

RISC-V CPU 上 3 倍推理加速!V-SEEK:在 SOPHON SG2042 上加速 14B LLM
描述
关键词:V-SEEK、LLM Inference Optimization、RISC-V、SOPHON SG2042、llama.cpp、NUMA Optimization

- V-SEEK: ACCELERATING LLM REASONING ON OPEN-HARDWARE SERVER-CLASS RISC-V PLATFORMS
近年来,大型语言模型(LLM)的指数级增长依赖于基于 GPU 的系统。然而,CPU 正逐渐成为一种灵活且成本更低的替代方案,尤其是在面向推理(inference,即模型已完成训练、仅做预测的阶段)和推理负载(reasoning workloads,指需要多步逻辑推导的预测任务)时。
RISC-V(一种开源、免授权、可自由定制的指令集架构)凭借开放且与厂商无关的 ISA(Instruction Set Architecture,指令集架构)在该领域迅速受到关注。
然而,面向 LLM 负载的 RISC-V 硬件及其配套软件生态尚未完全成熟和流畅,原因是需要对特定领域进行调优。
本文旨在填补这一空白,聚焦于在 SOPHON SG2042 上优化 LLM 推理;SG2042 是首款商用、具备向量处理能力的多核 RISC-V CPU。
在两个新近为推理优化的 SOTA(state-of-the-art,业界最佳)开源 LLM——DeepSeek R1 Distill Llama 8B 与 DeepSeek R1 Distill QWEN 14B——上,我们实现了:
- token 生成(token generation,逐词生成)4.32 / 2.29 token/s
- 提示处理(prompt processing,又称 prefill,把整段输入一次性算完)6.54 / 3.68 token/s 的吞吐,相比我们的基线实现最高加速达 2.9× / 3.0×。
本文目录
- 本文目录
- 一、引言
- 二、研究方法
- 2.1 高性能 Kernel
- 2.2 编译器工具链
- 2.3 模型映射优化
- 三、实验结果与分析
- Kernel Scaling
- 不同编译器影响
- NUMA 策略影响
- 性能小结
- 参考文献
一、引言
超大规模云服务商(hyperscalers,例如 AWS)与 AI 部署公司(例如 OpenAI)通常使用 GPU 集群或专用加速器(如 TPU,Tensor Processing Unit)来加速 LLM 工作负载。然而,多核 CPU 加速 LLM 也已得到近期探索 [2],因为它在硬件成本更低的同时提供了更高的灵活性,尤其适用于本地部署(on-premise)和低延迟边缘服务器(edge servers)。
现有研究主要针对 x86 和 ARM,而基于灵活且开源的 RISC-V 指令集架构的多核芯片则相对未被充分探索 [1]。
为了填补这一空白,本工作将业界先进的 LLM 推理框架 llama.cpp [7] 适配并优化到首款商用的、通用型多核 RISC-V 平台——SOPHON SG2042 [1]。
在两个新近开源、专为推理优化的模型(DeepSeek R1 Distill Llama 8B / QWEN 14B)上,我们相比基线 llama.cpp 实现最高实现了 token 生成 3.0×、提示处理 2.8× 的加速(在 4-bit 量化精度下),分别达到 4.32 / 2.29 与 6.54 / 3.68 token/s 的吞吐。
在 vanilla Llama 7B 上,我们实现 token 生成 6.63 token/s、提示处理 13.07 token/s,即相比基线实现加速 4.3× / 5.5×,并较 SG2042 上已报道的最佳结果 [8] 提升 1.65×,同时与成熟的 x86 CPU 推理性能具有竞争力。
二、研究方法
为了探索在 RISC-V 服务器级平台上优化 LLM 推理的可用选项,我们选定了 MILK-V Pioneer 作为目标平台,其核心为 64 核 SOPHON SG2042 CPU,并配备 128 GB DRAM 内存。平台框图见图 1-center。

我们识别出可以从三个方向着手解决问题的路径,均在软件层面,灵感来自其他架构上的相关工作 [5,6,3]:
2.1 高性能 Kernel
针对关键 LLM 层开发经过优化的、若支持则已量化的计算内核(kernels,指一段专门用于矩阵运算的底层代码),充分利用硬件资源,同时兼顾其内存结构、流水线(pipeline,指令执行顺序)和向量化能力。
图 1-right 给出了我们提出的内核的伪代码:
- 首先,将 fp32(32 位浮点)输入(向量或瘦矩阵)量化为 int8(8 位整数);
- 接着,执行两层嵌套循环以完成 GEMV(General Matrix-Vector multiplication,通用矩阵-向量乘法)操作,其中外层循环按步长 2 遍历输入矩阵 A 的行,内层循环按步长 32 遍历其列。
- 列循环结束后,进行反量化(de-quantization,把整数还原回浮点数),结合 A 块和 B 的缩放因子(scale factors)以生成输出的 fp32 值。
这一新内核既利用了平台的向量单元,又优化了数据局部性(data locality,数据尽量靠近计算单元,减少访存延迟)。
2.2 编译器工具链
选择合适的编译工具链,支持先进的优化 Pass(optimization passes,编译器内部对代码进行变换以提升性能的阶段)并能利用现有 ISA 扩展。
在我们的场景下,内核使用 Xuantie 分支的 GCC 10.4 编译,因为只有该版本支持 Sophon SG2042 的硬件向量单元。而对于整个 llama.cpp 框架,我们考虑两种替代方案:GCC 13.2 和 Clang 19(Xuantie GCC 10.4 与最新版 llama.cpp 不兼容)。
2.3 模型映射优化
优化模型映射(model mapping,即把模型权重和计算任务分配到硬件上的过程),特别是页面/线程分配,解决这类系统复杂的内存层级结构。具体而言,我们针对非一致内存访问(NUMA,Non-uniform Memory Access,指多路服务器中 CPU 访问远/近内存速度不同的架构)延迟,探索了不同 numactl 选项组合的 4 种策略:
- NUMA Balancing 开启,其余选项关闭;
- 所有选项关闭;
- Balancing 关闭 + Core Binding(核心绑定)开启;
- Balancing 关闭 + Memory Interleaving(内存交错)开启。
我们将上述优化应用于 llama.cpp [7] 框架,并在 3 个规模递增的开源 LLM 上进行测试,均采用 Q4_0 量化(vanilla Llama 7B,DeepSeek R1 Distill Llama 8B,DeepSeek R1 Distill QWEN 14B,分别简称 7B、8B 和 14B)。
三、实验结果与分析
为展示优化效果,我们用用户提示 “Explain to me what is RISC-V, what are its principles and why it is so cool?”(共 22 个 token)对三款 LLM 执行了预填充(prefill),同时对 token 生成性能取 256 个测试生成 token 的平均值。
Kernel Scaling
图 2 给出了多个基线内核(llama.cpp 自带的 GGML 与 OpenBLAS 默认实现)与我们所提出内核的单线程可扩展性对比。
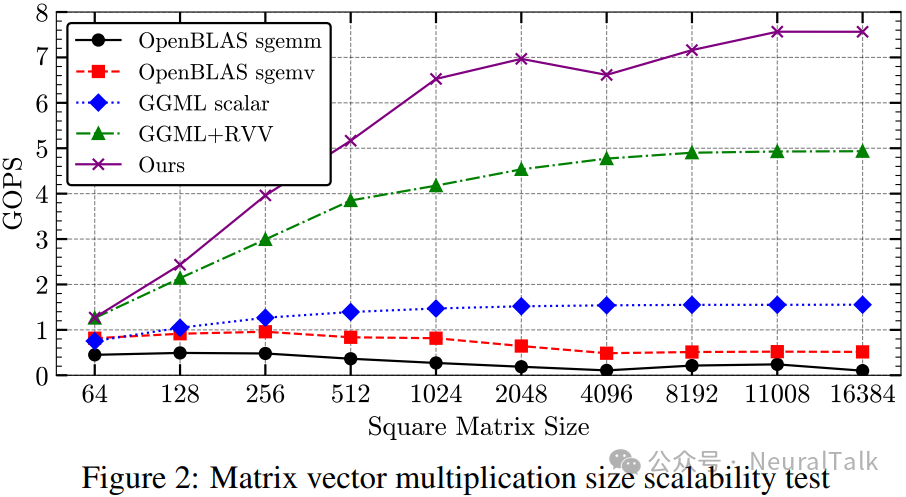
与最佳基线相比,我们平均将 GOPS(Giga Operations Per Second,十亿次运算每秒)提升 38.3%,在矩阵规模为 4096 时峰值提升达 56.3%。
不同编译器影响
图 3 评估了使用 Clang 或 GCC 编译时 DeepSeek 8B 模型的推理性能,均使用我们提出的内核。
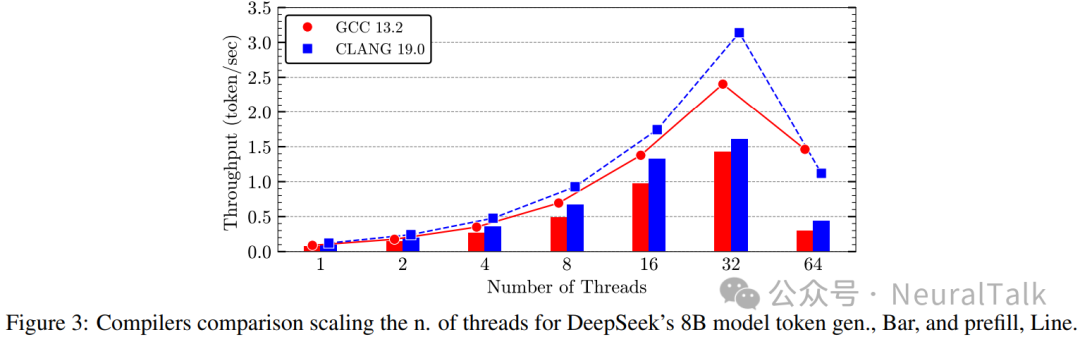
Clang 19 持续优于 GCC 13.2,在 token 生成上平均性能提升 34%,在预填充上提升 25%。关键原因在于 Clang 对 ISA 扩展的支持以及更先进的编译优化(例如更激进的内联和循环展开)。无论使用哪种编译器,当线程数超过 32 时都会出现性能下降。该行为归因于默认的 NUMA balancing 策略,它对 LLM 推理这种可预测负载并不理想,导致大量线程与内存页迁移。
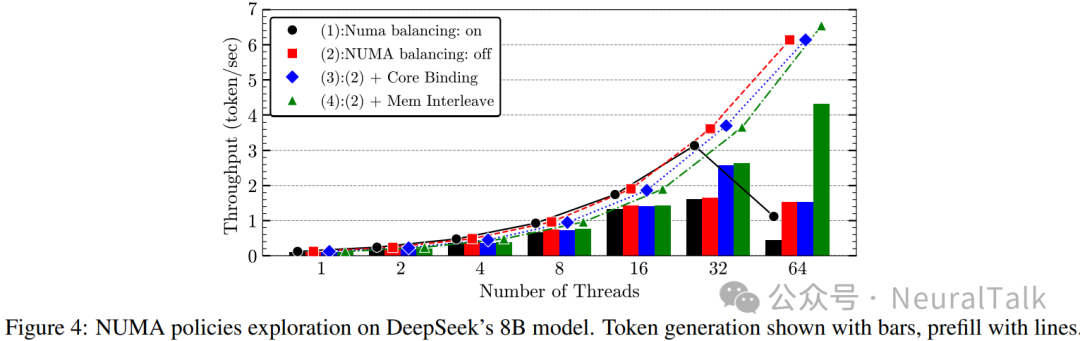
NUMA 策略影响
事实上,在关闭 NUMA balancing 并开启内存交错后,如预期所示,我们在 64 线程下取得了 token 生成 4.32 token/s 与预填充 6.54 token/s 的最佳结果,这得益于内存页迁移的大幅减少。
性能小结
得益于我们的优化,7B、8B 和 14B 这三款 LLM 分别达到了 13.07 / 6.54 / 3.68 token/s 的最大吞吐,相比基线 llama.cpp 最高提升 5.5× / 2.9× / 3×。
- 与 SG2042 上已报道的最佳结果 [8] 相比,我们在 Llama 7B 上的峰值吞吐提升 1.65×。
- 与类似且更成熟的 x86 平台——64 核 AMD EPYC 7742——相比,我们将能效提升 1.2×(55 token/s/mW 对 45 token/s/mW)。
参考文献

-
RISC-V HPC新标杆Sophon SG2044深度评估:支持RVV v1.0适配GCC 15.2,多核性能潜力巨大!2025-10-16 2117
-
首款RISC-V架构服务器,助力行业精准适配AI场景2025-02-28 2074
-
算能 SG2042 / Milk-V Pioneer 的含金量还在不断提升:RISC-V 生态逐步完善,玩大型游戏已经不远了!2024-11-01 1482
-
RISC-V跑AI算法能加速吗?2024-10-10 9792
-
晶心科技与Arteris合作加速RISC-V的SoC设计创新2024-05-30 2383
-
RISC-V强势崛起为芯片架构第三极2023-08-30 831
-
RISC-V公测平台发布·如何在SG2042上玩转k3s2023-07-31 2658
-
RISC-V,正在摆脱低端2023-05-30 2161
-
openEuler RISC-V 23.03 创新版本亮相:全面提升硬件兼容性和桌面体验2023-04-14 2124
-
openEuler成功适配SG2042服务器板卡加速软件包构建2023-04-12 2641
-
算能重磅发布行业首款服务器级RISC-V CPU算丰SG20422023-03-30 5061
-
RISC-V联盟年会看点回顾 2023年是RISC-V高性能计算元年2023-03-14 3606
-
高清无码:2023年玄铁RISC-V生态大会,算能SG2042与澎峰科技的高性能计算型服务器共同亮相2023-03-03 10438
全部0条评论

快来发表一下你的评论吧 !
