

基于yolo算法进行改进的高效卫星图像目标检测算法
电子说
描述
卫星图像是十分重要的资源,可以通过它计量国土资源,检测地面情况并且能高瞻远瞩的记录地表发生的变化。但由于卫星图像十分巨大而且其中的物体相对较小,利用卫星图像进行目标检测是充满挑战的工作,本文主要讲解了一篇基于yolo算法进行改进的高效卫星图像目标检测算法,主要针对高分辨率输入和密集小物体进行了优化。
在大面积的图像中识别出一系列小物体是卫星图像处理的主要任务之一。近年来基于深度学习的目标检测算法有了很大的效率提升,但基于卫星图像的处理还存在这一系列问题。为了解决这一系列调整,研究人员在YOLO的基础上提出了一种两阶段的算法架构,不仅可以适应多尺度的检测,同时达到了F1>0.8的结果,最后还探究了分辨率和物体大小对于检测的影响,并发现只需要五个像素的大小就可以实现目标检测。文章主要从深度学习对于卫星图像目标检测的缺陷出发,提出了改进的细粒度的目标检测网络结构。同时为了解决检测不变性的问题进行了大量的数据增强。
1. 卫星图像目标检测存在的问题
高分辨率的卫星图像和相对较小的图内物体使得卫星图像处理目前主要面临以下四个方面的挑战:
空间范围较小:在卫星图像中,感兴趣的物体相对尺寸都很小而且常常聚拢在一起,与ImageNet数据集中大范围的显著物体大不相同。同时物体的分辨率主要由地面采样距离决定,它定义了每个像素对应的物理长度。通常情况下卫星运行的高度是350km左右,最清晰的商用卫星图像可以达到30cm的GSD(每个像素对应30cm),而普通的数字卫星影响只能达到3-4m的分辨率了。所以对于车辆、船只这样的小物体来说可能只有10多个像素来描述;
卫星图像中的物体具有各个方位的朝向,而ImageNet数据集中大多是竖直方向的,需要检测器具有旋转不变性;
训练数据的缺乏,对于卫星图像缺乏高质量的训练数据,虽然SpaceNet已经进行了一系列有益的工作,但还需要进一步改进;
极高的图像分辨率,与通常输入的小图片不同,卫星图像动辄上亿像素,简单的将采样方法对于卫星图像处理无法适用。
在过去的几年里深度学习早已成为目标检测的重要工具,但却还有一系列问题有待优化。比如像鸟群一样的密集小物体检测是目前需要解决的挑战。这主要是由于卷积神经网络中一系列降采样操作造成的,如果目标仅仅包含很少的像素数目,这种方法会造成很大的问题。例如在yolo中降采样因子是32同时返回13*13的预测栅格,这意味着如果一个某个物体的像素少于32个就会引起严重的问题。
研究人员为了解决这个问题对YOLO的网络架构进行了改造,加密了最后预测输出的栅格数量,从而提高了网络对于细粒度特征的检测结果以及区分不同物体的能力,改善了对于小物体和密集物体群的检测。
同时目标检测算法对于不常见的的比例或新的图像分布缺乏一定的泛化能力。由于物体可能的方向和尺寸比例各不相同,算法有限的比例变化对于特殊目标的检测就会失效。为了解决这一问题,研究人员对数据进行了旋转和HSV的随机增强,是算法对于不同传感器、大气条件和光照条件具有更强的鲁棒性。
目前先进的目标检测算法都是对整幅图像进行处理的,但对于上亿像素的卫星图像来说,很难有硬件显卡内存可以满足如此大的需求。为了解决对于多尺度目标的高速检测,研究人员提出了利用区域图像作为输入,利用多尺度检测其来进性检测的方法。在实际过程中,大概200m尺度的图像片作为输入,并利用一定的上采样进行处理。
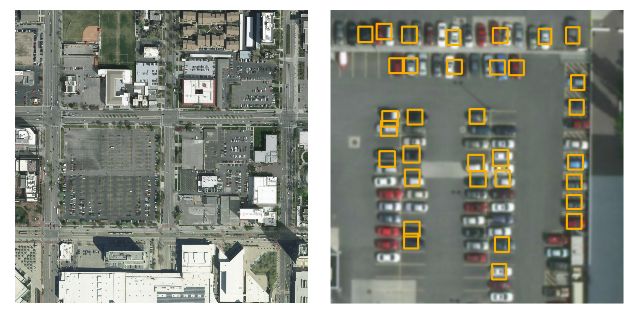
下图中对比了原始图像和其中的图像片输入网络后的结果。全尺寸的网络几乎无法得到任何结果(下采样后图片分辨率损失),而图像片(像素数小于32)得到的结果也不尽如人意。
2. 算法与网络架构
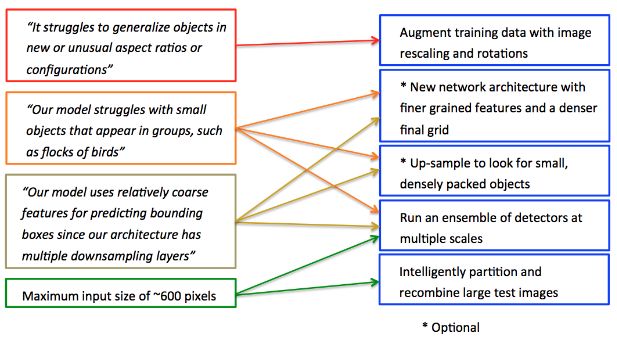
首先研究人员们对算法架构进行了改造,将网络结构改成了22层和16的降采样因子,416*416的像素输入后能得到26*26的输出栅格,通过这样的技术来优化网络对于小物体、密集排布的检测效果。更密集的预测栅格对于停车场车辆和码头船只的检测十分重要。同时为了提高小物体的保真度,引入了一个直通层将最后52*52的直通层和最后一个卷基层进行组合,使得检测器可以通过拓展特组图发现更多细粒度的特征。
卷积网络中的神经元都使用批量归一化和LeakyRelu激活,最后一层使用线性激活函数。最后输出的结果N=Nboxes*(Nclass+5),每一个bbox包含四个坐标和一个包含物体的概率,以及属于每类物体的概率。
3. 训练数据
由于在卫星图像处理中,主要关注飞机、轮船、建筑平面、汽车和机场,它们的尺度各不相同。研究人员训练了两个不同尺度的检测器来进行目标检测。
- 汽车数据集使用了COWC数据集,基于15cm的GSD尺度。为了与目前商用卫星图像的30cm尺度一致,利用高斯核对图像进性了处理,并在30cmGSD的尺度上为每辆车标注3m的边框,共13303个样本;
- 建筑平面基于SpaceNet的数据在30cmGSD尺度下标注了221336个样本;
- 飞机利用八张GigitalGlobe的图片标注了230个样本;
- 船只利用三张GigitalGlobe的图片标注了556个样本;
- 机场利用37张图片作为训练样本,其中包含机场跑道,并进行4比例的降采样。
训练过程中使用了NVIDIA Titan X GPU,学习率0.001,权重衰减0.0005,动量0.9。
4. 测试
为了对测试图像的结果,研究人员们使用智能图像分割将原始图像按照15%的重叠率切分成一系列子图,并按照如下的格式进行位置标注:
ImageName|row_column_height_width.ext

将每一张图像送入模型后,得到的结果再更具上面的位置标记恢复到完整的图像中显示。
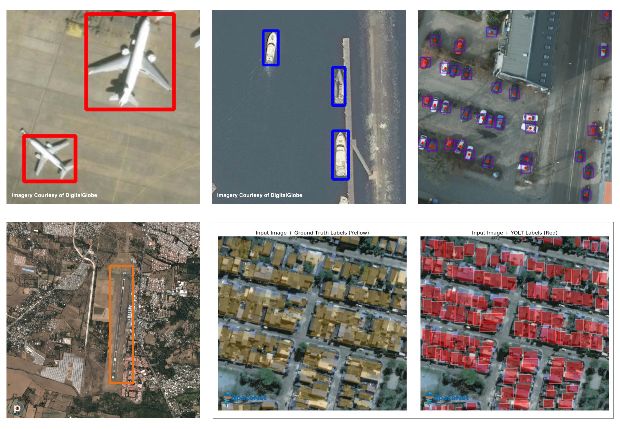
最终的检测结果如下图所示:
街区内测车辆检测结果
飞机和轮船的检测结果
目前一分钟可以处理30平方千米的图像,对于机场这样的大尺度对象来说可以除了6000平方公里。未来如果用16GPU集群可以实现实时的卫星图像目标检测。
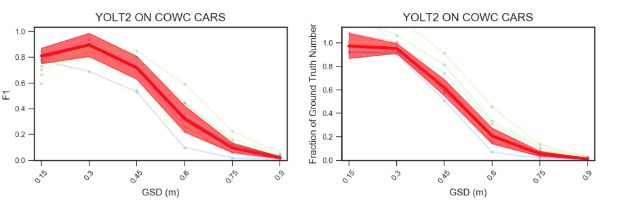
同时研究人员还探索了分辨率随检测准确率的关系,发现分辨率越高图像的准确率越高
想上手尝试一下的小伙伴,github上有docker封装好的代码,上手即用:
https://github.com/CosmiQ/yolt
最后再来欣赏几幅检测后的漂亮的卫星图像:
-
人脸检测算法及新的快速算法2013-09-26 3866
-
PowerPC小目标检测算法怎么实现?2019-08-09 2640
-
基于YOLOX目标检测算法的改进2023-03-06 1442
-
基于像素分类的运动目标检测算法2009-04-10 600
-
医学图像边缘检测算法的研究2010-07-05 898
-
基于Canny检测算法实现的目标跟踪2012-03-05 1341
-
基于Surendra改进的运动目标检测算法2013-08-07 994
-
改进的ViBe运动目标检测算法_刘春2017-03-19 1281
-
如何使用Zynq SoC硬件加速实现改进TINY YOLO实时车辆检测的算法2020-07-06 1730
-
基于深度学习YOLO系列算法的图像检测2020-11-27 4243
-
基于深度学习的目标检测算法2021-04-30 11369
-
基于改进YOLOv3的行人车辆目标检测算法2021-05-31 887
-
基于改进YOLOv2的遥感图像目标检测技术2021-06-16 1103
-
一种改进的高光谱图像CEM目标检测算法2022-03-05 1909
-
浅谈红外弱小目标检测算法2022-08-04 8006
全部0条评论

快来发表一下你的评论吧 !
