

i.MX RT1052芯片的核心板,性能和代码详细资料概述
电子说
描述
i.MX RT1052是i.MX RT系列芯片,是由 NXP 半导体公司推出的跨界处理器芯片,该系列下又包括i.MX RT1020、i.MX RT1050及 i.MX RT1060等子系列芯片。所谓“跨界”,是指它自身的定位既非传统的应用处理器也非传统的微控制器。
传统的应用处理器如手机主控芯片,它们通常采用 ARM 的 Cortex-A系列内核,配合其芯片架构使得芯片能实现更高频率的运行。传统的微控制器也称为 MCU,它们通常采用ARM 的 Cortex-M 系列内核,相对来说该内核对中断响应更快,所以具有良好的实时性,但其芯片架构特别是集成片内闪存带来了生产技术限制和成本负担,从而限制了其性能。而i.MX RT 系列芯片集成了两者的优点,它基于应用处理器的芯片架构,采用了微控制器的内核 Cortex-M7,从而具有应用处理器的高性能及丰富的功能,又具备传统微控制器的易用、实时及低功耗的特性。
野火的 i.MX RT1052核心板搭载了i.MX RT1025DVL6A芯片,Cortex-M7内核,主频高达600M。130个IO全部引出。集成32MB SDRAM、128MB NAND FLASH、32MB QSPI FLASH、2Kb EEPROM、LCD-RGB565 FPC接口、1个SWD调试接口、 1个uart 调试接口、1个电源LED、1个用户LED、 一个复位按键、1个MODE按键、 1个WAKEUP按键 和1个Microusb接口等资源。芯片I0共130个, 均通过0.8mm的BTB接口在背面引出,包括SEMC总线,方便我们扩展各种模块。
底板图片如下:
装在mini底板上的效果图,哎,杰杰还是很羡慕Pro底板的,资源丰富。连LCD都能放在板子上,而我的LCD就只能通过排线弄出来。
看看火哥核心板的风骚走线:
顶层
底层
骚气得一批,不过很多信号线都采用等长走线,保证了信号的稳定性,这个值得点赞!!!
介绍一下 i.MX RT1052芯片的性能优点吧:
1. 无需片内闪存
由于跨界处理器采用了应用处理器架构,具有大幅缩小的 SRAM 位单元,在跨界设计架构中,SRAM可以配置为具有“零等待”单周期访问的TCM,从而大幅提升系统性能。
2. 高性能
具备高密度片内 TCM 或缓存的跨界处理器的缓存未命中率可低至 1-2%,因此能够提供明显高于 MCU 的有效性能。
3. 低中断延迟
在协调对内部和外部硬件事件做出及时响应方面,中断在嵌入式系统中发挥了重要作用。在与用户交互的实时系统中,它们发挥的作用尤其重要,这是因为由用户输入触发的外部事件需要 CPU 做出可靠的低延迟即时响应。跨界处理器采用 MCU 内核构建,因此即使它们采用应用处理器架构,也延续了低中断延迟这一重要特性。跨界处理器的中断延迟最低可达到 10-20ns,而应用处理器的延迟通常长达 1毫秒。
4. 高能效以及安全性。
下面来说说固件库写的工程吧,按照火哥一贯舒服的代码风格
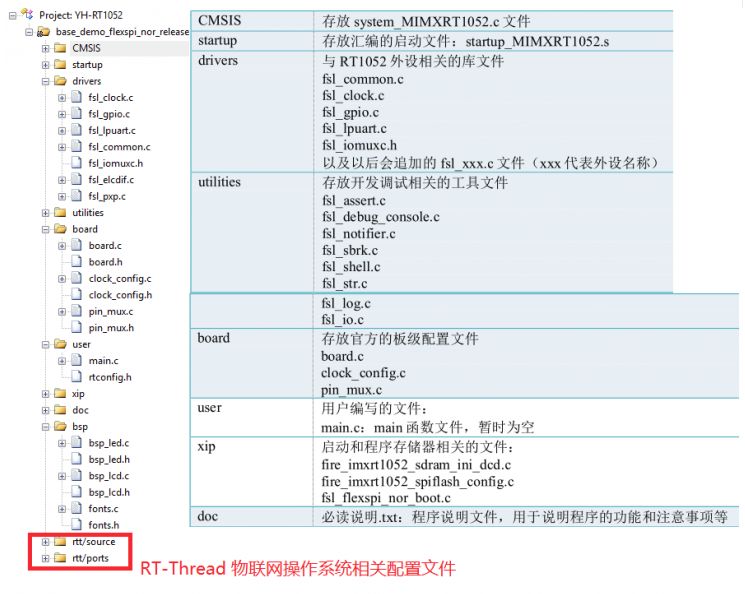
而且工程中含有不同版本的工程
正常来说,我们写代码不可能一次成功的,需要调试很久才出结果,可以通过ram_debug或者sdram_debug版本将程序快速加载到我们的开发板上的RT1052 芯片的内部 RAM 中或者是板载的SDRAM 芯片中,实现快速调试代码,但是RAM 空间小,适用于小程序调试,而板载的sdram则有32MB的空间,适用于大程序的调试。但是掉电则丢失这些程序,无法用在产品上,仅做调试用。
而下面两个版本,则可以作为产品的最终代码,将程序下载到NOR FLASH中,但是下载速度较慢,而且运行速度较SDRAM慢,杰杰猜测,我们或许应该可以将程序写为两段,在发布产品的时候,从NOR FLASH启动,运行NOR FLASH的第一段程序,将存在NOR FLASH的第二段程序加载到SDRAM中运行,直到掉电。这样子就能提高速度了吧。
前面的前三个模式均采用低优化等级(-O0)优化,而_flexspi_nor_release版本则采用高优化(-O3)等级,以便节约程序空间,提高运行效率。(杰杰吐槽:就是编译有点久)。
温馨提示:如果不用mdk看代码的话,可以去掉“魔术棒”->Output -> Browse Information的√。然后可以使用source insight看代码,方便很多,至少比mdk好多了。
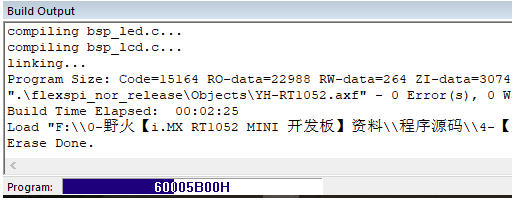
下个代码欣赏欣赏。
例程是移植了RT-Thread物联网操作系统的(还是要支持一下国产的操作系统的),来看看源码吧。
先介绍介绍RT-Thread物联网操作系统(以下简称rtt),操作系统是轻量级的,利用很小的资源完成实时操作系统的工作。
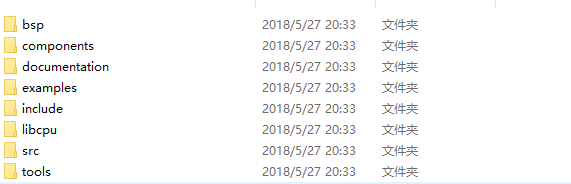
这些就是rtt的一些文件,bsp就是一些板级相关的东西,components就是一些组件,看英文单词都知道啦。然后就是src就是rtt的实现的源码,include就是一些头文件,而libcpu就是一些芯片的支持,tools就是一些rtt的工具,example还不会的别学嵌入式了。。。。。
看源码确实是一个很轻量级的操作系统,移植起来也是很简单,重点是火哥已经帮我们移植好啦,直接用吧,杰杰在学校rtt的过程中,发现跟一些操作系统还是有点不一样的,他的启动方式就在启动文件已经做好了。来看看:
在components.c中的148行
/* re-define main function */
int $Sub$$main(void)
{
rt_hw_interrupt_disable();
rtthread_startup();
return 0;
}
先关中断,再做rtt的启动
int rtthread_startup(void)
{
rt_hw_interrupt_disable();
/* board level initalization
* NOTE: please initialize heap inside board initialization.
*/
rt_hw_board_init();
/* show RT-Thread version */
rt_show_version();
/* timer system initialization */
rt_system_timer_init();
/* scheduler system initialization */
rt_system_scheduler_init();
#ifdef RT_USING_SIGNALS
/* signal system initialization */
rt_system_signal_init();
#endif
/* create init_thread */
rt_application_init();
/* timer thread initialization */
rt_system_timer_thread_init();
/* idle thread initialization */
rt_thread_idle_init();
/* start scheduler */
rt_system_scheduler_start();
/* never reach here */
return 0;
}
里面有一些函数是我们自己实现的,比如开发板初始化:rt_hw_board_init,
rtt还是有点好玩的,对外开放了main嘛!我们一般写程序都在main.c中,所以,它又搞了个main_thread_entry线程(其实我更喜欢把这些称作任务,不过都一样啦,既然学了rtt,那就跟官方叫吧)
void main_thread_entry(void *parameter)
{
extern int main(void);
extern int $Super$$main(void);
/* RT-Thread components initialization */
rt_components_init();
/* invoke system main function */
#if defined (__CC_ARM)
$Super$$main(); /* for ARMCC. */
#elif defined(__ICCARM__) || defined(__GNUC__)
main();
#endif
}
这个函数是跳转到我们的main.c中的main。下面才是真正实现我们的代码的地方。
由于前面说了,rtt启动的时候,会将开发板相关资源初始化,所以,我们自己的main就不需要再初始化了,直接开启rtt的线程的创建与启动。
lcd_thread = rt_thread_create("lcd",
lcd_thread_entry,
RT_NULL,
LCD_THREAD_STACK_SIZE,
LCD_THREAD_PRIORITY,
LCD_THREAD_TIMESLICE);
if (lcd_thread != RT_NULL) //创建成功
rt_thread_startup(lcd_thread); //启动线程
else
return -1;
相关宏定义:
#define LCD_THREAD_PRIORITY 13 /* 优先级,数值越大,优先级越低 */
#define LCD_THREAD_STACK_SIZE 1024 /* 线程栈大小,单位为字节 */
#define LCD_THREAD_TIMESLICE 5 /* 线程时间片,单位为tick */
然后就是lcd_thread_entry线程的实现了,这个自己定义就好啦。
既然是评测,当然得有性能的评测啦,一段使用(-O0)低级优化的整形数计算,在野火 i.MX RT1052板载的SDRAM上仅跑了21.487秒。在STM32H743上面跑了21.479秒(400M的工作频率,打开CaChe(高速缓存)),而在stm32f103zet6上跑了9分57秒多。性能可见一斑了吧???如果不信可以自行测试,我可是等了几分钟就去刷牙了,回来还没跑完。。。。。
测试代码如下:(来源网络的测试代码)
void Calculate()
{
unsigned long x;
unsigned long a;
a=1;
for(x=0;x<4294967294;x++)
{
a=a+1;
}
}
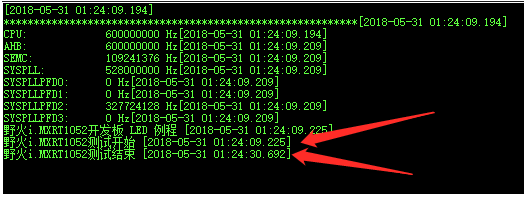
i.MX RT1052
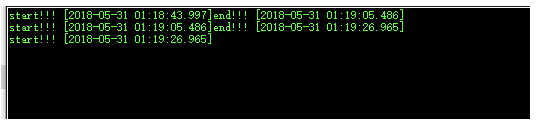
STM32H743

stm32f103zet6

在性能上面, i.MX RT1052,估计是一般mcu无法跨越的存在了,性能真的是超级强悍的。看文章的网友可能有疑问了,明明400M主频的H7比1052快啊,在此杰杰回答一下,1052是在外部SDRAM上的程序,而H7在片内内存上,而且H7开了cache,能不快吗,如果这点小程序在1052的片内内存上跑,绝对飞起。。。。。但是用上这么强的芯片,绝对不会只干这点小程序的活的,到时候跑GUI,你就发现速度了。
据火哥测试, i.MX RT1052的刷屏速度也很快,1366*768分辨率的屏幕可以达到52HZ,而1280*800的屏幕则达到了60HZ,70MHZ左右的VCLK时钟,占用SDRAM的50%左右的数据吞吐量。
-
I.MX RT1052代码执行在哪里?2023-11-09 622
-
RT1052上不了电是为什么?2023-11-08 585
-
如何使用Pendrive通过USB更新i.MX RT1052 EVK上的外部闪存固件?2023-04-11 630
-
RT-Thread文档_野火 I.MX RT1052上手指南2023-02-22 942
-
恩智浦i.MX RTxxx系列MCU的特性2021-11-04 1946
-
求野火I.MX RT1052上手指南?2021-04-02 3449
-
飞凌嵌入式FET1052-C核心板简介2019-11-21 4128
-
转飞凌嵌入式FET1052-C解决方案 实现7.1声道FLAC播放器2018-10-23 1590
-
i.MX RT1052对视频应用的支持2018-09-22 810
-
飞凌嵌入式推出i.MX RT1052跨界开发板2018-08-31 2570
-
野火电子基于RT-Thread的i.MX RT1052 EVK Pro板卡特点介绍2018-07-16 10532
-
emWin介绍和emWin开发的详细资料概述2018-06-12 69382
-
基于M1052核心板多种物联网解决方案供您选择2018-04-06 10237
全部0条评论

快来发表一下你的评论吧 !
