

将自注意力机制引入GAN,革新图像合成方式
电子说
描述
图像合成是计算机视觉中的一个重要问题。谷歌大脑的Ian Goodfellow等人在他们的最新研究中提出“自注意力生成对抗网络”(SAGAN),将自注意力机制引入到卷积GAN中,作为卷积的补充,在ImageNet多类别图像合成任务中取得了最优的结果。
图像合成(Image synthesis)是计算机视觉中的一个重要问题。随着生成对抗网络(GAN)的出现,这个方向取得了显著进展。基于深度卷积网络的GAN尤其成功。但是,通过仔细检查这些模型生成的样本,可以观察到,在ImageNet这类的有许多图像类别的数据集上训练时,卷积GAN合成的图像不尽如人意。
针对这个问题,谷歌大脑的Ian Goodfellow和Augustus Odena,以及罗格斯大学的Han Zhang和Dimitris Metaxas等人在他们的最新研究中提出“自注意力生成对抗网络”(SAGAN),将自注意力机制(self-attention mechanism)引入到卷积GAN中,作为卷积的补充,取得了最优的结果。

摘要
在这篇论文中,我们提出自注意力生成对抗网络( Self-Attention Generative Adversarial Network ,SAGAN)。SAGAN允许对图像生成任务进行注意力驱动、长相关性的建模。传统的卷积GAN生成的高分辨率细节仅作为在低分辨率特征图上的空间局部点的函数。在SAGAN中,可以使用来自所有特征位置的线索来生成细节。此外,鉴别器可以检查图像的远端部分的高度详细的特征彼此一致。此外,最近的研究表明,生成器条件会影响GAN的性能。利用这些发现,我们将谱归一化到GAN生成器中,并发现这改进了训练动态。我们提出的SAGAN达到了state-of-the-art的结果,将Inception score从当前最高的36.8提高到52.52,并且在具有挑战性的ImageNet数据集上将Frechet Inception distance从27.62降低到18.65。注意力层的可视化表明,生成器利用与对象形状相对应的邻域,而不是固定形状的局部区域。
SAGAN:将自注意力机制引入GAN
尽管最先进的ImageNet GAN模型 [17] 擅长合成几乎没有结构性限制的图像类别(例如,海洋、天空和景观类,它们的区别更多在于纹理而不是几何结构),但它无法捕获在某些类别中经常出现的几何模式或结构模式(例如,狗通常有逼真的皮毛纹理,但没有明确区分的脚)。
一种可能的解释是,以前的模型严重依赖于卷积来建模不同图像区域之间的依赖关系。由于卷积运算符具有一个局部感受域,所以在经过几个卷积层之后,只能处理长距离的相关性。
由于各种原因,这可能会阻止学习长相关性(long-term dependencies):小的模型可能无法表示它们,优化算法可能无法发现参数值,这些参数值仔细协调多个层,以捕获这些相关性,并且这些参数化在统计学上可能相当脆弱,当应用于以前未见过的输入时容易失败。增加卷积核的大小可以提高网络的表征能力,但这样做也会失去利用局部卷积结构获得的计算和统计效率。
另一方面,自注意力(Self-attention)可以更好地平衡模型的长相关性和计算与统计效率。self-attention模块以所有位置的特征加权和来计算响应,其中权重(或attention vectors)只以很小的计算成本来计算。

图 1:我们提出的SAGAN通过利用图像远端部分的互补特征来生成图像,而不是固定形状的局部区域,从而可以生成一致的对象/场景。图中每一行的第一个图像显示了带颜色编码点的五个代表性查询位置。其他五个图像是针对这些查询位置的 attention maps,其中对应的颜色编码的箭头概括了最受关注的区域。
在这项工作中,我们提出了自注意力生成对抗网络(SAGAN),它将自注意力机制(self-attention mechanism)引入到卷积GAN中。自注意力模块(self-attention module)是对卷积的补充,有助于模拟跨越图像区域的长距离、多层的依赖关系。通过self-attention,生成器可以绘制图像,所绘制图像中每个位置的精细细节都与图像远端的精细细节充分协调。此外,鉴别器还可以更准确地对全局图像结构执行复杂的几何约束。
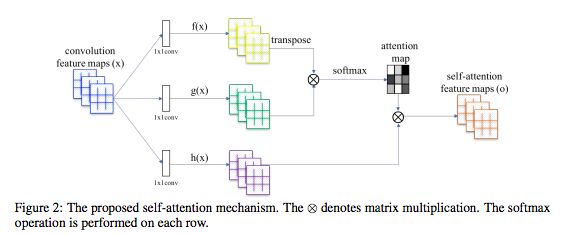
图2:所提出的self-attention机制。⊗表示矩阵乘法,在每一行上执行softmax操作。
除了self-attention之外,我们还将最近关于网络调节(network conditioning)的见解与GAN的性能结合起来。A. Odena等人的研究[18]表明,调节良好的生成器往往表现更好。我们建议使用以前仅应用于鉴别器的谱归一化技术(spectral normalization)来加强GAN生成器器的调节。
我们在ImageNet数据集上进行了大量的实验,以验证所提出的self-attention机制和稳定技术的有效性。SAGAN在图像合成方面的表现远远超过了state-of-the-art的表现,将此前报告的最高Inception score从36.8提高到52.52,将Fréchet初始距离(Fréchet Inception distance,FID)从27.62降低到18.65。attention层的可视化显示,生成器利用与对象形状相对应的区域,而不是固定形状的局部区域。
ImageNet上的图像合成实验
为了评价所提出的方法,我们在LSVRC 2012 (ImageNet)上数据集进行了大量的实验。首先,我们对评估所提出的两种稳定GAN训练的技术进行有效性实验。其次,对所提出的self-attention mechanism进行了研究。最后,将SAGAN与其他state-of-the-art的图像生成方法进行了比较。
评估指标
我们使用Inception score(IS)和Fréchet初始距离(FID)进行定量评估。Inception score越高,表示图像质量越好。 FID是一个更加基于规则和综合性的指标,并且在评估生成的样本的真实性和变异性方面已被证明与人类的评估更加一致。越低的FID值意味着合成数据分布与真实数据分布之间的距离更近。
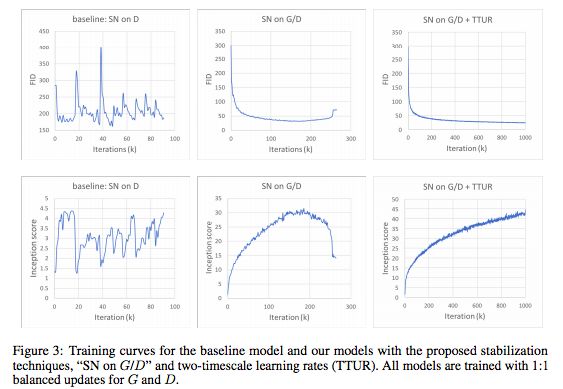
图3:基线模型与我们的模型的训练曲线,利用了我们提出的稳定技术
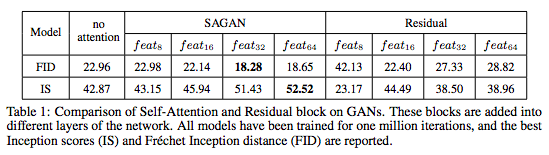
表1:GAN的Self-Attention与Residual块的比较。这些块被添加到网络的不同层。所有模型都经过100万次迭代的训练,并报告最佳的Inception score(IS)和Fréchet初始距离(FID)。
图4:基线模型和我们的模型随机生成的128×128图像样本
图5:attention maps的可视化。这些图像都由SAGAN生成。
与state-of-the-art模型的比较
在ImageNet上,SAGAN与最先进的GAN模型[19,17]进行了比较。如表2所示,我们提出的SAGAN得到了Inception score和FID。Inception score方面,SAGAN将此前0最高的36.8提高到52.52;FID(18.65)也表明,SAGAN可以通过使用self-attention模块对图像区域之间的全局依赖关系进行建模,从而更好地模拟原始图像的分布。图6展示了由SAGAN生成的一些示例图像。
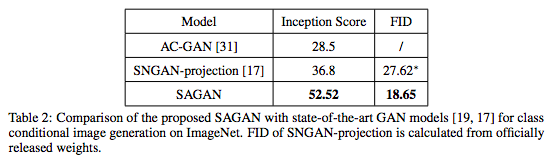
表2: 将所提出的SAGAN与最先进GAN模型进行比较,任务是ImageNet上的类别条件图像生成。
图6:SAGAN 生成的不同类别的128×128分辨率示例图像。每行展示一个类别的示例。
总结
在本研究中,我们提出自注意力生成对抗网络(SAGAN),它将self-attention机制引入到GAN的框架。 self-attention 模块在建模长相关性( long-range dependencies)方面很有效。另外,我们证明了应用于生成器的谱归一化可以稳定GAN的训练,并且TTUR加速了正则化鉴别器的训练。SAGAN在ImageNet的分类条件图像生成任务上达到最先进的性能。
-
PyTorch教程11.4之Bahdanau注意力机制2023-06-05 998
-
计算机视觉中的注意力机制2023-05-22 729
-
基于非对称注意力机制残差网络的图像检测2021-07-05 1144
-
基于注意力机制的跨域服装检索方法综述2021-06-27 899
-
基于多通道自注意力机制的电子病历架构2021-06-24 1000
-
基于注意力机制等的社交网络热度预测模型2021-06-07 1142
-
结合注意力机制的跨域服装检索方法2021-05-12 1027
-
基于通道注意力机制的SSD目标检测算法2021-03-25 1284
-
基于空间/通道注意力机制的化学结构图像识别方法2021-03-22 1341
-
基于注意力机制的深度学习模型AT-DPCNN2021-03-17 1270
-
注意力机制或将是未来机器学习的核心要素2020-05-07 1855
-
注意力机制的诞生、方法及几种常见模型2019-03-12 44409
-
深度分析NLP中的注意力机制2019-02-17 4986
-
浅谈自然语言处理中的注意力机制2019-01-25 7269
全部0条评论

快来发表一下你的评论吧 !
