

两篇关于Google语义表示相关研究最新进展的论文
描述
近年来,“基于神经网络的自然语言识别”相关的研究取得了飞速进展,特别是在学习语义的文本表示方面,这些进展有助于催生一系列真正新奇的产品,例如智能撰写(Gmail 的辅助邮件创作)和Talk to Books(访问文末的链接,试着与书籍对话)。还有助于提高训练数据量有限的各种自然语言任务的性能,例如,通过仅仅 100 个标记示例构建强大的文本分类器。
下面我们将讨论两篇关于 Google 语义表示相关研究最新进展的论文,以及可在 TensorFlow Hub 上下载的两个新模型,我们希望开发者使用这些模型来构建令人兴奋的新应用。
TensorFlow Hub 是一个管理、分发和检索用于 TensorFlow 的可重用代码(模型)的管理工具。
语义文本相似度
在“Learning Semantic Textual Similarity from Conversations”中,我们引入了一种新的方法来学习语义文本相似度的语句形式。可以直观理解为,如果句子的答复具有相似的分布,那么它们在语义上是相似的。例如,“你多大了?” (How old are you?) 和“你几岁了?” (What is your age?) 都是关于年龄的问题,可以通过类似的答复来回答,例如“我 20 岁” (I am 20 years old)。相比之下,虽然“你好吗?” (How are you?) 和“你多大?” (How old are you?) 包含的英文单词几乎相同,但它们的含义却大相径庭,因而答复也不同。
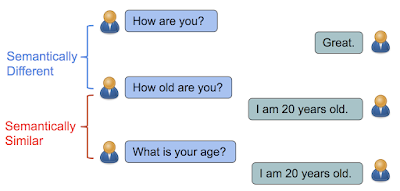
如果句子可以通过相同的答复来回答,那么它们在语义上是相似的。否则,它们在语义上是不同的。
在这项研究中,我们的目标是通过答复分类任务学习语义相似度:给定一个对话输入,我们希望从一批随机选择的答复中选出正确的答复。但是,最终目标是学习一个可以返回表示各种自然语言关系(包括相似度和相关性)编码的模型。通过添加另一个预测任务(在本例中为SNLI 蕴含数据集),并通过共享编码层强制执行,我们在相似度度量方面获得了更好的性能,例如STSBenchmark(句子相似度基准)和CQA 任务 B(问题/问题相似度任务)。这是因为逻辑蕴含与简单的等价有很大不同,并且更有助于学习复杂的语义表示。

对于给定的输入,可将分类视为潜在候选项排名问题。
Universal Sentence Encoder
“Universal Sentence Encoder”一文中引入了一个模型,此模型通过增加更多的任务对上述多任务训练进行了扩展,我们使用类似于skip-thought的模型 (论文链接在文末)(可以在给定的文本范围内预测句子)来训练它们。但是,尽管原始 skip-thought 模型中采用的是编码器-解码器架构,我们并未照搬使用,而是通过共享编码器的方式使用了只有编码器的架构来驱动预测任务。通过这种方式可以大大缩短训练时间,同时保持各种传输任务的性能,包括情感和语义相似度分类。目的是提供一种单一编码器来支持尽可能广泛的应用,包括释义检测、相关性、聚类和自定义文本分类。
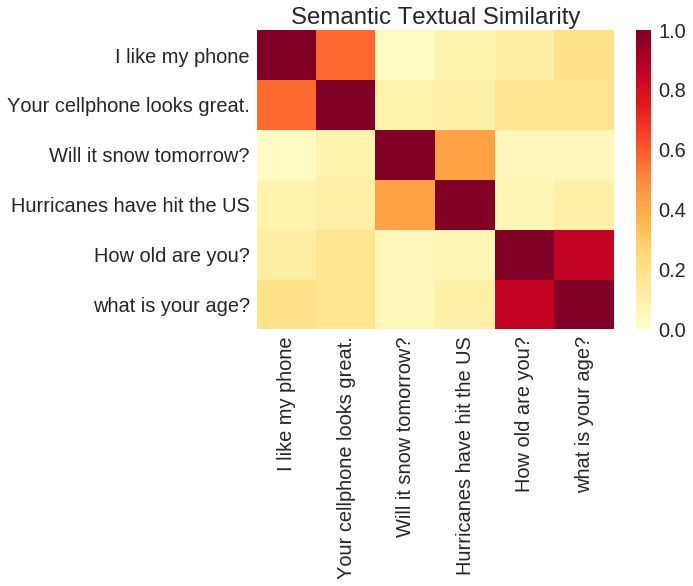
基于 TensorFlow Hub Universal Sentence Encoder 的输出进行的语义相似度成对比较。
正如我们的论文所述,Universal Sentence Encoder 模型的一个版本使用了深度平均网络(DAN) 编码器,而另一个版本则使用了更复杂的自助网络架构- Transformer。
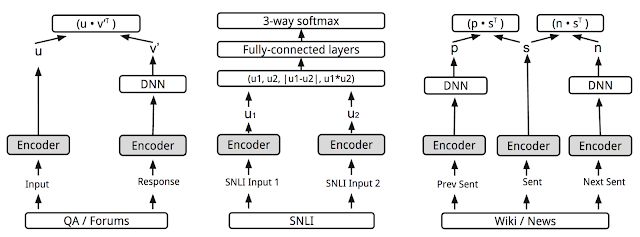
"Universal Sentence Encoder"中所述的多任务训练。各种任务和任务结构通过共享编码器层/参数(灰色框)连接。
对于更复杂的架构而言,与相对简单的 DAN 模型相比,此模型在各种情感和相似度分类任务上的表现更加出色,而短句子方面的速度只是稍微慢一些。然而,随着句子长度的增加,使用 Transformer 的模型的计算时间显著增加,而同等条件下,DAN 模型的计算时间几乎保持不变。
新模型
除了上述 Universal Sentence Encoder 模型外,我们还将在 TensorFlow Hub 上分享两个 新 模型:Universal Sentence Encoder - Large和Universal Sentence Encoder - Lite。这些都是预训练的 Tensorflow 模型,可返回可变长度文本输入的语义编码。这些编码可用于语义相似度度量、相关性、分类或自然语言文本的聚类。
Large 模型使用 Transformer 编码器进行训练,我们的第二篇论文进行了介绍。此模型适用于需要高精度语义表示以及要求以速度和大小为代价获得最佳模型性能的场景。
Lite 模型基于 Sentence Piece 词汇而非单词进行训练,以显著减少词汇量,而词汇量则显著影响模型大小。此模型适用于内存和 CPU 等资源有限的场景,例如基于设备端或基于浏览器的实现。
我们很高兴与社区分享本研究成果和这些模型。我们相信这里所展示的成果只是一个开始,并且还有许多重要的研究问题亟待解决。例如,将技术扩展到更多语言(上述模型目前仅支持英语)。我们也希望进一步开发这项技术,以便能够理解段落甚至文档级别的文本。如果能够完成这些任务,或许我们能制作出一款真正意义上的“通用”编码器。
-
VisionFive 2 AOSP最新进展即将发布!2023-10-08 1335
-
5G最新进展深度解析.zip2023-01-13 916
-
关于深度学习的最新进展2022-08-30 2055
-
CMOS图像传感器最新进展及发展趋势是什么?2021-06-08 4762
-
ITU-T FG IPTV标准化最新进展如何?2021-05-27 2701
-
介绍IXIAIP测试平台和所提供测试方案的最新进展2021-05-26 3638
-
探析人机自然交互研究的最新进展2019-02-25 4765
-
谷歌在量子计算机学习任务方面取得新进展2019-01-07 3435
-
车联网技术的最新进展2018-09-21 17546
-
UWB通信技术最新进展及发展趋势2017-02-07 1326
-
DIY怀表设计正式启动,请关注最新进展。2012-01-13 11064
-
开关电源电磁兼容及其研究新进展2009-12-23 6322
-
风光互补技术原理及最新进展2009-10-26 4696
-
风光互补技术及应用新进展2009-10-22 3011
全部0条评论

快来发表一下你的评论吧 !
