

用 ERNIE 4.5 与 PaddleOCR 3.0 实现文档翻译实践指南
电子说
描述
一, 文档翻译的挑战
在全球化背景下,跨语言沟通需求日益增长,文档翻译的重要性愈发凸显。尤其是随着数字化进程加速,文档图像翻译的需求持续上升,但这一任务面临着独特的挑战:复杂布局解析
文档图像常包含文本、图表、表格等多种元素,传统OCR技术在处理复杂布局时难以准确提取文本并保留原始格式多语言翻译质量
不同语言间存在语法、词汇和文化背景差异,长句和上下文依赖翻译任务对传统工具而言颇具难度格式保留
翻译过程中如何保持文档的原始结构和格式,是用户面临的另一大痛点
你是否曾因这些问题而困扰?本文将介绍如何利用PaddleOCR 3.0
https://github.com/paddlepaddle/paddleocr
和ERNIE 4.5
https://github.com/PaddlePaddle/ERNIE
实现高质量的文档翻译解决方案。
二,PaddleOCR 3.0与ERNIE 4.5简介
PaddleOCR 3.0
PaddleOCR 3.0是业界领先、可直接部署的 OCR 与文档智能引擎,提供从文本识别到文档理解的全流程解决方案,提供了全场景文字识别模型PP-OCRv5、复杂文档解析PP-StructureV3和智能信息抽取PP-ChatOCRv4,其中PP-StructureV3在布局区域检测、表格识别和公式识别方面能力尤为突出,还增加了图表理解、恢复多列阅读顺序以及将结果转换为Markdown文件的功能。
ERNIE 4.5
ERNIE 4.5是百度发布的开源多模态和大语言系列,含10种版本,最大达424B参数,采用创新MoE架构,支持跨模态共享与专用参数,在文本与多模态任务中表现领先。通过结合PP-StructureV3的文档分析能力和ERNIE 4.5的翻译能力,我们可以构建一个端到端的高质量文档翻译解决方案。
三,解决方案概述
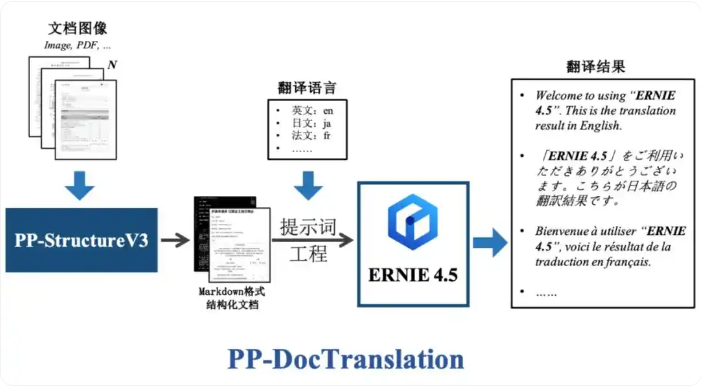
本文介绍的文档翻译方案基于以下核心流程:
1,使用PP-StructureV3分析文档内容,获取结构化数据表示
2,将结构化数据处理为Markdown格式的文档文件
3,利用提示工程构建提示,调用ERNIE 4.5翻译文档内容
这种方法不仅能准确识别和分析复杂文档布局,还能实现高质量的多语言翻译服务,满足用户在不同语言环境下的文档翻译需求。
四,快速上手
步骤1:环境准备
首先需要安装PaddlePaddle框架和PaddleOCR:
# 安装PaddlePaddle GPU版本 python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/ # 安装PaddleOCRpip install paddleocr # 安装OpenAI SDK用于测试模型可用性 pip install openai
步骤2:部署ERNIE 4.5服务
ERNIE大语言模型通过服务请求访问,需要部署为本地服务。可以使用FastDeploy工具部署ERNIE模型。部署完成后,测试服务可用性:
# 测试ERNIE服务可用性
# 请填写本地服务的URL,例如:http://0.0.0.0:8000/v1
ERNIE_URL = ""
try:
import openai
client = openai.OpenAI(base_url=ERNIE_URL, api_key="api_key")
question = "你是谁?"
response1 = client.chat.completions.create(
model="ernie-4.5", messages=[{"role": "user", "content": question}]
)
reply = response1.choices[0].message.content
print(f"测试成功!n问题:{question}n回答:{reply}")
except Exception as e:
print(f"测试失败!错误信息:n{e}")
步骤3:文档解析与翻译
# 文档翻译示例代码
from paddleocr import PPDocTranslation
# 配置参数
input_path = "path/to/your/document.pdf" # 文档图像路径
output_path = "./output/" # 结果保存路径
target_language = "zh" # 目标语言(中文)
# 初始化PP-DocTranslation pipeline
translation_engine = PPDocTranslation(
use_doc_orientation_classify=False, # 是否使用文档方向分类模型
use_doc_unwarping=False, # 是否使用文档扭曲校正模型
use_seal_recognition=True, # 是否使用印章识别模型
use_table_recognition=True # 是否使用表格识别模型
)
# 解析文档图像
visual_predict_res = translation_engine.visual_predict(input_path)
# 处理解析结果
ori_md_info_list = []
for res in visual_predict_res:
layout_parsing_result = res["layout_parsing_result"]
ori_md_info_list.append(layout_parsing_result.markdown) layout_parsing_result.save_to_img(output_path) layout_parsing_result.save_to_markdown(output_path)# 如果是PDF文件,拼接多页结果if input_path.lower().endswith(".pdf"): ori_md_info = translation_engine.concatenate_markdown_pages(ori_md_info_list)
ori_md_info.save_to_markdown(output_path)
# 配置ERNIE服务
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-4.5",
"base_url": ERNIE_URL, # 填写ERNIE服务URL
"api_type": "openai",
"api_key": "api_key"
}
# 调用ERNIE进行翻译
print("开始翻译文档...")
tgt_md_info_list = translation_engine.translate(
ori_md_info_list=ori_md_info_list,
target_language=target_language,
chunk_size=3000, # 文本分块大小
chat_bot_config=chat_bot_config,
)
# 保存翻译结果
for tgt_md_info in tgt_md_info_list:
tgt_md_info.save_to_markdown(output_path)
print(f"翻译完成,结果保存在:{output_path}")
完成代码范例,请参见Document Translation Practice Based on ERNIE 4.5 and PaddleOCR。
https://github.com/PaddlePaddle/ERNIE/blob/develop/cookbook/notebook/document_translation_tutorial_en.ipynb
五,运行示例翻译结果
下图展示了翻译效果示例(左侧为原始英文PDF论文图像,右侧为翻译后的中文Markdown文件):

六,常见问题与调试
常见问题
1,Q: 安装PaddlePaddle时遇到CUDA版本不匹配问题? A: 请确保CUDA版本与PaddlePaddle版本兼容。可以参考PaddlePaddle官方安装指南选择合适的版本。
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
2,Q: 调用ERNIE服务时出现连接超时?A: 检查ERNIE服务是否正常运行,网络连接是否畅通。可以尝试重启服务或增加超时设置。
3,Q: 文档解析结果中表格格式丢失?A: 确保use_table_recognition参数设置为True。对于复杂表格,可能需要调整表格识别模型的参数。
4,Q: 翻译结果质量不高?A: 尝试调整chunk_size参数,确保文本块大小合适。对于专业领域文档,可以提供领域词汇表作为提示的一部分。
调试技巧逐步验证
1,从单页简单文档开始测试,确认每个步骤正常工作后再处理复杂文档日志输出
2,在关键步骤添加日志,记录处理时间和结果状态版本兼容
3,确保PaddlePaddle、PaddleOCR和其他依赖库的版本兼容可视化检查
4,利用save_to_img功能保存解析过程中的图像,直观检查问题所在
七,总结
通过本文介绍的方法,你可以快速构建一个高质量的文档翻译系统,满足不同场景下的文档翻译需求。无论是学术论文、技术文档还是商业报告,都能得到准确、流畅的翻译结果。该系统能够处理复杂的文档结构,如表格、图表等,同时保持翻译质量。
审核编辑 黄宇
- 相关推荐
- 热点推荐
- 语言模型
-
登临科技GPU+架构深度适配PaddleOCR-VL-1.6模型2026-06-04 1927
-
百度正式发布并开源新一代文档解析模型PaddleOCR-VL-1.52026-01-30 1098
-
使用 Docker 一键部署 PaddleOCR-VL: 新手保姆级教程2025-12-18 7428
-
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析2025-08-29 4129
-
用逻辑和翻译用例优化资产跟踪器2024-09-21 516
-
ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本2023-02-22 2803
-
三步骤快速实现PaddleOCR实时推理2022-06-09 6264
-
随身翻译机怎么选?讯飞翻译机3.0多语种翻译值得信赖2021-11-30 1055
-
语言翻译技术一流的智能翻译机-讯飞翻译机3.02020-08-18 2372
-
AliOS Things 3.0 入门与实践:视频教程+学习笔记2019-10-21 5173
-
Keysight License Manager 3.0在线文档2019-10-09 3651
-
中文预训练模型ERNIE使用指南2019-08-02 7292
-
机器学习实践指南——案例应用解析2018-04-13 2347
-
高速PCB布线实践指南2012-08-20 22602
全部0条评论

快来发表一下你的评论吧 !
