

用AlexNet对cifar-10数据进行分类
电子说
描述
上周我们用PaddlePaddle和Tensorflow实现了图像分类,分别用自己手写的一个简单的CNN网络simple_cnn和LeNet-5的CNN网络识别cifar-10数据集。在上周的实验表现中,经过200次迭代后的LeNet-5的准确率为60%左右,这个结果差强人意,毕竟是二十年前写的网络结构,结果简单,层数也很少,这一节中我们讲讲在2012年的Image比赛中大放异彩的AlexNet,并用AlexNet对cifar-10数据进行分类,对比上周的LeNet-5的效果。
什么是AlexNet?
AlexNet在ILSVRC-2012的比赛中获得top5错误率15.3%的突破(第二名为26.2%),其原理来源于2012年Alex的论文《ImageNet Classification with Deep Convolutional Neural Networks》,这篇论文是深度学习火爆发展的一个里程碑和分水岭,加上硬件技术的发展,深度学习还会继续火下去。
AlexNet网络结构
由于受限于当时的硬件设备,AlexNet在GPU粒度都做了设计,当时的GTX 580只有3G显存,为了能让模型在大量数据上跑起来,作者使用了两个GPU并行,并对网络结构做了切分,如下:
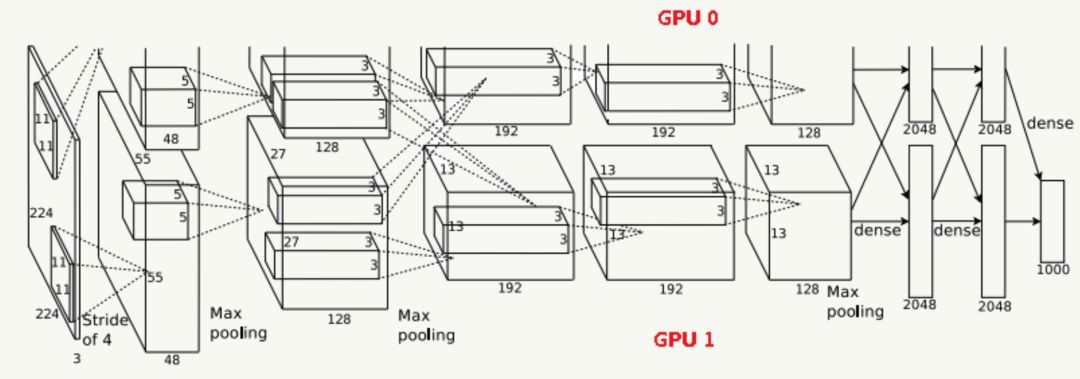
网络结构
Input输入层
输入为224×224×3的三通道RGB图像,为方便后续计算,实际操作中通过padding做预处理,把图像变成227×227×3。
C1卷积层
该层由:卷积操作 + Max Pooling + LRN(后面详细介绍它)组成。
卷积层:由96个feature map组成,每个feature map由11×11卷积核在stride=4下生成,输出feature map为55×55×48×2,其中55=(227-11)/4+1,48为分在每个GPU上的feature map数,2为GPU个数;
激活函数:采用ReLU;
Max Pooling:采用stride=2且核大小为3×3(文中实验表明采用2×2的非重叠模式的Max Pooling相对更容易过拟合,在top 1和top 5下的错误率分别高0.4%和0.3%),输出feature map为27×27×48×2,其中27=(55-3)/2+1,48为分在每个GPU上的feature map数,2为GPU个数;
LRN:邻居数设置为5做归一化。
最终输出数据为归一化后的:27×27×48×2。
C2卷积层
该层由:卷积操作 + Max Pooling + LRN组成
卷积层:由256个feature map组成,每个feature map由5×5卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为2的padding,输出feature map为27×27×128×2,其中27=(27-5+2×2)/1+1,128为分在每个GPU上的feature map数,2为GPU个数;
激活函数:采用ReLU;
Max Pooling:采用stride=2且核大小为3×3,输出feature map为13×13×128×2,其中13=(27-3)/2+1,128为分在每个GPU上的feature map数,2为GPU个数;
LRN:邻居数设置为5做归一化。
最终输出数据为归一化后的:13×13×128×2。
C3卷积层
该层由:卷积操作 + LRN组成(注意,没有Pooling层)
输入为13×13×256,因为这一层两个GPU会做通信(途中虚线交叉部分)
卷积层:之后由384个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×192×2,其中13=(13-3+2×1)/1+1,192为分在每个GPU上的feature map数,2为GPU个数;
激活函数:采用ReLU;
最终输出数据为归一化后的:13×13×192×2。
C4卷积层
该层由:卷积操作 + LRN组成(注意,没有Pooling层)
卷积层:由384个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×192×2,其中13=(13-3+2×1)/1+1,192为分在每个GPU上的feature map数,2为GPU个数;
激活函数:采用ReLU;
最终输出数据为归一化后的:13×13×192×2。
C5卷积层
该层由:卷积操作 + Max Pooling组成
卷积层:由256个feature map组成,每个feature map由3×3卷积核在stride=1下生成,为使输入和卷积输出大小一致,需要做参数为1的padding,输出feature map为13×13×128×2,其中13=(13-3+2×1)/1+1,128为分在每个GPU上的feature map数,2为GPU个数;
激活函数:采用ReLU;
Max Pooling:采用stride=2且核大小为3×3,输出feature map为6×6×128×2,其中6=(13-3)/2+1,128为分在每个GPU上的feature map数,2为GPU个数.
最终输出数据为归一化后的:6×6×128×2。
F6全连接层
该层为全连接层 + Dropout
使用4096个节点;
激活函数:采用ReLU;
采用参数为0.5的Dropout操作
最终输出数据为4096个神经元节点。
F7全连接层
该层为全连接层 + Dropout
使用4096个节点;
激活函数:采用ReLU;
采用参数为0.5的Dropout操作
最终输出为4096个神经元节点。
输出层
该层为全连接层 + Softmax
使用1000个输出的Softmax
最终输出为1000个分类。
AlexNet的优势
1.使用了ReLu激活函数
----原始Relu-----
AlexNet引入了ReLU激活函数,这个函数是神经科学家Dayan、Abott在《Theoretical Neuroscience》一书中提出的更精确的激活模型。原始的Relu激活函数(可参见 Hinton论文:《Rectified Linear Units Improve Restricted Boltzmann Machines》)我们比较熟悉,即max(0,x)
,这个激活函数把负激活全部清零(模拟上面提到的稀疏性),这种做法在实践中即保留了神经网络的非线性能力,又加快了训练速度。 但是这个函数也有缺点:
在原点不可微 反向传播的梯度计算中会带来麻烦,所以Charles Dugas等人又提出Softplus来模拟上述ReLu函数(可视作其平滑版):
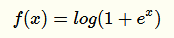
实际上它的导数就是一个
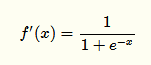
过稀疏性
当学习率设置不合理时,即使是一个很大的梯度,在经过ReLu单元并更新参数后该神经元可能永不被激活。
----Leaky ReLu----
为了解决上述过稀疏性导致的大量神经元不被激活的问题,Leaky ReLu被提了出来:
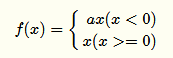
其中α是人工制定的较小值(如:0.1),它一定程度保留了负激活信息。
还有很多其他的对于ReLu函数的改进,如Parametric ReLu,Randomized ReLu等,此处就不再展开讲了。
2.Local Response Normalization 局部响应均值
LRN利用相邻feature map做特征显著化,文中实验表明可以降低错误率,公式如下:
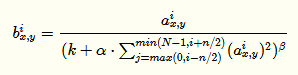
公式的直观解释如下:
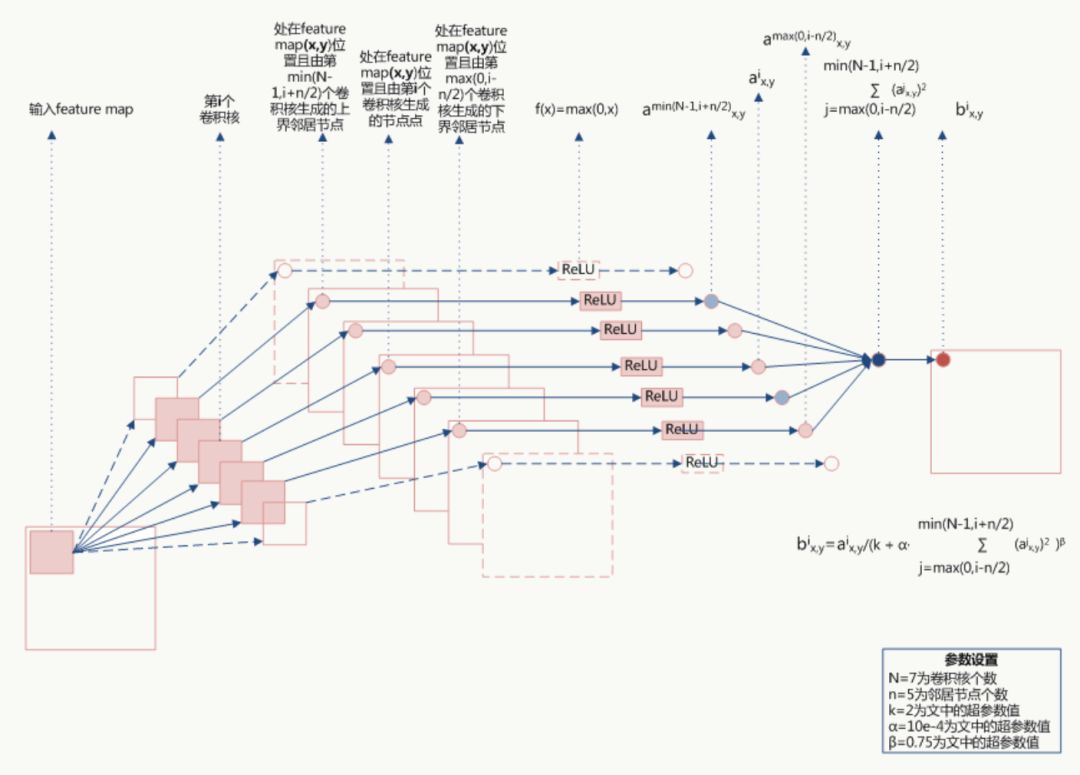
由于 α都是经过了RELU的输出,所以一定是大于0的,函数
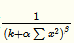
取文中参数的图像如下(横坐标为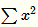 ):
):
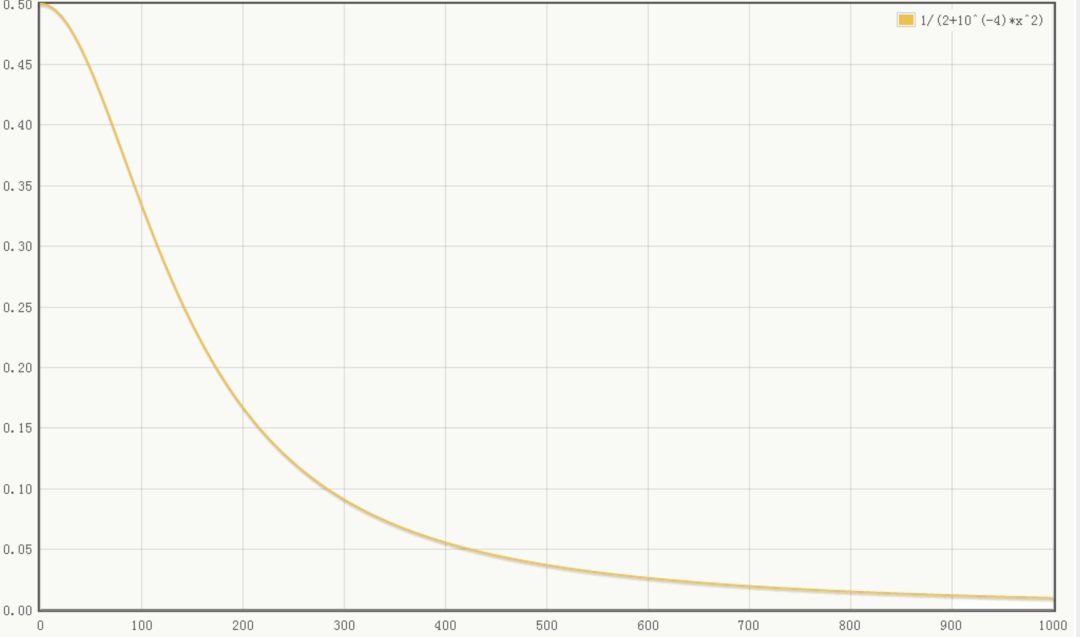
当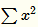 值较小时,即当前节点和其邻居节点输出值差距不明显且大家的输出值都不太大,可以认为此时特征间竞争激烈,该函数可以使原本差距不大的输出产生显著性差异且此时函数输出不饱和
值较小时,即当前节点和其邻居节点输出值差距不明显且大家的输出值都不太大,可以认为此时特征间竞争激烈,该函数可以使原本差距不大的输出产生显著性差异且此时函数输出不饱和
当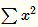 值值较大时,说明特征本身有显著性差别但输出值太大容易过拟合,该函数可以令最终输出接近0从而缓解过拟合提高了模型泛化性。
值值较大时,说明特征本身有显著性差别但输出值太大容易过拟合,该函数可以令最终输出接近0从而缓解过拟合提高了模型泛化性。
3.Dropout
Dropout是文章亮点之一,属于提高模型泛化性的方法,操作比较简单,以一定概率随机让某些神经元输出设置为0,既不参与前向传播也不参与反向传播,也可以从正则化角度去看待它。(关于深度学习的正则化年初的时候在公司做过一个分享,下次直接把pdf放出来)
从模型集成的角度来看:
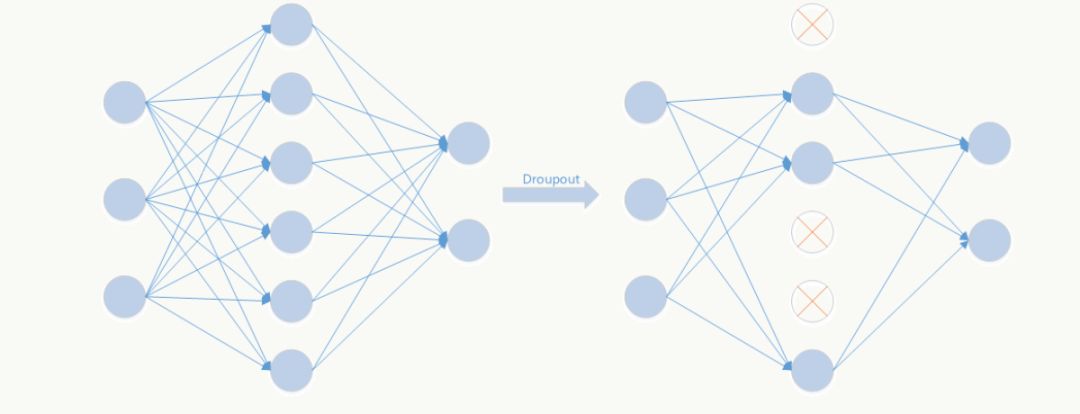
无Dropout网络:
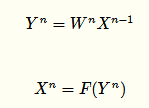
有Dropout网络:
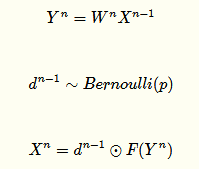
其中p为Dropout的概率(如p=0.5,即让50%的神经元随机失活),n为所在的层。
它是极端情况下的Bagging,由于在每步训练中,神经元会以某种概率随机被置为无效,相当于是参数共享的新网络结构,每个模型为了使损失降低会尽可能学最“本质”的特征,“本质”可以理解为由更加独立的、和其他神经元相关性弱的、泛化能力强的神经元提取出来的特征;而如果采用类似SGD的方式训练,每步迭代都会选取不同的数据集,这样整个网络相当于是用不同数据集学习的多个模型的集成组合。
用PaddlePaddle实现AlexNet
1.网络结构(alexnet.py)
这次我写了两个alextnet,一个加上了局部均值归一化LRN,一个没有加LRN,对比效果如何
#coding:utf-8 ''' Created by huxiaoman 2017.12.5 alexnet.py:alexnet网络结构 ''' import paddle.v2 as paddle import os with_gpu = os.getenv('WITH_GPU', '0') != '1' def alexnet_lrn(img): conv1 = paddle.layer.img_conv( input=img, filter_size=11, num_channels=3, num_filters=96, stride=4, padding=1) cmrnorm1 = paddle.layer.img_cmrnorm( input=conv1, size=5, scale=0.0001, power=0.75) pool1 = paddle.layer.img_pool(input=cmrnorm1, pool_size=3, stride=2) conv2 = paddle.layer.img_conv( input=pool1, filter_size=5, num_filters=256, stride=1, padding=2, groups=1) cmrnorm2 = paddle.layer.img_cmrnorm( input=conv2, size=5, scale=0.0001, power=0.75) pool2 = paddle.layer.img_pool(input=cmrnorm2, pool_size=3, stride=2) pool3 = paddle.networks.img_conv_group( input=pool2, pool_size=3, pool_stride=2, conv_num_filter=[384, 384, 256], conv_filter_size=3, pool_type=paddle.pooling.Max()) fc1 = paddle.layer.fc( input=pool3, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc( input=fc1, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) return fc2 def alexnet(img): conv1 = paddle.layer.img_conv( input=img, filter_size=11, num_channels=3, num_filters=96, stride=4, padding=1) cmrnorm1 = paddle.layer.img_cmrnorm( input=conv1, size=5, scale=0.0001, power=0.75) pool1 = paddle.layer.img_pool(input=cmrnorm1, pool_size=3, stride=2) conv2 = paddle.layer.img_conv( input=pool1, filter_size=5, num_filters=256, stride=1, padding=2, groups=1) cmrnorm2 = paddle.layer.img_cmrnorm( input=conv2, size=5, scale=0.0001, power=0.75) pool2 = paddle.layer.img_pool(input=cmrnorm2, pool_size=3, stride=2) pool3 = paddle.networks.img_conv_group( input=pool2, pool_size=3, pool_stride=2, conv_num_filter=[384, 384, 256], conv_filter_size=3, pool_type=paddle.pooling.Max()) fc1 = paddle.layer.fc( input=pool3, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc( input=fc1, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) return fc3
2.训练代码(train_alexnet.py)
#coding:utf-8 ''' Created by huxiaoman 2017.12.5 train_alexnet.py:训练alexnet对cifar10数据集进行分类 ''' import sys, os import paddle.v2 as paddle #alex模型为不带LRN的 from alexnet import alexnet #alexnet_lrn为带有lrn的 #from alextnet import alexnet_lrn with_gpu = os.getenv('WITH_GPU', '0') != '1' def main(): datadim = 3 * 32 * 32 classdim = 10 # PaddlePaddle init paddle.init(use_gpu=with_gpu, trainer_count=7) image = paddle.layer.data( name="image", type=paddle.data_type.dense_vector(datadim)) # Add neural network config # option 1. resnet # net = resnet_cifar10(image, depth=32) # option 2. vgg #net = alexnet_lrn(image) net = alexnet(image) out = paddle.layer.fc( input=net, size=classdim, act=paddle.activation.Softmax()) lbl = paddle.layer.data( name="label", type=paddle.data_type.integer_value(classdim)) cost = paddle.layer.classification_cost(input=out, label=lbl) # Create parameters parameters = paddle.parameters.create(cost) # Create optimizer momentum_optimizer = paddle.optimizer.Momentum( momentum=0.9, regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128), learning_rate=0.1 / 128.0, learning_rate_decay_a=0.1, learning_rate_decay_b=50000 * 100, learning_rate_schedule='discexp') # End batch and end pass event handler def event_handler(event): if isinstance(event, paddle.event.EndIteration): if event.batch_id % 100 == 0: print "\nPass %d, Batch %d, Cost %f, %s" % ( event.pass_id, event.batch_id, event.cost, event.metrics) else: sys.stdout.write('.') sys.stdout.flush() if isinstance(event, paddle.event.EndPass): # save parameters with open('params_pass_%d.tar' % event.pass_id, 'w') as f: parameters.to_tar(f) result = trainer.test( reader=paddle.batch( paddle.dataset.cifar.test10(), batch_size=128), feeding={'image': 0, 'label': 1}) print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics) # Create trainer trainer = paddle.trainer.SGD( cost=cost, parameters=parameters, update_equation=momentum_optimizer) # Save the inference topology to protobuf. inference_topology = paddle.topology.Topology(layers=out) with open("inference_topology.pkl", 'wb') as f: inference_topology.serialize_for_inference(f) trainer.train( reader=paddle.batch( paddle.reader.shuffle( paddle.dataset.cifar.train10(), buf_size=50000), batch_size=128), num_passes=200, event_handler=event_handler, feeding={'image': 0, 'label': 1}) # inference from PIL import Image import numpy as np import os def load_image(file): im = Image.open(file) im = im.resize((32, 32), Image.ANTIALIAS) im = np.array(im).astype(np.float32) im = im.transpose((2, 0, 1)) # CHW im = im[(2, 1, 0), :, :] # BGR im = im.flatten() im = im / 255.0 return im test_data = [] cur_dir = os.path.dirname(os.path.realpath(__file__)) test_data.append((load_image(cur_dir + '/image/dog.png'), )) probs = paddle.infer( output_layer=out, parameters=parameters, input=test_data) lab = np.argsort(-probs) # probs and lab are the results of one batch data print "Label of image/dog.png is: %d" % lab[0][0] if __name__ == '__main__': main()
用Tensorflow实现AlexNet
1.网络结构
def inference(images): ''' Alexnet模型 输入:images的tensor 返回:Alexnet的最后一层卷积层 ''' parameters = [] # conv1 with tf.name_scope('conv1') as scope: kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(bias, name=scope) print_activations(conv1) parameters += [kernel, biases] # lrn1 with tf.name_scope('lrn1') as scope: lrn1 = tf.nn.local_response_normalization(conv1, alpha=1e-4, beta=0.75, depth_radius=2, bias=2.0) # pool1 pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool1') print_activations(pool1) # conv2 with tf.name_scope('conv2') as scope: kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv2 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv2) # lrn2 with tf.name_scope('lrn2') as scope: lrn2 = tf.nn.local_response_normalization(conv2, alpha=1e-4, beta=0.75, depth_radius=2, bias=2.0) # pool2 pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool2') print_activations(pool2) # conv3 with tf.name_scope('conv3') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv3 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv3) # conv4 with tf.name_scope('conv4') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv4 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv4) # conv5 with tf.name_scope('conv5') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv5 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv5) # pool5 pool5 = tf.nn.max_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool5') print_activations(pool5) return pool5, parameters
完整代码可见:alexnet_tf.py
实验结果对比
三个代码跑完后,对比了一下实验结果,如图所示:

可以看到,在batch_size,num_epochs,devices和thread数都相同的条件下,加了LRN的paddlepaddle版的alexnet网络结果效果最好,而时间最短的是不加LRN的alexnet,在时间和精度上都比较平均的是tensorflow版的alexnet,当然,tf版的同样加了LRN,所以LRN对于实验效果还是有一定提升的。
总结
AlexNet在图像分类中是一个比较重要的网络,在学习的过程中不仅要学会写网络结构,知道每一层的结构,更重要的是得知道为什么要这样设计,这样设计有什么好处,如果对某些参数进行一些调整结果会有什么变化?为什么会产生这样的变化。在实际应用中,如果需要对网络结构做一些调整,应该如何调整使得网络更适合我们的实际数据?这些才是我们关心的。也是面试中常常会考察的点。昨天面试了一位工作五年的算法工程师,问道他在项目中用的模型是alexnet,对于alexnet的网络结构并不是非常清楚,如果要改网络结构也不知道如何改,这样其实不好,仅仅把模型跑通只是第一步,后续还有很多工作要做,这也是作为算法工程师的价值体现之一。本文对于alexnet的网络结构参考我之前的领导写的文章,如过有什么不懂的可以留言。
- 相关推荐
- 热点推荐
- 深度学习
- cnn
- tensorflow
-
线性分类器2018-10-09 2187
-
使用CIFAR-10彩色图片训练出现报错信息及解决2019-02-28 2101
-
在arm_nnexamples_cifar10_inputs.h 中所使用的輸入值為什麼會有負數的情況2022-09-13 2827
-
用Win10系统如何跑NMSIS的cifar10例程?2023-08-16 627
-
如何用单独的GPU,在CIFAR-10图像分类数据集上高效地训练残差网络2018-11-12 7880
-
如何使用神经网络模型加速图像数据集的分类2018-11-21 3022
-
Edgeboard试用—基于CIFAR10分类模型的移植2019-09-05 1619
-
cifar10数据集介绍 knn和svm的图像分类系统案例2023-07-18 935
全部0条评论

快来发表一下你的评论吧 !
