

机器学习算法之一:Logistic 回归算法的优缺点
人工智能
描述
Logistic 回归是二分类任务中最常用的机器学习算法之一。它的设计思路简单,易于实现,可以用作性能基准,且在很多任务中都表现很好。
因此,每个接触机器学习的人都应该熟悉其原理。Logistic 回归的基础原理在神经网络中也可以用到。在这篇文章中,你将明白什么是 Logistic 回归、它是如何工作的、有哪些优缺点等等。
什么是 Logistic 回归?
和很多其他机器学习算法一样,逻辑回归也是从统计学中借鉴来的,尽管名字里有回归俩字儿,但它不是一个需要预测连续结果的回归算法。
与之相反,Logistic 回归是二分类任务的首选方法。它输出一个 0 到 1 之间的离散二值结果。简单来说,它的结果不是 1 就是 0。
癌症检测算法可看做是 Logistic 回归问题的一个简单例子,这种算法输入病理图片并且应该辨别患者是患有癌症(1)或没有癌症(0)。
它是如何工作的?
Logistic 回归通过使用其固有的 logistic 函数估计概率,来衡量因变量(我们想要预测的标签)与一个或多个自变量(特征)之间的关系。
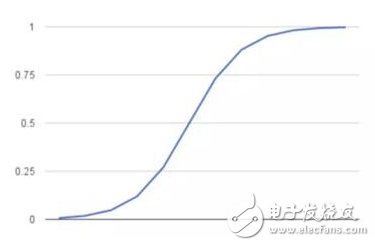
然后这些概率必须二值化才能真地进行预测。这就是 logistic 函数的任务,也称为 sigmoid 函数。Sigmoid 函数是一个 S 形曲线,它可以将任意实数值映射到介于 0 和 1 之间的值,但并不会取到 0/1。然后使用阈值分类器将 0 和 1 之间的值转换为 0 或 1。
下面的图片说明了 logistic 回归得出预测所需的所有步骤。
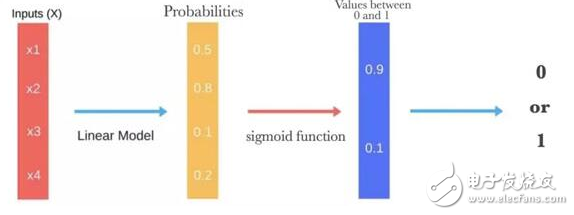
下面是 logistic 函数(sigmoid 函数)的图形表示:
我们希望随机数据点被正确分类的概率最大化,这就是最大似然估计。最大似然估计是统计模型中估计参数的通用方法。
你可以使用不同的方法(如优化算法)来最大化概率。牛顿法也是其中一种,可用于查找许多不同函数的最大值(或最小值),包括似然函数。也可以用梯度下降法代替牛顿法。
Logistic 回归 vs 线性回归
你可能会好奇:logistic 回归和线性回归之间的区别是什么。逻辑回归得到一个离散的结果,但线性回归得到一个连续的结果。预测房价的模型算是返回连续结果的一个好例子。该值根据房子大小或位置等参数的变化而变化。离散的结果总是一件事(你有癌症)或另一个(你没有癌症)。
优缺点
Logistic 回归是一种被人们广泛使用的算法,因为它非常高效,不需要太大的计算量,又通俗易懂,不需要缩放输入特征,不需要任何调整,且很容易调整,并且输出校准好的预测概率。
与线性回归一样,当你去掉与输出变量无关的属性以及相似度高的属性时,logistic 回归效果确实会更好。因此特征处理在 Logistic 和线性回归的性能方面起着重要的作用。
Logistic 回归的另一个优点是它非常容易实现,且训练起来很高效。在研究中,我通常以 Logistic 回归模型作为基准,再尝试使用更复杂的算法。
由于其简单且可快速实现的原因,Logistic 回归也是一个很好的基准,你可以用它来衡量其他更复杂的算法的性能。
它的一个缺点就是我们不能用 logistic 回归来解决非线性问题,因为它的决策面是线性的。我们来看看下面的例子,两个类各有俩实例。
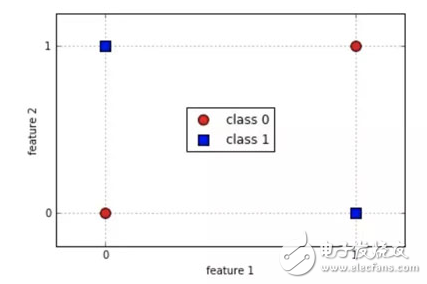
显然,我们不可能在不出错的情况下划出一条直线来区分这两个类。使用简单的决策树是个更好的选择。
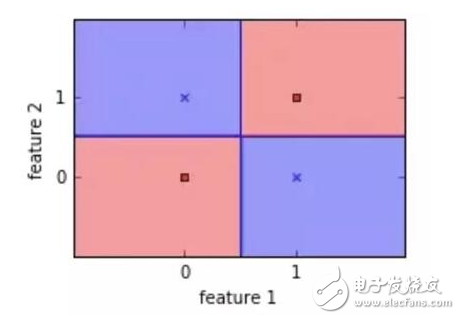
Logistic 回归并非最强大的算法之一,它可以很容易地被更为复杂的算法所超越。另一个缺点是它高度依赖正确的数据表示。
这意味着逻辑回归在你已经确定了所有重要的自变量之前还不会成为一个有用的工具。由于其结果是离散的,Logistic 回归只能预测分类结果。它同时也以其容易过拟合而闻名。
何时适用
就像我已经提到的那样,Logistic 回归通过线性边界将你的输入分成两个「区域」,每个类别划分一个区域。因此,你的数据应当是线性可分的,如下图所示的数据点:
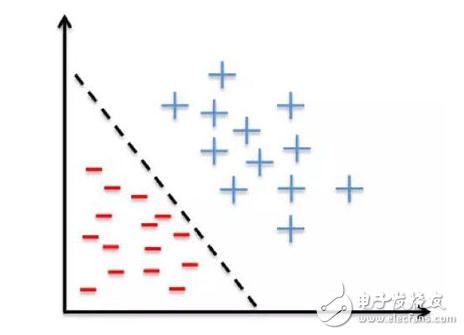
换句话说:当 Y 变量只有两个值时(例如,当你面临分类问题时),您应该考虑使用逻辑回归。注意,你也可以将 Logistic 回归用于多类别分类,下一节中将会讨论。
多分类任务
现在有很多多分类算法,如随机森林分类器或朴素贝叶斯分类器。有些算法虽然看起来不能用于多分类,如 Logistic 回归,但通过一些技巧,也可以用于多分类任务。
我们从包含手写体 0 到 9 的数字图像的 MNIST 数据集入手,讨论这些最常见的「技巧」。这是一个多分类任务,我们的算法应该告诉我们图像对应哪个数字。
1. 一对多(OVA)
按照这个策略,你可以训练 10 个二分类器,每个数字一个。这意味着训练一个分类器来检测 0,一个检测 1,一个检测 2,以此类推。当你想要对图像进行分类时,只需看看哪个分类器的预测分数最高
2. 一对一(OVO)
按照这个策略,要为每一对数字训练一个二分类器。这意味着要训练一个可以区分 0s 和 1s 的分类器,一个可以区分 0s 和 2s 的分类器,一个可以区分 1s 和 2s 的分类器,等等。如果有 N 个类别,则需要训练 N×N(N-1)/ 2 个分类器,对于 MNIST 数据集,需要 45 个分类器。
当你要分类图像时,就分别运行这 45 个分类器,并选择性能最好的分类器。这个策略与其他策略相比有一个很大的优势,就是你只需要在它要分类的两个类别的训练集上进行训练。
像支持向量机分类器这样的算法在大型数据集上扩展性不好,所以在这种情况下使用 Logistic 回归这样的二分类算法的 OvO 策略会更好,因为在小数据集上训练大量分类器比在大数据集上训练一个分类器要快。
在大多数算法中,sklearn 可以识别何时使用二分类器进行多分类任务,并自动使用 OvA 策略。特殊情况:当你尝试使用支持向量机分类器时,它会自动运行 OvO 策略。
其它分类算法
其他常见的分类算法有朴素贝叶斯、决策树、随机森林、支持向量机、k-近邻等等。我们将在其他文章中讨论它们,但别被这些机器学习算法的数量吓到。请注意,最好能够真正了解 4 或 5 种算法,并将精力集中在特征处理上,这也是未来工作的主题。
总结
在这篇文章中,你已了解什么是 Logistic 回归,以及它是如何工作的。你现在对其优缺点也了有深刻的了解,并且知道何时用它。
-
机器学习算法原理详解2024-07-02 3733
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2275
-
10大常用机器学习算法汇总2020-11-20 3357
-
机器学习实战之logistic回归2020-09-29 3185
-
回归算法有哪些,常用回归算法(3种)详解2020-07-28 2714
-
机器学习算法分享2020-06-09 2409
-
各类机器学习分类算法的优点与缺点分析2020-03-02 4371
-
干货 | 这些机器学习算法,你了解几个?2019-09-22 3129
-
如何帮你的回归问题选择最合适的机器学习算法2019-05-03 3591
-
经典算法大全(51个C语言算法+单片机常用算法+机器学十大算法)2018-10-23 43292
-
常见算法优缺点比较2017-12-02 5584
-
机器学习算法的介绍及算法优缺点的分析2017-09-19 961
-
机器算法学习比较2016-09-27 5102
全部0条评论

快来发表一下你的评论吧 !
