

Watson是如何读题的
电子说
描述
与人或大部分其他问答系统相似,Watson在处理问题的第一步是对问题进行仔细地分析,以了解提问者的意图,并找到正确的方式去解决它。这也是非常关键的一步,后面的很多分析与计算都以此为基础,这里主要用到了Watson的语法解析与语义分析能力,包括:深层的语法解析、实体识别、指代消解、关系抽取模块。利用大量的规则与在此基础上训练的分类器,去检测问题中以下几个关键元素:
1)问题焦点(focus):问题中指代答案的部分;
2)答案的词汇类型(lexical answer types):问题中指示被问到实体的类型的关键词;
3)问题所属的宽泛类型;
4)问题中需要特殊处理的部分。
下面会对这些元素逐一举例介绍。
关键元素
焦点(focus)
问题中指代答案的部分,一般为代词,如下列问题:POETS & POETRY: He was a bank clerk in the Yukon before he published "Songs of a Sourdough" in 1907.
中的He。这样的词在答案中可能有好几个,但找到一个就够了,其它的可通过指代消解的方式得到。找到”focus“以后,可以通过与包含答案的文章段落进行对齐,从而找到答案。
答案的词汇类型(lexical answer types)
LAT指的是问题所问的是什么类型的实体,一般focus的中心词即为LAT,如上例中的”he“与”clerk“,很多问题还提供了额外信息作为LAT,如上面问题的“poet”。(Jeopardy! 比赛中都给出了问题的种类)。得到LAT后可以用来检验算法给出的候选答案的类型是否正确。这样不仅利用了问句本身的信息,还利用了比赛中关于问题种类的信息。
问题分类(Question Classification)
先预定义若干种问题,每种问题有不同的解决方法或处理流程。对问题进行分类,判断它属于某一种或几种类型,再调用相应的处理流程。上面的问题属于比较常见的仿真陈述(Factoid)问题。
问题片段(QSections)
问题中需要特殊处理的片段。QSections的一个典型应用是识别问题中关于答案的各种不同的约束(如答案是3个字,是地名),然后将问题分解为若干个字问题进行解答。
问题的基本分析
句法解析与语义分析
Watson的句法解析与语义分析模块主要包含部分:包含谓词论元结构构(PAS)造器的槽语法解析模块ESG、命名实体识别模块、指代消解模块、关系抽取模块。
ESG模块是用来将问句解析为一个包含句子表层结构与深层逻辑结构的树。每个节点上附有:1)一个词项(由一个或若干个单词组成)和与之对应的包涵逻辑参数的谓词;2)特征列表,部分是关于句法形态的,部分是语义相关的;3)该节点的左右修饰语以及修饰语所填充的槽。1)中的谓词与逻辑参数正是句子的深层结构之所在,逻辑参数为树中其它节点,可能再句子上离当前节点比较远
在上面的例子中可以识别出谓词逻辑publish(e1, he, ‘‘Songs of a Sourdough’’) 与 in(e2, e1, 1907),后者说明了前者也就是这个pubilish事件发生在1907年。并且还可以抽取出authorOf(focus, ‘‘Songs of a Sourdough’’) 与 temporalLink(publish(. . .), 1907这样的三元组关系。
针对Jeopardy!问题所做调整
1)Jeopardy!问题的单词全都是大写,对人来说没什么,然而单对用计算机进行语法分析来说,大小写是非常重要的信息,所以先用一个在其它数据集上训练的分类器来对单词的大小写进行预测与改写。
2)Jeopardy!问题的语言习惯与日常领域有着较大差异,例如日常问句一般以“Wh-”开头,但在Jeopardy!中却喜欢用this/these、he/she、it等。此外Jeopardy!中名词短语出现的频次非常高。因此在解析Jeopardy!的问句时需要调整解析模型的参数,如增加名词短语的先验或转移概率。
3)问题的focus往往是个代词,所以在进行分析时先识别出focus再将focus排除在外进行指代消解。
关系抽取做的调整
为了应对Jeopardy!特殊的语言风格,对原本用于普通文本的关系抽取模块做了调整。这样一方面能检测出在Jeopardy!的问题中经常出现的对后面的处理特别有用的一些关系,如focus的别名、时间关系、地理位置关系等,具体例子如下表。

另一方面,用来匹配这些关系等模式,也已可以用来识别出问句的一些特定特征,这些特征可以用于训练问题的分类器或其他处理。那么这些规则时如何实现的呢?下面将开始介绍。
规则的Prolog实现
Watson的问题分析流程是通过由一系列组件组成的UIMA Pipeline实现的,而大部分的分析流程都是一些基于句子的PAS结构与一些外部数据库(如WordNet)的规则实现的。这就需要一门语言,一方面能够基于句法解析的结果很方便的实现这些规则,另一方面又能很容易地集成到UIMA框架中,Prolog作为一种逻辑式编程语言,是一个很好的选择。它可以很方面地将UIMA中的CAS数据结构转换成fact对象。
例如对于以下是基于句法与语义分析的结果转换成的fact:
lemma(1, ‘‘he’’)partOfSpeech(1,pronoun)lemma(2, ‘‘publish’’)partOfSpeech(2,verb)lemma(3,‘‘Songs of a Sourdough’’)partOfSpeech(3,noun)subject(2,1)object(2,3)
其中括号里面的数字是PAS节点的唯一标识。有了这些fact,Prolog系统可以利用一些规则去识别问题的focus、LAT与其他关系(relation)。例如将如下规则:
authorOf(Author, Composition) :- createVerb(Verb), subject(Verb, Author), author(Author), object(Verb, Composition), composition(Composition).-
createVerb(Verb) :- partOfSpeech(Verb, verb), lemma(Verb, VerbLemma), [‘‘write’’, ‘‘publish’’, . . .].
应用到各个节点上,可以识别出关系authorOf(1,3)。使用Prolog无论在系统运行速度还是规则的可扩展性上表现都是非常优秀的。在关系抽取、focus检测、LAT检测、问题分类与Qsection检测等任务上都有各自的规则集,这些规则使用了超过6000条的Prolog语句,整个问题分析的UIMA Pipeline如下。

focus与LAT检测
基本方法
匹配focus的基本规则按照优先级排序如下所示,其中斜体词表示focus,黑体词表示中心词:
1)带有限定词“this”或“these”的名词短语: THEATRE: A new play based on thisSir Arthur Conan Doyle canine classic opened on the London stage in 2007.
2)“This”或“these”本身作为名词短语: In April 1988, Northwest became the first U.S. air carrier to ban this on all domestic flights.
3)当整个问句是一个名词短语时,将整个问句都标记为focus:AMERICAN LIT: Number of poems Emily Dickinson gave permission to publish during her lifetime.
4)代词“he/she/his/her/him/hers”中的一个:OUT WEST: She joined Buffalo Bill Cody’s Wild West Show after meeting him at the Cotton Expo in New Orleans.
5)代词“it/they/them/its/their”中的一个:ME "FIRST"!: It forbids Congress from interfering with a citizen’s freedom of religion, speech, assembly, or petition.
6)代词“one”:12-LETTER WORDS: Leavenworth, established in 1895, is a federal one.
当这些规则都不满足时,问题可能就没有focus。这种规则对句法解析有很高的要求,例如解析器需要能够准确的将限定词与中心词关联起来(两者并不是都是毗邻的),并且能准确地区分名词短语与动词短语也很重要,所以特地对ESG解析模块进行了调整。
检测LAT的方法一般是采用focus的中心词,并加上下面几条例外:
1)如果focus是一个组合, 采用这个组合部分: HENRY VIII: Henry destroyed the Canterbury Cathedral Tomb of this saint and chancellor of Henry II.
2)如果存在“ of X”这种模式,并且是“one/name/type/kind”中的任何一个,那么采用X作为LAT:HERE, PIGGY, PIGGY, PIGGY: Many a mom has compared her kid’s messy room to this kind of hog enclosure.
3)如果存在“ for X”这种模式,且是“name/word/term”中的任何一个,那么采用X作为LAT:COMPANY NAME ORIGINS: James Church chose this name for his product because the symbols of the god Vulcan represented power.
4)如果没有检测到focus,且category是一个名词短语,那么采用category的中心词作为LAT:HEAVY METAL BANDS: "Seek & Destroy", "Nothing Else Matters", "Enter Sandman".
提升方法
上面介绍的基本方法已经可以取得相对中肯的精度,但错误也是并不少见,经常会漏过一些有用的LAT。下面就是一些基本方法失败的案例来讲述提升方法或补充方法:
1) PAIRS: An April 1997 auction of Clyde Barrow’s belongings raised money to fund moving his grave next to hers.
2) FATHER TIME (400): On Dec. 13, 1961, Father Time caught up with this 101-year-old artist with a relative in her nickname.
3) CRIME: Cutpurse is an old-time word for this type of crowd-working criminal.
4) THE FUNNIES: “Marmaduke’’ is this breed of dog.
5) ISLAND HOPPING: Although most Indonesians are Muslims, this is the predominant religion on Bali.
6) I FORGET: Mythical rivers of Hades include the Styx and this one from which the dead drank to forget their lives.
7) FAMOUS AMERICANS: Although he made no campaign speeches, he was elected president in 1868 by a wide electoral margin.
例1)中第一个代词his并非focus,因为它指代实体“Clyde Barrow”,所以在应用基本方法找到多个代词作为候选focus时,应该选择不指代任何实体的代词。找到focus后可以利用前指代消解模块帮我们找到指示答案性别的LAT。
例3)与4)中focus表达了一种子类关系,我们将这个子类从介词短语中剥离出来作为LAT。
在检测LAT时,还有一个困难是决定LAT是一个还是多个词。大部分情况下我们认为LAT是一个词,但在“this vice president”这种情形如果采用“president”作为LAT是错误的。因此,如果多个单词(修饰词+中心词)不是其中心词的一个子类型或者修饰语改变了中心词的意思并且这种意思并不常见,这时采用多个词作为LAT。
从问题的category中获取LAT
通过观察得知,一般情况下,如果category中的词满足以下三个条件则很可能是一个LAT:
1)涉及到实体的类型;
2)这个实体的类型与问句中的LAT(如果有的话)一致;
3)这种类型在问题中没有任何提及(mention)或实例。
例如问题:
BRITISH MONARCHS: She had extensive hair loss by the age of 31. 的category中的“MONARCHS”(君主)表示实体的类型,并且与问句中的LAT(she)一致,所以它也是一个LAT。
估计LAT的置信度
利用人工标注的LAT数据,基于如下几种特征来训练一个逻辑回归模型来对线上检测到的LAT进行打分,作为其置信度:
1)被激活的focus与LAT规则;
2)从句法分析与NER的结果中构建的特征;
3)该单词作为LAT的先验概率。
统计纠偏
先离线统计出各种category的问题中category中的各个词作为LAT的频率,并且以这个频率作为其置信度(不用上面的逻辑回归模型进行打分)。过滤掉过低置信度的词,并且根据前面的规则是否检测到LAT分别统计这两种情形下的置信度。这样有可能召回前面规则漏掉的LAT。
效果评估
用基本方法与采用了这里展示的几种提升方法的Watson分别在手工标注的9128个问题上的进行评估,得到的结果如下:
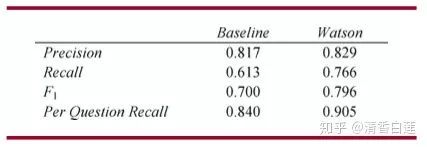
可见提升方法还是有显著效果的,尤其是在召回率(Recall)上。
问题分类与Qsection检测
Jeopardy! 的问题有很多种类,统一用一种方法来处理效果并不理想,并且问题的部分片段可能有着特殊作用,如果能做针对性的处理对提升准确性也是有益的。所以对问题进行分来并检测出这些特殊的片段是问题分析中重要的一步。
问题分类
Watson默认的回答问题的方式是针对仿真陈述问题(Factoid Question)的,然而有些问题根本无法使用这种方式去回答,还有部分问题虽然不是不能用默认的方式去回答,但经过分类处理,做针对性的分析也会更好地解答。通过对3500个Jeopardy!的问题进行人工聚类,得到的问题分类与占比如下表所示。

检测问题类型的方式主要是通过正则表达式、句法规则等模式匹配的技术,所以一个问题可能匹配上多种类型。当然这些类型中部分之间存在互斥,所以匹配完成之后,如果匹配上的类型中有互斥的,要去掉互斥对中置信度较低的哪个类型。
上表所示的问题类型(QClass)中PUZZLE、BOND、FITB (Fill-in-the blank)、BOND与MULTIPLE-CHOICE的表示方式相对固定,所以用正则表达式去匹配。对于其他的QClass,由于没有固定的表达方式,所以通过基于PAS结构的句法规则去匹配,具体如下:
ETYMOLOGY:包含“From for , ...,”或其它类似模式;
VERB:focus通常是“do”的宾语或者是包含不定式的定义式问题(如“This 7-letter word means to presage or forebode”);
TRANSLATION:包含模式“ is for “或或者问题是只是一个没有focus的短语并且其category确定了一门语言。
NUMBER与DATE:如果LAT中包含数字或日期的实例;
DEFINITION:关键短语“is the word for”与“Bmeans”以及经常出现的category如“CROSSWORD CLUES”;
CATEGORY-RELATION:问句仅仅是一个实体或一串实体(没有检测到focus);
ABBREVIATION:并不是包含缩写的问题都是ABBREVIATION类问题,这里的识别方法与识别LAT类似。先制定一些规则,包括正则表达式与句法规则。然后以这些规则以及当前category是ABBREVIATION类型问题的先验概率作为特征训练一个逻辑回归模型来判断当前问题是否是ABBREVIATION类型。如果是再用专门的方法求出全称,这种方法详见参考文献[2],后面也会专门介绍。
检测Qsection
QSection是指问句(偶尔在category中)中对问题的解释有着特殊功能的连续区域。与问题分类类似,QSection的检测也是通过正则表达式与PAS结构上的句法规则实现的。其中比较重要的QSection有:
1)LexicalConstraint:对答案的词汇方面做限制的短语,如”this 4-letter word“ ,这对答案的选择有重要作用;
2)Abbreviation:被识别为缩写的词项,并与其可能的全称进行关联。对于QClass为ABBREVIATION的问题,有一个abbreviation的全称即为答案,需要被识别出来做更加精准的分析来确定答案;
3)SubQuestionSpan:当原问题可以被分解若干个片段,每一个片段可以单独对答案产生影响,这些单独的片段即为SubQuestionSpan。这种通过对原始问题进行分解的求解方式后面会做专门介绍;
4)McAnswer:多选问题中表示答案的选择的字符串(经常3个);
5)FITB:与focus毗邻的字符串(如focus的补充成分)。
效果评估
基于3500个人工分类的问题对分类方法进行评测,得到的结果如下表所示:
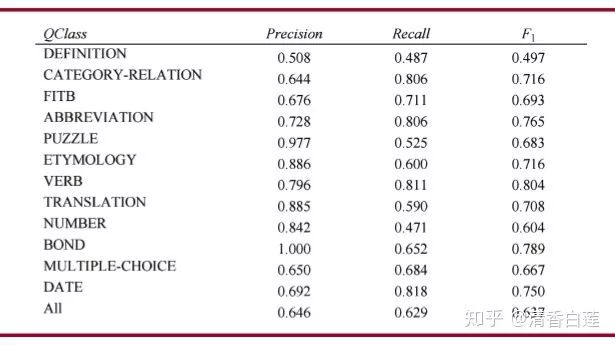
DEFINITION识别起来比较困难,然而实际上这种问题直接中默认的Factoid方式进行回答,问题不是特别大。PUZZLE的召回率较低时由于其类型的长尾分布,导致规则覆盖不够。
将Watson的问题分类与特殊片段的检测功能移除与完整状态进行评测对比如下,可见这种处理能让Watson多答对2.9%(有focus与LAT检测功能)的问题。

结论
通过上面的评测结果可知,与只有基本的focus、LAT检测功能的Basline问题分析流程相比,集成了本文介绍的全部focus检测、LAT检测、问题分类与QSection检测模块功能的分析流程可以使Watson多答对5.9%的问题。这个Gap对能否战胜人类选手是非常重要的。
-
UM2273_IBM_Watson_IoT云扩展软件包入门2018-11-02 1800
-
Watson感知模型分析2011-09-01 3966
-
IBM联手百洋智能科技,推出Watson肿瘤解决方案落户平安好医生2018-07-02 1691
-
IBM发布了基于Watson的企业社交协作新产品2018-06-08 4224
-
IBM Watson到底能不能治病?2018-08-13 5473
-
连接英特尔IOT网关和IBM Watson IOT平台2018-10-23 3626
-
IBM Watson为什么总是失败 这4大原因值得注意2018-11-01 10088
-
Watson备受争议 AI医疗任重而道远2018-11-22 2462
-
IBM:将向所有云平台开放自家Watson人工智能系统2019-02-25 1166
-
IBM Watson大裁70% 员工!AI 导入医疗,遇到了怎样的瓶颈?2019-05-10 3595
-
怎样连接到IBM Watson IoT2019-11-25 2522
-
IBM推出Watson Works,旨在助力企业应对复工挑战2020-06-29 3081
-
了解Watson Assistant新的增强功能2021-01-06 2738
-
Watson-Marlow宣布新更名实施网站重组和升级2022-04-12 2123
-
watson-theme Sublime Text主题2022-05-19 554
全部0条评论

快来发表一下你的评论吧 !
