

一种基于深度学习的系统教会机器人仅通过观察人类行为就能完成任务
描述
近日,NVIDIA研究团队率先开发出了一种基于深度学习的系统,该系统可教会机器人仅通过观察人类行为就能够完成任务。该方法旨在增强人类与机器人之间的沟通,同时推进人类与机器人无缝协同工作的研究进程。
在其论文中,研究人员表示:“为了让机器人在现实世界中执行有用的任务,必须简单地将任务传达给机器人;这包括预期结果以及任何与实现该结果的最佳方法有关的提示。借助演示,用户可以向机器人传达任务,并提供线索,以帮助机器人更好地完成任务。”
通过NVIDIA TITAN X GPU,研究人员训练了一系列神经网络,用于执行与感知、程序生成及程序执行相关的任务。结果显示,机器人能够通过现实世界内的单次演示而学习任务。
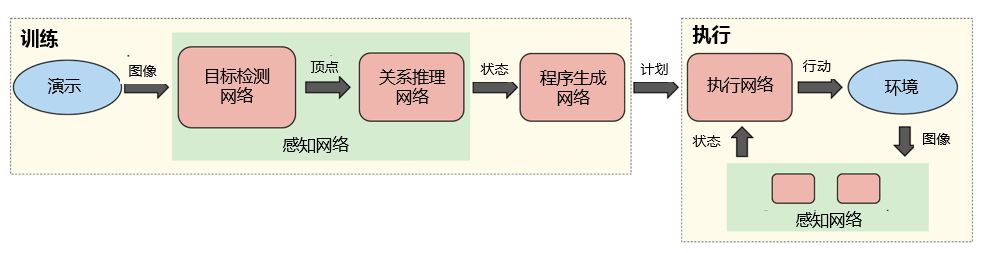
该方法的工作方式具体为:
通过摄像头来获取某场景的实时视频流,随后由一对神经网络实时推理该场景内目标的位置与关系。
由此生成的感知被传输到另一个网络,并生成用于解释如何重建这些感知的计划。
最后,执行网络读取该计划,并为机器人生成动作;同时会考虑到当前场景的状态,以确保应对外部干扰的稳健性。
机器人看到任务后,即生成人类可读的步骤描述,这是重新执行任务所必需的环节。该描述能够让用户在机器人执行之前快速辨别并纠正机器人对人类演示解读所出现的任何问题。
获得此项能力的关键在于充分利用合成数据来训练神经网络。现有的神经网络训练方法需要大量带有标记的训练数据,对这些系统而言是一个瓶颈。通过合成数据生成,可以轻松地生成几乎无限量的标记训练数据。
这也是第一次将以图像为中心的域随机化 (image-centric domain randomization) 方法用于机器人。域随机化技术用于生成具有大量多样性的合成数据,并诱使感知网络相信所看到的真实数据只是其训练数据的另一种变体。研究人员选择以图像为中心的方式来处理数据,以确保网络不依赖于摄像头或环境。
研究人员表示:“这种感知网络适用于任何固态的现实世界物体,它们可以通过其3D边界立方体(bounding cuboid)来进行合理模拟。尽管在训练期间从未观察到真实图像,但即使在被严重遮挡的情况下,感知网络仍能可靠地检测到真实图像内的目标边界立方体。”
在其演示中,该团队使用多个彩色方块和一辆玩具车来训练目标检测器。该系统学会了方块之间的物理关系,比如方块堆叠在一起,或者是相邻放置。
在上述演示视频中,人类操作员向机器人展示了一组立方体。随后该系统对其程序进行了推理,并按照正确的顺序将立方体放置好。由于其在执行过程中考虑到了当前的状态,因此该系统能够实时从错误中恢复过来。
本周,在澳大利亚布里斯班举办的世界机器人与自动化大会(ICRA)上,研究人员将展示其研究论文与成果。
该团队表示将继续探索合成训练数据在机器人操控领域内的应用,并研究出将该方法应用于更多场景的能力。
-
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块2025-01-04 2277
-
机器人是什么?2022-03-31 22239
-
程序教会无人车更“懂礼貌”2018-08-15 3468
-
深度学习让机器人变得越来越像人2018-07-13 1592
-
基于深度学习技术的智能机器人2018-05-31 6378
-
英伟达新研究使用合成训练数据进行机器人操纵2018-05-23 3937
-
未来机器人也可以像人一样进行学习?2018-04-17 5919
-
人类与人工智能机器人合作的前景2018-04-16 3904
-
让机器人通过一段只有一个人的视频来模仿学习2018-02-07 7010
-
人类与机器人有感情产生吗?2017-11-10 5120
-
不寒而栗:机器人只需看看 就能模仿人类2016-09-05 972
-
什么是鸥鹏机器人制作的小型物流系统?2016-04-05 3710
-
【Aworks申请】家庭服务机器人2015-07-19 2074
-
Baxter——通过语言和动作教机器人完成任务2015-01-22 8627
全部0条评论

快来发表一下你的评论吧 !
