

一项Gmail新功能-智能撰写,为电子邮件写作提供了一种新的方式
描述
在 5 月初的 Google I/O 大会上,我们推出了一项 Gmail 新功能 -智能撰写,此功能利用机器学习,以交互方式在用户打字时给出建议,帮助用户补全句子,从而提高电子邮件的写作速度。智能撰写基于为智能回复开发的技术,为电子邮件写作提供了一种新的方式。无论是回复收到的电子邮件,还是新写邮件都能够体验。
在开发智能撰写的过程中,需要面对许多关键挑战,其中包括:
延迟时间:智能撰写基于每次的按键操作提供预测,因此它必须在 100 毫秒内作出响应,用户才不会注意到任何延迟。因此,如何平衡模型复杂度和推断速度成为一个关键问题。
规模:Gmail 拥有超过 14 亿用户。要为所有 Gmail 用户提供有效的自动补全建议,模型必须具备足够的建模能力,才能根据不同的语境给出相应的建议。
公平性和隐私性:在开发智能撰写时,我们需要在训练过程中杜绝存在潜在偏见的数据源,同时必须遵守与智能回复相同的严格用户隐私标准,确保模型不会泄露用户的隐私信息。此外,研究人员无法访问电子邮件,这意味着他们必须开发并训练一个机器学习系统来处理他们无法读取的数据集。
寻找合适的模型
ngram、神经词袋(BoW) 和RNN 语言(RNN-LM) 等典型的语言生成模型基于前面的单词序列学习预测下个单词。 然而,在电子邮件场景中,用户在当前电子邮件撰写会话中所打出的单词只是模型可用于预测下个单词的提示之一。为了融入有关用户想表达内容的更多语境,我们的模型将电子邮件主题和之前的电子邮件正文(如果用户要回复收到的邮件)也作为了一种预测条件。
要想包含这一额外语境,一种方法是将此问题看作序列到序列(seq2seq) 的机器翻译任务,其中源序列是主题和之前电子邮件正文(如果有)的结合,目标序列是用户当前正在撰写的电子邮件。尽管此方法在预测质量方面表现良好,但它远远达不到我们严格的延迟时间约束标准。
为了改善这种情况,我们将 BoW 模型与 RNN-LM 结合起来,结果,速度快于 seq2seq 模型,且模型预测质量损失微乎其微。在这种混合方法中,我们通过将每个字段中的词嵌入取平均值,对主题和之前的电子邮件进行编码。然后在每个解码步骤中,将这些平均嵌入连接起来并输入到目标序列 RNN-LM 中。模型架构如下图所示。
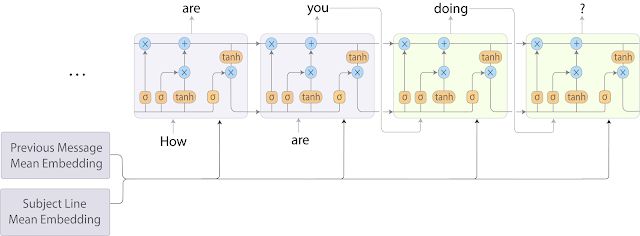
智能撰写 RNN-LM 模型架构。通过对每个字段中的词嵌入取平均值,对主题和之前的电子邮件消息进行编码。然后在每个解码步骤中将平均嵌入输入到 RNN-LM 中。
加速模型训练与服务
当然,确定使用这种建模方法后,我们仍需要调整不同的模型超参数,并在数十亿个样本上训练模型,这些加起来需要耗费大量时间。为了加快速度,我们使用完整的 TPUv2 Pod 进行实验。通过这种方式,不到一天的时间即可将模型训练至收敛。
即使在训练完较快的混合模型之后,最初版本的智能撰写在标准 CPU 上运行时的平均服务延迟时间仍高达数百毫秒,这个值对于一个试图节约用户时间的功能来说仍然是不可接受的。幸运的是,在推断时还可以使用 TPU,从而极大地加速用户体验。通过将大量计算转移到 TPU 上,我们将平均延迟时间减少到几十毫秒,同时极大地提高了单个机器可服务的请求数量。
公平性和隐私性
机器学习中的公平性非常重要,因为语言理解模型可能反映人类的认知偏见,产生一些不受欢迎的单词和句子关联。正如 Caliskan 等人在他们的近期论文"Semantics derived automatically from language corpora contain human-like biases"中所述,这些关联与自然语言数据有着盘根错节的联系,这对构建语言模型提出了巨大挑战。我们正在积极探索如何在训练过程中进一步减少潜在偏见。同时,由于智能撰写与垃圾邮件机器学习模型的训练方式类似,基于数十亿词组和句子训练而成,因此,我们运用此论文的研究成果,对模型进行了大量测试,以便确保只有多个用户使用的常见词组才会被模型记住。
-
电子邮件的使用培圳教程2009-03-10 3190
-
传真百科:电子邮件能取代传真吗2015-01-14 4205
-
电子邮件的使用教程2009-03-11 1841
-
一种电子邮件网络的加权演化模型与仿真2009-07-16 800
-
基于数字签名的安全电子邮件系统的研究2009-08-04 1804
-
怎样通过Microsoft Exchange电子邮件使用Gmail或Google Apps for Business2019-12-13 7803
-
如何获取Gmail帐户以通过txt将电子邮件发送到手机2019-10-14 7360
-
谷歌Gmail新功能可引入多个邮件签名2020-03-11 2295
-
iOS 14中更改默认电子邮件应用的方法2020-09-24 3775
-
Gmail在电子邮件中添加了品牌徽标2020-10-27 2781
-
微软新AI项目为文档和电子邮件的图像添加字幕2020-11-18 2187
-
谷歌Gmail现已支持苹果iOS14小组件功能2020-11-19 2140
-
如何有效防御接连不断的电子邮件攻击2022-01-30 2145
-
Aryson--将电子邮件从Gmail移动到iCloud帐户的最简单方法2023-10-10 2889
-
谷歌Gmail将支持Gemini总结电子邮件内容2024-05-15 1559
全部0条评论

快来发表一下你的评论吧 !
