

小样本学习领域的研究进展
电子说
描述
编者按:子曰:“举一隅不以三隅反,则不复也”。
人类从少量样本中去思考,还能用这个做什么;而机器则是见到了上亿的数据,却希望下一个与之前的相似。
在机器学习领域中,随着更多应用场景的涌现,我们越来越面临着样本数量不足的问题。因此,如何通过举一反三的方式进行小样本学习,成为了一个重要的研究方向。
本文中,复旦大学的付彦伟教授,将介绍过去一年中小样本学习领域的研究进展。
文末,大讲堂提供文中提到参考文献的下载链接。

本次报告主要回顾one-shot learning,也可以称为few-shot learning或low-shot learning领域最近的进展。

首先,one-shot learning产生的动机大家都比较了解。现在在互联网,我们主要用large-scale方法处理数据,但真实情况下,大部分类别我们没有数据积累,large-scale方法不完全适用。所以我们希望在学习了一定类别的大量数据后,对于新的类别,我们只需要少量的样本就能快速学习。
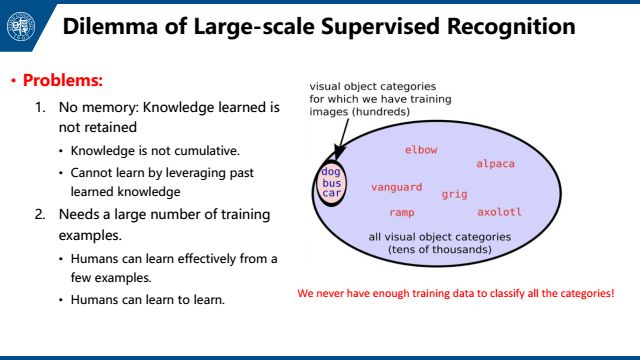
存在的问题一方面是知识缺失,另一方面是需要大量的训练样本。第一点在本文中不做讨论。

对于第二点,目前考虑的解决方法主要有两个:
第一个是人能够识别一个从没有见过的物体,也就是zero-shot learning;
第二个是从已有任务中学习知识,将其应用到未来模型训练中,可以认为是一个迁移学习的问题。

那么我们如何定义one-shot learning呢? 它的目的是从一个或几个图像样本中学习类别信息。但我们这里的one-shot learning并不限于一般图像,也可以在文本,医疗图像等特殊图像,或者物理化学中的扫描图像上进行应用。

One-shot learning的研究主要分为如下几类:
第一类方法是直接基于有监督学习的方法,这是指没有其他的数据源,不将其作为一个迁移学习的问题看待,只利用这些小样本,在现有信息上训练模型,然后做分类;
第二个是基于迁移学习的方法,是指有其他数据源时,利用这些辅助数据集去做迁移学习。这是我今年一篇综述里提到的模型分类。

对于第一类直接进行有监督学习的方法,可以做基于实例的学习,比如KNN,以及非参数方法。

而基于迁移学习的one-shot learning,首先是基于属性的学习,比如我们最早在做zero-shot learning的时候,会顺便做one-shot learning,把特征投影到一个属性空间,然后在这个属性空间中既可以做one-shot learning,又可以做zero-shot learning,但是每个类别都需要属性标注,也就是需要额外的信息。最近的机器学习领域里,所讨论one-shot learning一般不假设我们知道这些额外信息,大体上可以被分为meta-learning,或者metric-learning。 Meta-learning从数据中学习一种泛化的表示,这种泛化的表示可以被直接用于目标数据上,小样本的类别学习过程。Metric-learning从数据源中构建一个空间。但是本质上meta-learning和metric-learning还是有很多相似的地方。

接下来是数据增强,这其实是很重要也很容易被忽视的一点,可以有很多方法来实现:
第一,利用流信息学习one-shot模型,常见的有半监督学习和transductive learning,探讨的是如何用无标签数据去做one-shot learning。
第二,在有预训练模型时,用这些预训练模型进行数据增强。
第三,从相近的类别借用数据,来增强训练数据集。
第四,合成新的有标签训练数据,用一些遥感里的方法,可以合成一些图像,或者3d物体。
第五,用GAN来学习合成模型,比如最近用GAN来做personal ID和人脸相关研究。
第六,属性引导的增强方法。具体大家可以在文章里进行详细了解。
首先基于迁移学习的方法,我们目前的实验结果显示:大部分已经发表的one-shot learning方法在miniImageNet数据集上的结果,比不过resnet-18的结果,这也是很微妙的一点。我们的代码已经放到github上,大家有兴趣可以看一下。(如果我们的实验在什么地方有问题,欢迎大家给我发邮件)
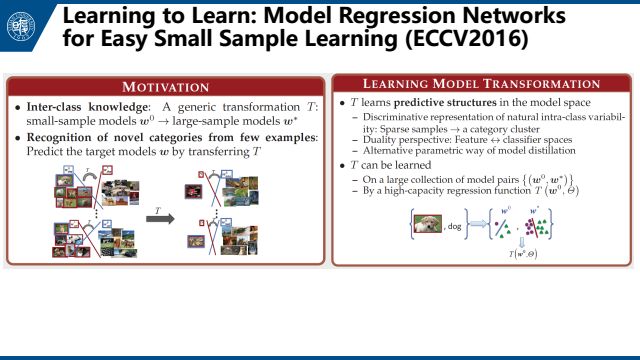
下面简单介绍相关文章。首先是Wang Yuxiong的文章Learning to Learn: Model Regression Networks for Easy Small Sample Learning,他们用原数据构建了很多模型库,然后目标数据直接回归这些模型库。具体就是在source class上训练一个regression network。对于大量样本我们可以得到一个比较好的分类器。对于少量样本我们可以得到一个没那么好的分类器。这个regression network的目的就是把没那么好的分类器映射成比较好的分类器。即,把一个分类器的权重映射到另一个分类器。
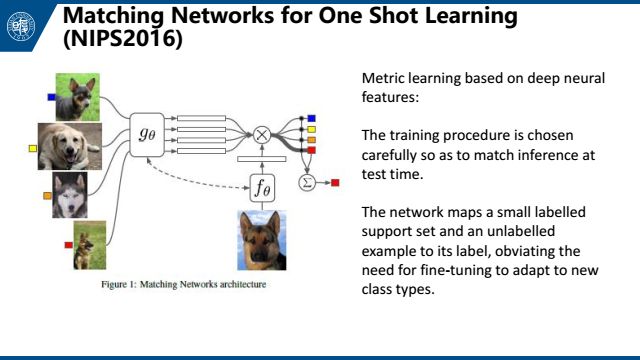
第二个是Matching Networks for One Shot Learning,这个文章很有意思,从标题中就能读出大概做了什么工作。对于一张图片,我们训练一个matching network来提取它的feature。然后用一个简单的数学公式来判断feature之间的距离。对于新的图片,根据它与已知图片的距离来进行分类。这篇文章精巧地设计了训练的过程,来使得这个过程与测试时的过程一致。
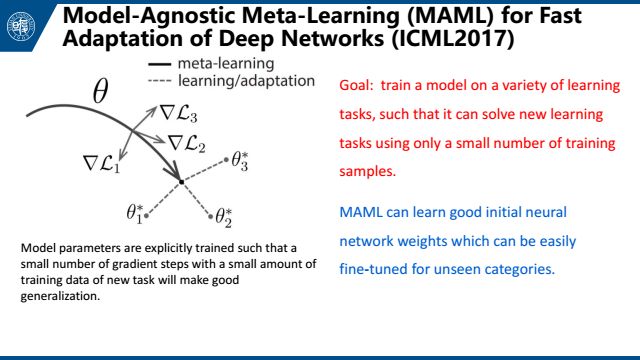
第三是MAML,是与模型无关的meta-learning的方法,它主要侧重于深度网络的快速适应。这篇文章的思想就是找到一个网络最好的初始位置,这个初始位置被定义为:经过几个小样本的调整后可以得到最好的表现。
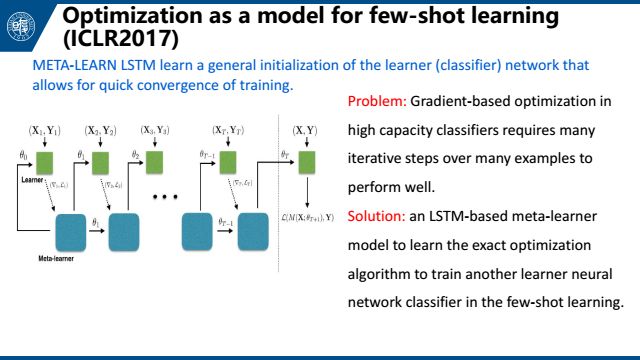
第四个是Optimization as a model for few-shot learning,也是meta-learning的方法,将任务组织成一个最优化的问题。这篇文章将梯度下降的过程与LSTM的更新相对比,发现它们非常相似。所以可以用LSTM来学习梯度下降的过程,以此使用LSTM来做梯度下降的工作。
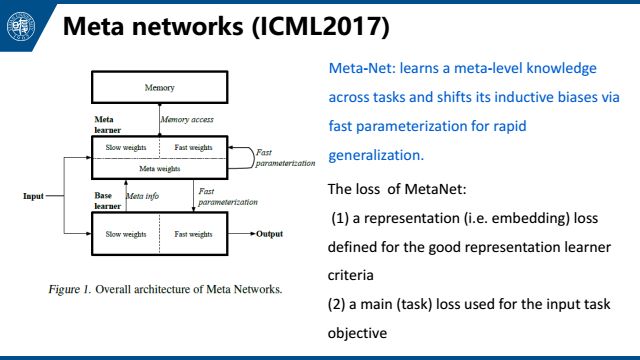
第五个是meta networks,也是meta-learning方法。其中利用了少量样本在基础网络中产生的梯度,来快速生成新的参数权重。
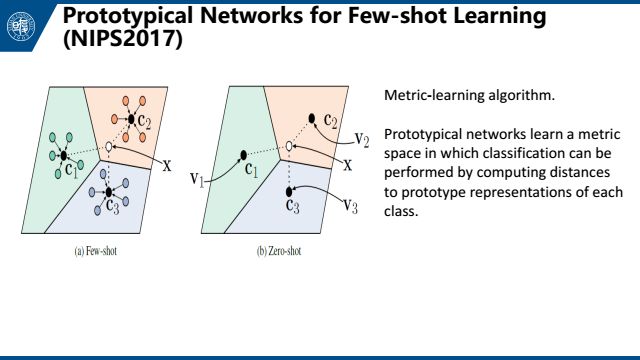 今年NIPS一篇prototypical network,主要是在matching networks的基础上做了一些更改。它们给每一个类一个原型,样本与类的距离就是样本与原型的距离。然后选用欧氏距离替代了matching network的余弦距离。
今年NIPS一篇prototypical network,主要是在matching networks的基础上做了一些更改。它们给每一个类一个原型,样本与类的距离就是样本与原型的距离。然后选用欧氏距离替代了matching network的余弦距离。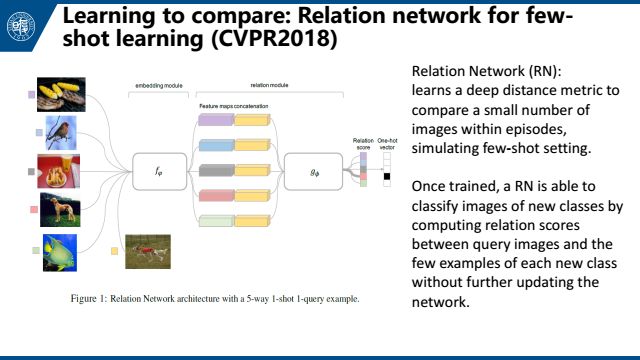
今年CVPR的Learning to compare: Relation network for few-shot learning。简单来说就是用embedding module来提取feature。然后用relation module来输出两个feature之间的距离。一次来通过距离进行分类选择。

关于on-shot learning,还有其他参考文献,可在文末的链接中下载。
下面简单介绍一下数据增强的相关文章。
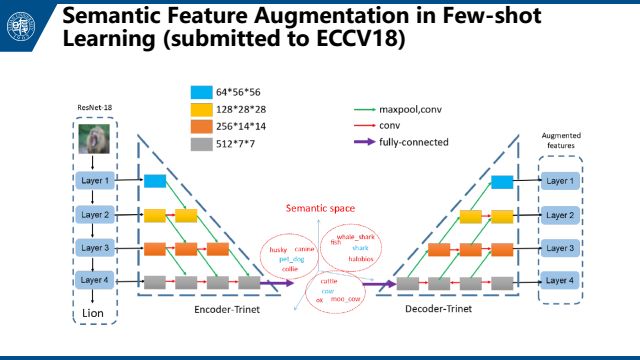
上图是我们今年的提交到ECCV的一个工作,用左边的encoder-trinet把视觉特征映射到语义空间。因为语义空间上有更丰富的信息,可以在语义空间上做数据扩充(添加高斯噪声和寻找最近邻),再映射回视觉空间来得到更多的扩充样例。

ICCV2017这篇文章根据已有的图像去生成新的图像,然后做low-shot 视觉识别。具体来说,比如说你有三张图片:一张是鸟,一张是鸟站在树枝上,一张是猴子。那么你可以学习一个网络让它生成猴子站在树枝上的图片。本质上是,想把一个类的变化迁移到另一个类上,以此来做数据扩充。
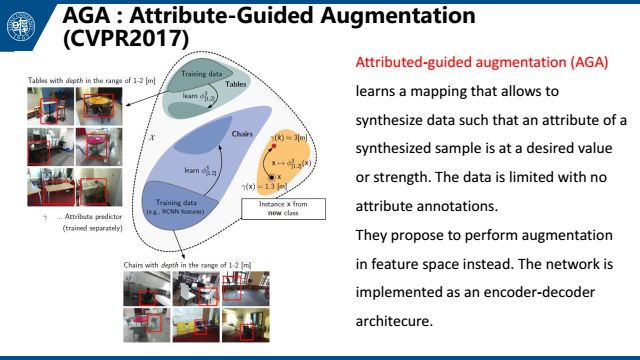
这是去年在CVPR上发表的文章AGA,主要针对3D数据,把图像投影到一个属性空间做数据增强。这是一个few-shot learning方法。具体就是,给定几张距离观测者不同距离的桌子的照片,以及一张凳子的照片,让机器学会如何去生成不同距离的凳子的照片,以此来做数据扩充。
最后在 one-shot learning之上,我们还可能遇到一个问题,one-shot learning只关注目标类别上的分类问题,我们希望学习到的模型对源数据类别也适用,否则将带来一个问题,被称为灾难性遗忘。
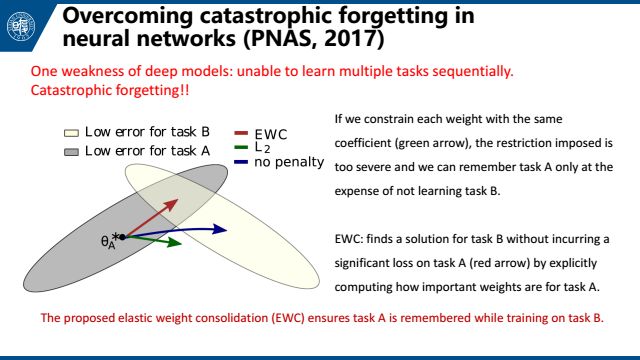
发表在PNAS的文章提出EWC 模型来解决这个问题。灾难性遗忘往往源于我们学习任务B的时候更新网络,使得任务A做的没那么好了。EWC提供了一种方法来计算权重对于任务A的重要性,把重要性引入到损失函数中,来避免更改会影响A效果的权重。
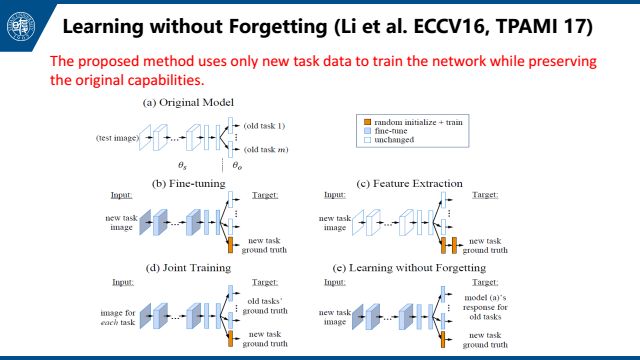
还有learning without forgetting这篇文章,也是侧重于解决这个问题。简单来说就是拿到一个新任务后,我们会更新网络。我们希望在更新网络前后网络没有太大变化,所以我们添加一个loss来限制网络更新前后对于这个新的任务输出的特征不能有太大变化,也就是一个distill loss。
最后,小样本学习还有很多可以研究的东西。目前的成果主要还是基于把已知类别的一些信息迁移到新的类别上。可能未来可以尝试下更多的方向,比如利用无监督的信息或者是半监督的方法。
- 相关推荐
- 热点推荐
- 机器学习
-
新技术在生物样本冷冻中的应用案例分析2023-12-26 3835
-
新型铜互连方法—电化学机械抛光技术研究进展2009-10-06 7185
-
室内颗粒物的来源、健康效应及分布运动研究进展2010-03-18 3519
-
薄膜锂电池的研究进展2011-03-11 2966
-
太赫兹量子级联激光器等THz源的工作原理及其研究进展2019-05-28 2475
-
声频定向扬声器的研究进展2010-01-08 854
-
物联网隐私保护研究进展2016-03-24 660
-
高维小样本分类问题中特征选择研究综述2017-11-27 867
-
无人车领域的主要研究进展分析2018-10-28 9464
-
答疑解惑探讨小样本学习的最新进展2020-05-12 4723
-
深度学习:小样本学习下的多标签分类问题初探2021-01-07 8158
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3050
-
一种基于伪标签半监督学习的小样本调制识别算法2022-02-10 1356
-
IPMT:用于小样本语义分割的中间原型挖掘Transformer2022-11-17 1541
-
小样本学习领域的未来发展方向2023-06-14 1712
全部0条评论

快来发表一下你的评论吧 !
