

NVMe高速传输之摆脱XDMA设计15:PCIe的TLP读处理
描述
对于存储器读请求TLP,使用Non-Posted方式传输,即在接收到读请求后,不仅要进行处理,还需要通过axis_cc总线返回CPLD,这一过程由读处理模块执行,读处理模块的结构如图1所示。
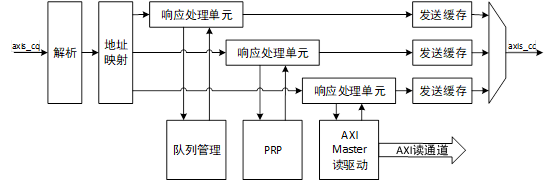
图1 读处理模块的结构图
当axis_cq总线接收到存储器读请求时,数据流被转发到读处理模块。读请求TLP只包含128比特的请求报头,而axis总线位宽也是128比特,因此在短时间内可能接收到多个读请求,为了应对这种情况,读处理模块采用了带有outstanding能力和事务并行处理的结构设计,能够有效提高读请求事务处理效率和数据传输吞吐量。
首先当读请求数据流到达读处理模块时,经过解析和地址映射的两级流水后,放入响应处理单元outstanding缓存中,响应处理单元从缓存中获取事务一一处理,将读取的数据打包成CPLD,并将CPLD放置到发送缓存中等待axis_cc总线的发送。根据地址的不同,读请求事务被分为三类,分别是读队列请求,读PRP请求和读数据请求,每种请求对应一个响应处理单元。
B站已给出相关性能的视频,如想进一步了解,请搜索B站用户:专注与守望
链接:https://space.bilibili.com/585132944/dynamic?spm_id_from=333.1365.list.card_title.click
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
NVMe高速传输之摆脱XDMA设计30: NVMe 设备模型设计2025-09-29 2641
-
NVMe高速传输之摆脱XDMA设计22:PCIe的TLP读优化处理2025-08-19 1843
-
NVMe高速传输之摆脱XDMA设计21:PCIe的TLP读处理2025-08-14 2292
-
NVMe高速传输之摆脱XDMA设计20: PCIe应答模块设计2025-08-12 2108
-
NVMe高速传输之摆脱XDMA设计16:TLP读处理优化2025-08-08 1098
-
NVMe高速传输之摆脱XDMA设计17:PCIe加速模块设计2025-08-07 1320
-
NVMe高速传输之摆脱XDMA设计16:TLP优化2025-08-05 5330
-
NVMe高速传输之摆脱XDMA设计13:PCIe请求模块设计(下)2025-08-04 4951
-
NVMe IP高速传输却不依赖XDMA设计之二:PCIe读写逻辑2025-06-09 992
-
NVMe IP高速传输却不依赖便利的XDMA设计之二2025-05-25 1324
全部0条评论

快来发表一下你的评论吧 !
