

机器学习实用指南——多类分类与误差分析
电子说
描述
多类分类
二分类器只能区分两个类,而多类分类器(也被叫做多项式分类器)可以区分多于两个类。
一些算法(比如随机森林分类器或者朴素贝叶斯分类器)可以直接处理多类分类问题。其他一些算法(比如 SVM 分类器或者线性分类器)则是严格的二分类器。然后,有许多策略可以让你用二分类器去执行多类分类。
举例子,创建一个可以将图片分成 10 类(从 0 到 9)的系统的一个方法是:训练10个二分类器,每一个对应一个数字(探测器 0,探测器 1,探测器 2,以此类推)。然后当你想对某张图片进行分类的时候,让每一个分类器对这个图片进行分类,选出决策分数最高的那个分类器。这叫做“一对所有”(OvA)策略(也被叫做“一对其他”)。
另一个策略是对每一对数字都训练一个二分类器:一个分类器用来处理数字 0 和数字 1,一个用来处理数字 0 和数字 2,一个用来处理数字 1 和 2,以此类推。这叫做“一对一”(OvO)策略。如果有 N 个类。你需要训练N*(N-1)/2个分类器。对于 MNIST 问题,需要训练 45 个二分类器!当你想对一张图片进行分类,你必须将这张图片跑在全部45个二分类器上。然后看哪个类胜出。OvO 策略的主要有点是:每个分类器只需要在训练集的部分数据上面进行训练。这部分数据是它所需要区分的那两个类对应的数据。
一些算法(比如 SVM 分类器)在训练集的大小上很难扩展,所以对于这些算法,OvO 是比较好的,因为它可以在小的数据集上面可以更多地训练,较之于巨大的数据集而言。但是,对于大部分的二分类器来说,OvA 是更好的选择。
Scikit-Learn 可以探测出你想使用一个二分类器去完成多分类的任务,它会自动地执行 OvA(除了 SVM 分类器,它使用 OvO)。让我们试一下SGDClassifier.
>>> sgd_clf.fit(X_train, y_train) # y_train, not y_train_5 >>> sgd_clf.predict([some_digit]) array([ 5.])
很容易。上面的代码在训练集上训练了一个SGDClassifier。这个分类器处理原始的目标class,从 0 到 9(y_train),而不是仅仅探测是否为 5 (y_train_5)。然后它做出一个判断(在这个案例下只有一个正确的数字)。在幕后,Scikit-Learn 实际上训练了 10 个二分类器,每个分类器都产到一张图片的决策数值,选择数值最高的那个类。
为了证明这是真实的,你可以调用decision_function()方法。不是返回每个样例的一个数值,而是返回 10 个数值,一个数值对应于一个类。
>>> some_digit_scores = sgd_clf.decision_function([some_digit]) >>> some_digit_scores array([[-311402.62954431, -363517.28355739, -446449.5306454 , -183226.61023518, -414337.15339485, 161855.74572176, -452576.39616343, -471957.14962573, -518542.33997148, -536774.63961222]])
最高数值是对应于类别 5 :
>>> np.argmax(some_digit_scores) 5 >>> sgd_clf.classes_ array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.]) >>> sgd_clf.classes[5] 5.0
一个分类器被训练好了之后,它会保存目标类别列表到它的属性classes_ 中去,按照值排序。在本例子当中,在classes_ 数组当中的每个类的索引方便地匹配了类本身,比如,索引为 5 的类恰好是类别 5 本身。但通常不会这么幸运。
如果你想强制 Scikit-Learn 使用 OvO 策略或者 OvA 策略,你可以使用OneVsOneClassifier类或者OneVsRestClassifier类。创建一个样例,传递一个二分类器给它的构造函数。举例子,下面的代码会创建一个多类分类器,使用 OvO 策略,基于SGDClassifier。
>>> from sklearn.multiclass import OneVsOneClassifier >>> ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42)) >>> ovo_clf.fit(X_train, y_train) >>> ovo_clf.predict([some_digit]) array([ 5.]) >>> len(ovo_clf.estimators_) 45
训练一个RandomForestClassifier同样简单:
>>> forest_clf.fit(X_train, y_train) >>> forest_clf.predict([some_digit]) array([ 5.])
这次 Scikit-Learn 没有必要去运行 OvO 或者 OvA,因为随机森林分类器能够直接将一个样例分到多个类别。你可以调用predict_proba(),得到样例对应的类别的概率值的列表:
>>> forest_clf.predict_proba([some_digit]) array([[ 0.1, 0. , 0. , 0.1, 0. , 0.8, 0. , 0. , 0. , 0. ]])
你可以看到这个分类器相当确信它的预测:在数组的索引 5 上的 0.8,意味着这个模型以 80% 的概率估算这张图片代表数字 5。它也认为这个图片可能是数字 0 或者数字 3,分别都是 10% 的几率。
现在当然你想评估这些分类器。像平常一样,你想使用交叉验证。让我们用cross_val_score()来评估SGDClassifier的精度。
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy") array([ 0.84063187, 0.84899245, 0.86652998])
在所有测试折(test fold)上,它有 84% 的精度。如果你是用一个随机的分类器,你将会得到 10% 的正确率。所以这不是一个坏的分数,但是你可以做的更好。举例子,简单将输入正则化,将会提高精度到 90% 以上。
>>> from sklearn.preprocessing import StandardScaler >>> scaler = StandardScaler() >>> X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) >>> cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy") array([ 0.91011798, 0.90874544, 0.906636 ])
误差分析
当然,如果这是一个实际的项目,你会在你的机器学习项目当中,跟随以下步骤(见附录 B):探索准备数据的候选方案,尝试多种模型,把最好的几个模型列为入围名单,用GridSearchCV调试超参数,尽可能地自动化,像你前面的章节做的那样。在这里,我们假设你已经找到一个不错的模型,你试图找到方法去改善它。一个方式是分析模型产生的误差的类型。
首先,你可以检查混淆矩阵。你需要使用cross_val_predict()做出预测,然后调用confusion_matrix()函数,像你早前做的那样。
>>> y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)>>> conf_mx = confusion_matrix(y_train, y_train_pred)>>> conf_mx array([[5725, 3, 24, 9, 10, 49, 50, 10, 39, 4], [ 2, 6493, 43, 25, 7, 40, 5, 10, 109, 8], [ 51, 41, 5321, 104, 89, 26, 87, 60, 166, 13], [ 47, 46, 141, 5342, 1, 231, 40, 50, 141, 92], [ 19, 29, 41, 10, 5366, 9, 56, 37, 86, 189], [ 73, 45, 36, 193, 64, 4582, 111, 30, 193, 94], [ 29, 34, 44, 2, 42, 85, 5627, 10, 45, 0], [ 25, 24, 74, 32, 54, 12, 6, 5787, 15, 236], [ 52, 161, 73, 156, 10, 163, 61, 25, 5027, 123], [ 43, 35, 26, 92, 178, 28, 2, 223, 82, 5240]])
这里是一对数字。使用 Matplotlib 的matshow()函数,将混淆矩阵以图像的方式呈现,将会更加方便。
plt.matshow(conf_mx, cmap=plt.cm.gray) plt.show()
这个混淆矩阵看起来相当好,因为大多数的图片在主对角线上。在主对角线上意味着被分类正确。数字 5 对应的格子看起来比其他数字要暗淡许多。这可能是数据集当中数字 5 的图片比较少,又或者是分类器对于数字 5 的表现不如其他数字那么好。你可以验证两种情况。
让我们关注仅包含误差数据的图像呈现。首先你需要将混淆矩阵的每一个值除以相应类别的图片的总数目。这样子,你可以比较错误率,而不是绝对的错误数(这对大的类别不公平)。
row_sums = conf_mx.sum(axis=1, keepdims=True) norm_conf_mx = conf_mx / row_sums
现在让我们用 0 来填充对角线。这样子就只保留了被错误分类的数据。让我们画出这个结果。
np.fill_diagonal(norm_conf_mx, 0) plt.matshow(norm_conf_mx, cmap=plt.cm.gray) plt.show()
现在你可以清楚看出分类器制造出来的各类误差。记住:行代表实际类别,列代表预测的类别。第 8、9 列相当亮,这告诉你许多图片被误分成数字 8 或者数字 9。相似的,第 8、9 行也相当亮,告诉你数字 8、数字 9 经常被误以为是其他数字。相反,一些行相当黑,比如第一行:这意味着大部分的数字 1 被正确分类(一些被误分类为数字 8 )。留意到误差图不是严格对称的。举例子,比起将数字 8 误分类为数字 5 的数量,有更多的数字 5 被误分类为数字 8。
分析混淆矩阵通常可以给你提供深刻的见解去改善你的分类器。回顾这幅图,看样子你应该努力改善分类器在数字 8 和数字 9 上的表现,和纠正 3/5 的混淆。举例子,你可以尝试去收集更多的数据,或者你可以构造新的、有助于分类器的特征。举例子,写一个算法去数闭合的环(比如,数字 8 有两个环,数字 6 有一个, 5 没有)。又或者你可以预处理图片(比如,使用 Scikit-Learn,Pillow, OpenCV)去构造一个模式,比如闭合的环。
分析独特的误差,是获得关于你的分类器是如何工作及其为什么失败的洞见的一个好途径。但是这相对难和耗时。举例子,我们可以画出数字 3 和 5 的例子
cl_a, cl_b = 3, 5 X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)] X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)] X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)] X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)] plt.figure(figsize=(8,8)) plt.subplot(221); plot_digits(X_aa[:25], ../images_per_row=5) plt.subplot(222); plot_digits(X_ab[:25], ../images_per_row=5) plt.subplot(223); plot_digits(X_ba[:25], ../images_per_row=5) plt.subplot(224); plot_digits(X_bb[:25], ../images_per_row=5) plt.show()

左边两个5*5的块将数字识别为 3,右边的将数字识别为 5。一些被分类器错误分类的数字(比如左下角和右上角的块)是书写地相当差,甚至让人类分类都会觉得很困难(比如第 8 行第 1 列的数字 5,看起来非常像数字 3 )。但是,大部分被误分类的数字,在我们看来都是显而易见的错误。很难明白为什么分类器会分错。原因是我们使用的简单的SGDClassifier,这是一个线性模型。它所做的全部工作就是分配一个类权重给每一个像素,然后当它看到一张新的图片,它就将加权的像素强度相加,每个类得到一个新的值。所以,因为 3 和 5 只有一小部分的像素有差异,这个模型很容易混淆它们。
3 和 5 之间的主要差异是连接顶部的线和底部的线的细线的位置。如果你画一个 3,连接处稍微向左偏移,分类器很可能将它分类成 5。反之亦然。换一个说法,这个分类器对于图片的位移和旋转相当敏感。所以,减轻 3/5 混淆的一个方法是对图片进行预处理,确保它们都很好地中心化和不过度旋转。这同样很可能帮助减轻其他类型的错误。
多标签分类
到目前为止,所有的样例都总是被分配到仅一个类。有些情况下,你也许想让你的分类器给一个样例输出多个类别。比如说,思考一个人脸识别器。如果对于同一张图片,它识别出几个人,它应该做什么?当然它应该给每一个它识别出的人贴上一个标签。比方说,这个分类器被训练成识别三个人脸,Alice,Bob,Charlie;然后当它被输入一张含有 Alice 和 Bob 的图片,它应该输出[1, 0, 1](意思是:Alice 是,Bob 不是,Charlie 是)。这种输出多个二值标签的分类系统被叫做多标签分类系统。
目前我们不打算深入脸部识别。我们可以先看一个简单点的例子,仅仅是为了阐明的目的。
from sklearn.neighbors import KNeighborsClassifier y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel)
这段代码创造了一个y_multilabel数组,里面包含两个目标标签。第一个标签指出这个数字是否为大数字(7,8 或者 9),第二个标签指出这个数字是否是奇数。接下来几行代码会创建一个KNeighborsClassifier样例(它支持多标签分类,但不是所有分类器都可以),然后我们使用多目标数组来训练它。现在你可以生成一个预测,然后它输出两个标签:
>>> knn_clf.predict([some_digit]) array([[False, True]], dtype=bool)
它工作正确。数字 5 不是大数(False),同时是一个奇数(True)。
有许多方法去评估一个多标签分类器,和选择正确的量度标准,这取决于你的项目。举个例子,一个方法是对每个个体标签去量度 F1 值(或者前面讨论过的其他任意的二分类器的量度标准),然后计算平均值。下面的代码计算全部标签的平均 F1 值:
>>> y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3) >>> f1_score(y_train, y_train_knn_pred, average="macro") 0.96845540180280221
这里假设所有标签有着同等的重要性,但可能不是这样。特别是,如果你的 Alice 的照片比 Bob 或者 Charlie 更多的时候,也许你想让分类器在 Alice 的照片上具有更大的权重。一个简单的选项是:给每一个标签的权重等于它的支持度(比如,那个标签的样例的数目)。为了做到这点,简单地在上面代码中设置average="weighted"。
多输出分类
我们即将讨论的最后一种分类任务被叫做“多输出-多类分类”(或者简称为多输出分类)。它是多标签分类的简单泛化,在这里每一个标签可以是多类别的(比如说,它可以有多于两个可能值)。
为了说明这点,我们建立一个系统,它可以去除图片当中的噪音。它将一张混有噪音的图片作为输入,期待它输出一张干净的数字图片,用一个像素强度的数组表示,就像 MNIST 图片那样。注意到这个分类器的输出是多标签的(一个像素一个标签)和每个标签可以有多个值(像素强度取值范围从 0 到 255)。所以它是一个多输出分类系统的例子。
分类与回归之间的界限是模糊的,比如这个例子。按理说,预测一个像素的强度更类似于一个回归任务,而不是一个分类任务。而且,多输出系统不限于分类任务。你甚至可以让你一个系统给每一个样例都输出多个标签,包括类标签和值标签。
让我们从 MNIST 的图片创建训练集和测试集开始,然后给图片的像素强度添加噪声,这里是用 NumPy 的randint()函数。目标图像是原始图像。
noise = rnd.randint(0, 100, (len(X_train), 784)) noise = rnd.randint(0, 100, (len(X_test), 784)) X_train_mod = X_train + noise X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_test
让我们看一下测试集当中的一张图片(是的,我们在窥探测试集,所以你应该马上邹眉):
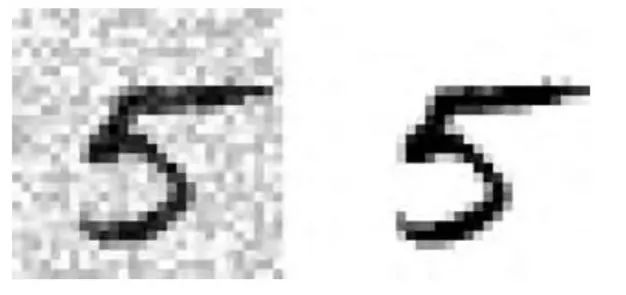
左边的加噪声的输入图片。右边是干净的目标图片。现在我们训练分类器,让它清洁这张图片:
knn_clf.fit(X_train_mod, y_train_mod) clean_digit = knn_clf.predict([X_test_mod[some_index]]) plot_digit(clean_digit)
看起来足够接近目标图片。现在总结我们的分类之旅。希望你现在应该知道如何选择好的量度标准,挑选出合适的准确率/召回率的折衷方案,比较分类器,更概括地说,就是为不同的任务建立起好的分类系统。
练习
尝试在 MNIST 数据集上建立一个分类器,使它在测试集上的精度超过 97%。提示:KNeighborsClassifier非常适合这个任务。你只需要找出一个好的超参数值(试一下对权重和超参数n_neighbors进行网格搜索)。
写一个函数可以是 MNIST 中的图像任意方向移动(上下左右)一个像素。然后,对训练集上的每张图片,复制四个移动后的副本(每个方向一个副本),把它们加到训练集当中去。最后在扩展后的训练集上训练你最好的模型,并且在测试集上测量它的精度。你应该会观察到你的模型会有更好的表现。这种人工扩大训练集的方法叫做数据增强,或者训练集扩张。
拿 Titanic 数据集去捣鼓一番。开始这个项目有一个很棒的平台:Kaggle!
建立一个垃圾邮件分类器(这是一个更有挑战性的练习):
下载垃圾邮件和非垃圾邮件的样例数据。地址是Apache SpamAssassin 的公共数据集
解压这些数据集,并且熟悉它的数据格式。
将数据集分成训练集和测试集
写一个数据准备的流水线,将每一封邮件转换为特征向量。你的流水线应该将一封邮件转换为一个稀疏向量,对于所有可能的词,这个向量标志哪个词出现了,哪个词没有出现。举例子,如果所有邮件只包含了"Hello","How","are", "you"这四个词,那么一封邮件(内容是:"Hello you Hello Hello you")将会被转换为向量[1, 0, 0, 1](意思是:"Hello"出现,"How"不出现,"are"不出现,"you"出现),或者[3, 0, 0, 2],如果你想数出每个单词出现的次数。
你也许想给你的流水线增加超参数,控制是否剥过邮件头、将邮件转换为小写、去除标点符号、将所有 URL 替换成"URL",将所有数字替换成"NUMBER",或者甚至提取词干(比如,截断词尾。有现成的 Python 库可以做到这点)。
然后 尝试几个不同的分类器,看看你可否建立一个很棒的垃圾邮件分类器,同时有着高召回率和高准确率。
- 相关推荐
- 热点推荐
- 机器学习
- 数据集
- tensorflow
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2232
-
如何使用Arm CMSIS-DSP实现经典机器学习库2023-08-02 1018
-
机器学习之分类分析与聚类分析2023-03-27 6924
-
机器学习之关联分析介绍2023-03-25 2888
-
机器学习的范围/算法/分类2021-01-21 4096
-
各类机器学习分类算法的优点与缺点分析2020-03-02 4358
-
关于机器学习的相关分析介绍2019-09-16 3357
-
关于机器学习PCA算法的主成分分析2018-06-27 3601
-
常用python机器学习库盘点2018-05-10 1972
-
机器学习实践指南——案例应用解析2018-04-13 2300
-
多标记学习的分类器圈方法2018-01-22 650
-
【下载】《机器学习》+《机器学习实战》2017-06-01 197523
-
误差的分类及特点2008-09-18 13884
全部0条评论

快来发表一下你的评论吧 !
