现代计算机视觉领域的许多成果都建立在他们的努力之上。
我们还要感谢Joseph Redmon和Ultralytics开发并维护了这里使用的许多YOLO模型。这些模型功能强大,能够在树莓派等低功耗硬件上运行,这绝非易事!
附录:使用网络摄像头
本指南是基于使用插入CSI端口的树莓派摄像头模块编写的。不过,也可以使用USB网络摄像头。本指南中演示的代码应该能够直接与大多数网络摄像头配合使用,但存在一些问题。树莓派上的网络摄像头存在很大的变数(这就是我们在本指南中选择摄像头模块的原因),但常见的问题之一是色彩不匹配。如果网络摄像头画面中的颜色看起来混合或色调不正确,请尝试以下代码:
import cv2from picamera2 import Picamera2from ultralytics import YOLO# Initialize the Picamera2picam2 = Picamera2()picam2.preview_configuration.main.size = (1280, 1280)picam2.preview_configuration.main.format = "BGR888" # Change to BGR888picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load the YOLOv8 modelmodel = YOLO("yolov8s-worldv2.pt")model.set_classes(["spray bottle"])while True: # Capture frame-by-frame frame = picam2.capture_array() # Convert BGR to RGB frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # Run YOLOv8 inference on the frame, specifying the desired size results = model(frame_rgb, imgsz=320) # Visualize the results on the frame annotated_frame = results[0].plot() # Get inference time inference_time = results[0].speed['inference'] fps = 1000 / inference_time # Convert to milliseconds text = f'FPS: {fps:.1f}' # Define font and position font = cv2.FONT_HERSHEY_SIMPLEX text_size = cv2.getTextSize(text, font, 1, 2)[0] text_x = annotated_frame.shape[1] - text_size[0] - 10 # 10 pixels from the right text_y = text_size[1] + 10 # 10 pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Break the loop if 'q' is pressed if cv2.waitKey(1) == ord("q"): break# Close windowscv2.destroyAllWindows()
虽然不能保证这段代码一定有效,但对于大多数网络摄像头品牌来说应该是可行的。如果有效,你可以根据指南中的说明根据需要修改此代码。
原文地址:
https://core-electronics.com.au/guides/raspberry-pi/getting-started-with-yolo-object-and-animal-recognition-on-the-raspberry-pi/
-
「EDATEC」如何在树莓派4上安装64位操作系统2023-03-31 4272
-
完整指南:如何使用树莓派5、Hailo AI Hat、YOLO、Docker进行自定义数据集训练?2025-06-28 5219
-
树莓派5,Raspberry Pi 5 评测2024-06-19 13525
-
树莓派权威用户指南2014-07-01 117289
-
树莓派入门套装2016-02-22 14381
-
树莓派有什么用_树莓派能用来做啥_树莓派新手入门教程2018-05-08 35110
-
在树莓派上部署YOLOv5进行动物目标检测的完整流程2024-11-11 5540
-
树莓派分类器:用树莓派识别不同型号的树莓派!2025-06-13 1752
-
在树莓派5上开启YOLO姿态估计识别之旅!2025-07-18 2934
-
如何在树莓派 AI HAT+上进行YOLO目标检测?2025-07-19 2106
-
如何在树莓派 AI HAT+上进行YOLO姿态估计?2025-07-20 1391
-
这个套件让树莓派5运行几乎所有YOLO模型!Conda 与 Ultralytics!2025-07-31 6112
-
如何使用树莓派+OpenCV实现姿态估计和面部特征点追踪?2025-08-13 1628
-
如何使用树莓派与OpenCV实现面部和运动追踪的云台系统?2025-08-14 2933
-
零成本钢铁侠手套!树莓派+OpenCV 秒变手势遥控器!2025-08-16 1774
全部0条评论

快来发表一下你的评论吧 !
